 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Secret Lives of Names? Name Embeddings from Social Media
May 12, 2019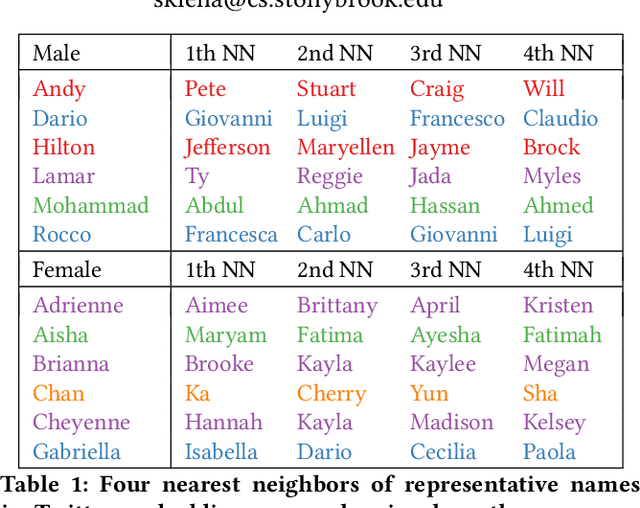
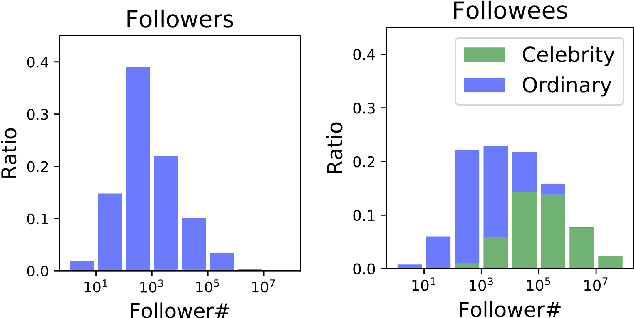

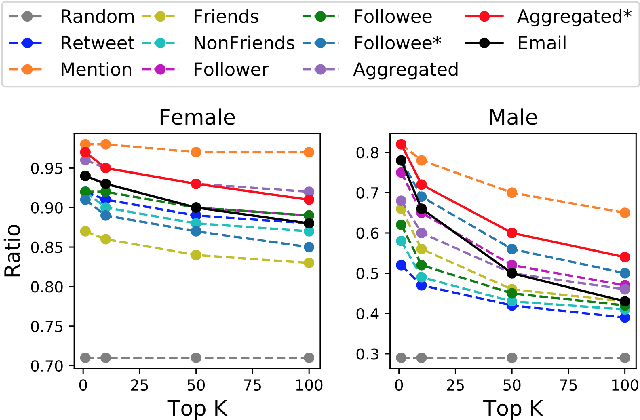
Your name tells a lot about you: your gender, ethnicity and so on. It has been shown that name embeddings are more effective in representing names than traditional substring features. However, our previous name embedding model is trained on private email data and are not publicly accessible. In this paper, we explore learning name embeddings from public Twitter data. We argue that Twitter embeddings have two key advantages: \textit{(i)} they can and will be publicly released to support research community. \textit{(ii)} even with a smaller training corpus, Twitter embeddings achieve similar performances on multiple tasks comparing to email embeddings. As a test case to show the power of name embeddings, we investigate the modeling of lifespans. We find it interesting that adding name embeddings can further improve the performances of models using demographic features, which are traditionally used for lifespan modeling. Through residual analysis, we observe that fine-grained groups (potentially reflecting socioeconomic status) are the latent contributing factors encoded in name embeddings. These were previously hidden to demographic models, and may help to enhance the predictive power of a wide class of research studies.
Multi-view Models for Political Ideology Detection of News Articles
Sep 10, 2018
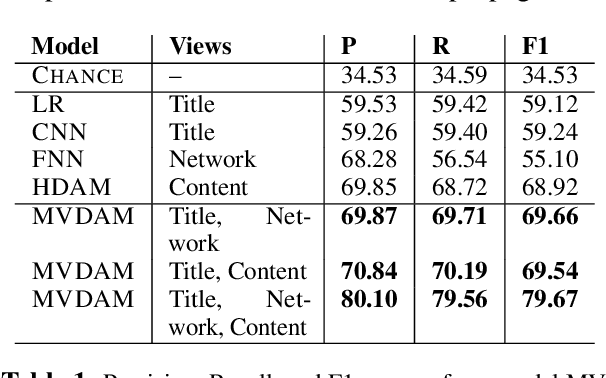
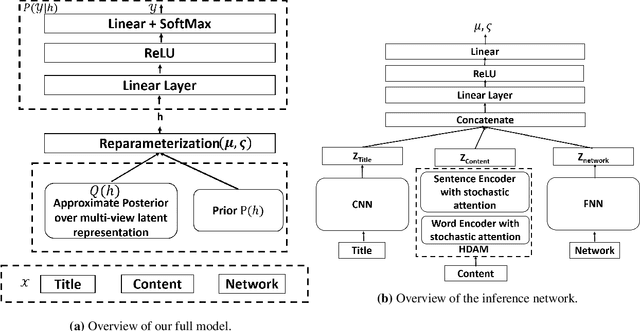

A news article's title, content and link structure often reveal its political ideology. However, most existing works on automatic political ideology detection only leverage textual cues. Drawing inspiration from recent advances in neural inference, we propose a novel attention based multi-view model to leverage cues from all of the above views to identify the ideology evinced by a news article. Our model draws on advances in representation learning in natural language processing and network science to capture cues from both textual content and the network structure of news articles. We empirically evaluate our model against a battery of baselines and show that our model outperforms state of the art by 10 percentage points F1 score.
Nationality Classification Using Name Embeddings
Aug 25, 2017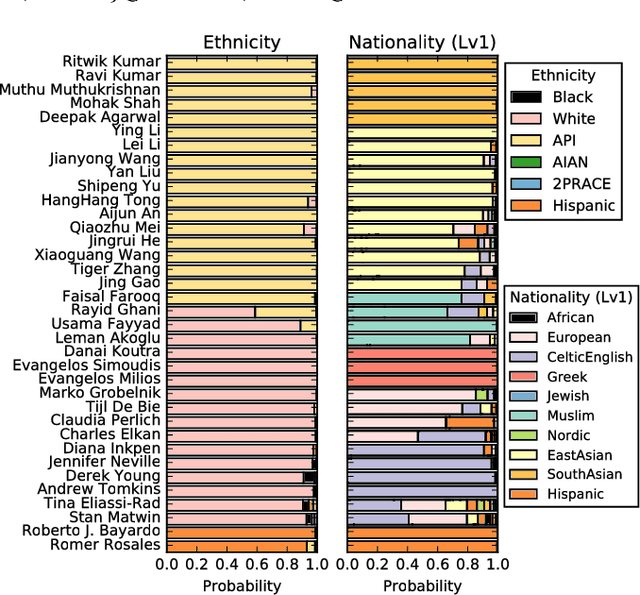


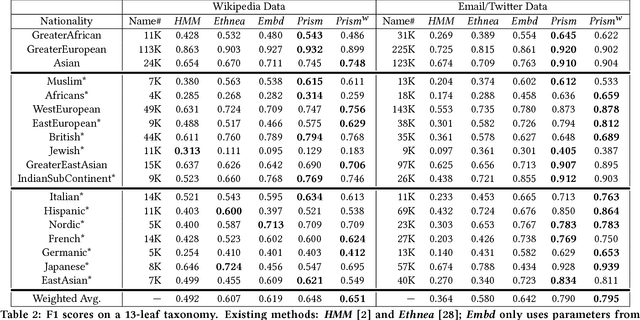
Nationality identification unlocks important demographic information, with many applications in biomedical and sociological research. Existing name-based nationality classifiers use name substrings as features and are trained on small, unrepresentative sets of labeled names, typically extracted from Wikipedia. As a result, these methods achieve limited performance and cannot support fine-grained classification. We exploit the phenomena of homophily in communication patterns to learn name embeddings, a new representation that encodes gender, ethnicity, and nationality which is readily applicable to building classifiers and other systems. Through our analysis of 57M contact lists from a major Internet company, we are able to design a fine-grained nationality classifier covering 39 groups representing over 90% of the world population. In an evaluation against other published systems over 13 common classes, our F1 score (0.795) is substantial better than our closest competitor Ethnea (0.580). To the best of our knowledge, this is the most accurate, fine-grained nationality classifier available. As a social media application, we apply our classifiers to the followers of major Twitter celebrities over six different domains. We demonstrate stark differences in the ethnicities of the followers of Trump and Obama, and in the sports and entertainments favored by different groups. Finally, we identify an anomalous political figure whose presumably inflated following appears largely incapable of reading the language he posts in.
Robust Semi-Supervised Classification for Multi-Relational Graphs
Oct 19, 2015

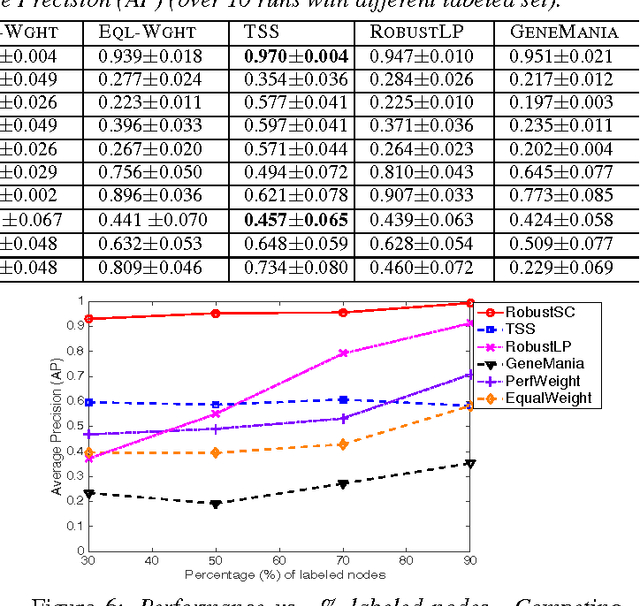
Graph-regularized semi-supervised learning has been used effectively for classification when (i) instances are connected through a graph, and (ii) labeled data is scarce. If available, using multiple relations (or graphs) between the instances can improve the prediction performance. On the other hand, when these relations have varying levels of veracity and exhibit varying relevance for the task, very noisy and/or irrelevant relations may deteriorate the performance. As a result, an effective weighing scheme needs to be put in place. In this work, we propose a robust and scalable approach for multi-relational graph-regularized semi-supervised classification. Under a convex optimization scheme, we simultaneously infer weights for the multiple graphs as well as a solution. We provide a careful analysis of the inferred weights, based on which we devise an algorithm that filters out irrelevant and noisy graphs and produces weights proportional to the informativeness of the remaining graphs. Moreover, the proposed method is linearly scalable w.r.t. the number of edges in the union of the multiple graphs. Through extensive experiments we show that our method yields superior results under different noise models, and under increasing number of noisy graphs and intensity of noise, as compared to a list of baselines and state-of-the-art approaches.