 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Context-Conditioned Anomaly Detection for Tabular Data
Sep 10, 2025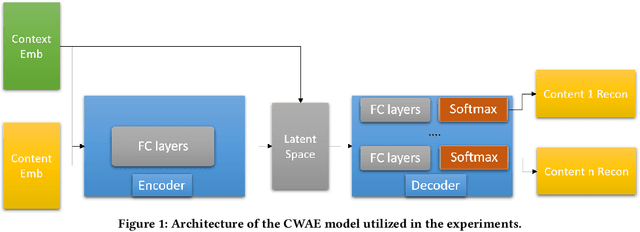
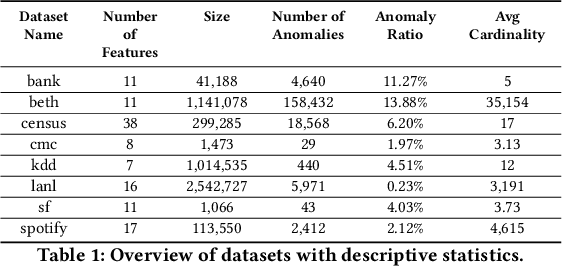
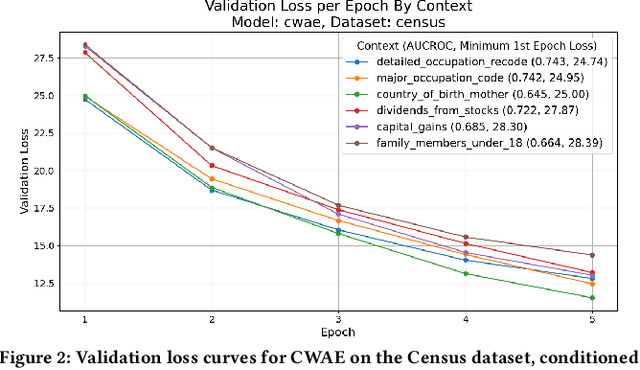
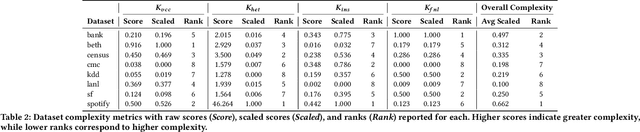
Anomaly detection is critical in domains such as cybersecurity and finance, especially when working with large-scale tabular data. Yet, unsupervised anomaly detection -- where no labeled anomalies are available -- remains a significant challenge. Although various deep learning methods have been proposed to model a dataset's joint distribution, real-world tabular data often contain heterogeneous contexts (e.g., different users), making globally rare events normal under certain contexts. Consequently, relying on a single global distribution can overlook these contextual nuances, degrading detection performance. In this paper, we present a context-conditional anomaly detection framework tailored for tabular datasets. Our approach automatically identifies context features and models the conditional data distribution using a simple deep autoencoder. Extensive experiments on multiple tabular benchmark datasets demonstrate that our method outperforms state-of-the-art approaches, underscoring the importance of context in accurately distinguishing anomalous from normal instances.
Firenze: Model Evaluation Using Weak Signals
Jul 02, 2022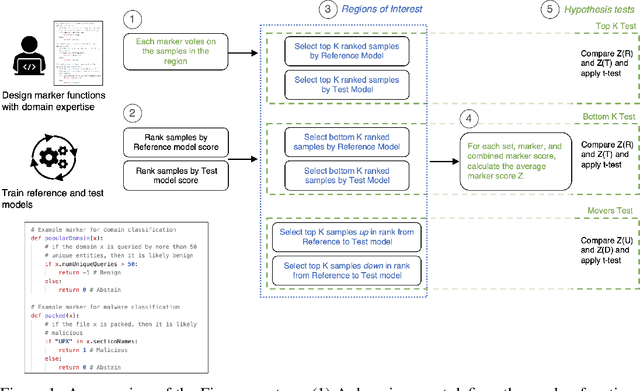
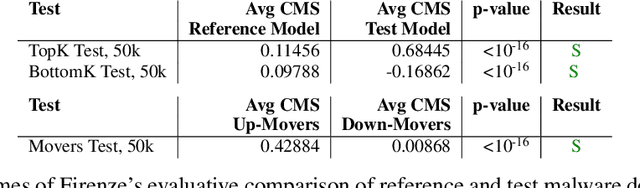
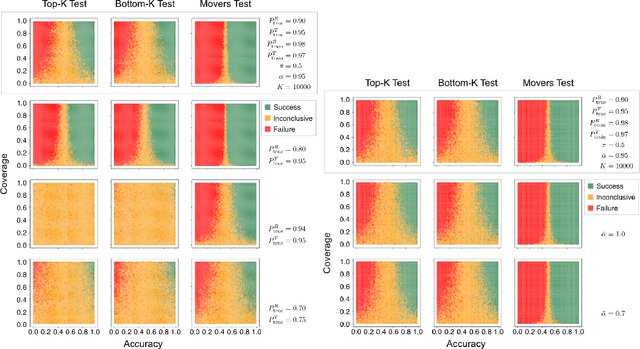
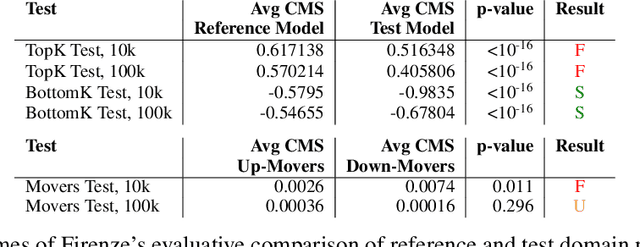
Data labels in the security field are frequently noisy, limited, or biased towards a subset of the population. As a result, commonplace evaluation methods such as accuracy, precision and recall metrics, or analysis of performance curves computed from labeled datasets do not provide sufficient confidence in the real-world performance of a machine learning (ML) model. This has slowed the adoption of machine learning in the field. In the industry today, we rely on domain expertise and lengthy manual evaluation to build this confidence before shipping a new model for security applications. In this paper, we introduce Firenze, a novel framework for comparative evaluation of ML models' performance using domain expertise, encoded into scalable functions called markers. We show that markers computed and combined over select subsets of samples called regions of interest can provide a robust estimate of their real-world performances. Critically, we use statistical hypothesis testing to ensure that observed differences-and therefore conclusions emerging from our framework-are more prominent than that observable from the noise alone. Using simulations and two real-world datasets for malware and domain-name-service reputation detection, we illustrate our approach's effectiveness, limitations, and insights. Taken together, we propose Firenze as a resource for fast, interpretable, and collaborative model development and evaluation by mixed teams of researchers, domain experts, and business owners.
Nationality Classification Using Name Embeddings
Aug 25, 2017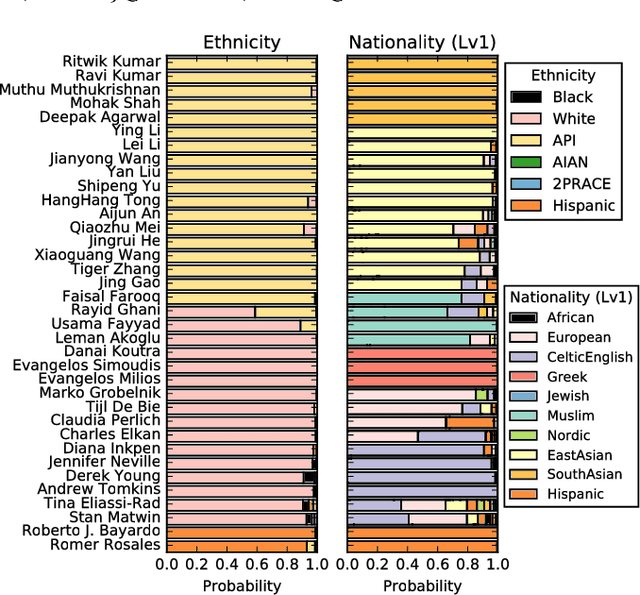


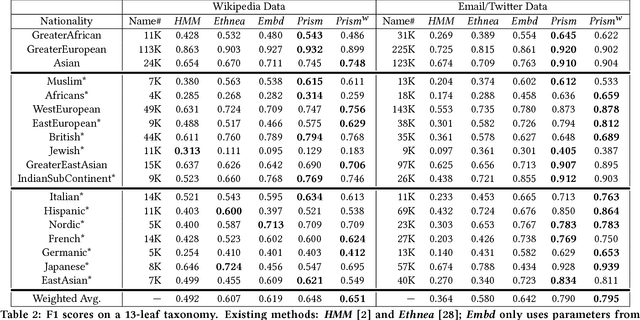
Nationality identification unlocks important demographic information, with many applications in biomedical and sociological research. Existing name-based nationality classifiers use name substrings as features and are trained on small, unrepresentative sets of labeled names, typically extracted from Wikipedia. As a result, these methods achieve limited performance and cannot support fine-grained classification. We exploit the phenomena of homophily in communication patterns to learn name embeddings, a new representation that encodes gender, ethnicity, and nationality which is readily applicable to building classifiers and other systems. Through our analysis of 57M contact lists from a major Internet company, we are able to design a fine-grained nationality classifier covering 39 groups representing over 90% of the world population. In an evaluation against other published systems over 13 common classes, our F1 score (0.795) is substantial better than our closest competitor Ethnea (0.580). To the best of our knowledge, this is the most accurate, fine-grained nationality classifier available. As a social media application, we apply our classifiers to the followers of major Twitter celebrities over six different domains. We demonstrate stark differences in the ethnicities of the followers of Trump and Obama, and in the sports and entertainments favored by different groups. Finally, we identify an anomalous political figure whose presumably inflated following appears largely incapable of reading the language he posts in.