 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttn-GS: Attention-Guided Context Compression for Efficient Personalized LLMs
Feb 08, 2026Personalizing large language models (LLMs) to individual users requires incorporating extensive interaction histories and profiles, but input token constraints make this impractical due to high inference latency and API costs. Existing approaches rely on heuristic methods such as selecting recent interactions or prompting summarization models to compress user profiles. However, these methods treat context as a monolithic whole and fail to consider how LLMs internally process and prioritize different profile components. We investigate whether LLMs' attention patterns can effectively identify important personalization signals for intelligent context compression. Through preliminary studies on representative personalization tasks, we discover that (a) LLMs' attention patterns naturally reveal important signals, and (b) fine-tuning enhances LLMs' ability to distinguish between relevant and irrelevant information. Based on these insights, we propose Attn-GS, an attention-guided context compression framework that leverages attention feedback from a marking model to mark important personalization sentences, then guides a compression model to generate task-relevant, high-quality compressed user contexts. Extensive experiments demonstrate that Attn-GS significantly outperforms various baselines across different tasks, token limits, and settings, achieving performance close to using full context while reducing token usage by 50 times.
SCORE: Syntactic Code Representations for Static Script Malware Detection
Nov 12, 2024As businesses increasingly adopt cloud technologies, they also need to be aware of new security challenges, such as server-side script attacks, to ensure the integrity of their systems and data. These scripts can steal data, compromise credentials, and disrupt operations. Unlike executables with standardized formats (e.g., ELF, PE), scripts are plaintext files with diverse syntax, making them harder to detect using traditional methods. As a result, more sophisticated approaches are needed to protect cloud infrastructures from these evolving threats. In this paper, we propose novel feature extraction and deep learning (DL)-based approaches for static script malware detection, targeting server-side threats. We extract features from plain-text code using two techniques: syntactic code highlighting (SCH) and abstract syntax tree (AST) construction. SCH leverages complex regexes to parse syntactic elements of code, such as keywords, variable names, etc. ASTs generate a hierarchical representation of a program's syntactic structure. We then propose a sequential and a graph-based model that exploits these feature representations to detect script malware. We evaluate our approach on more than 400K server-side scripts in Bash, Python and Perl. We use a balanced dataset of 90K scripts for training, validation, and testing, with the remaining from 400K reserved for further analysis. Experiments show that our method achieves a true positive rate (TPR) up to 81% higher than leading signature-based antivirus solutions, while maintaining a low false positive rate (FPR) of 0.17%. Moreover, our approach outperforms various neural network-based detectors, demonstrating its effectiveness in learning code maliciousness for accurate detection of script malware.
Firenze: Model Evaluation Using Weak Signals
Jul 02, 2022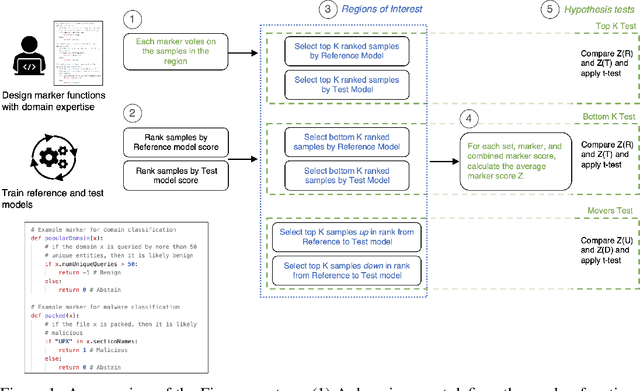
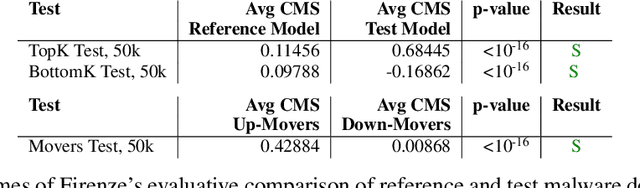
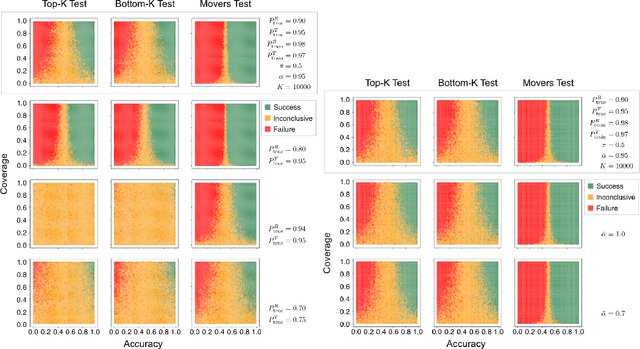
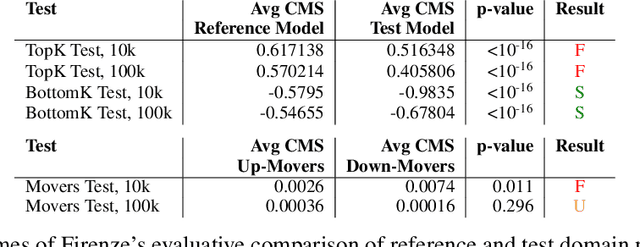
Data labels in the security field are frequently noisy, limited, or biased towards a subset of the population. As a result, commonplace evaluation methods such as accuracy, precision and recall metrics, or analysis of performance curves computed from labeled datasets do not provide sufficient confidence in the real-world performance of a machine learning (ML) model. This has slowed the adoption of machine learning in the field. In the industry today, we rely on domain expertise and lengthy manual evaluation to build this confidence before shipping a new model for security applications. In this paper, we introduce Firenze, a novel framework for comparative evaluation of ML models' performance using domain expertise, encoded into scalable functions called markers. We show that markers computed and combined over select subsets of samples called regions of interest can provide a robust estimate of their real-world performances. Critically, we use statistical hypothesis testing to ensure that observed differences-and therefore conclusions emerging from our framework-are more prominent than that observable from the noise alone. Using simulations and two real-world datasets for malware and domain-name-service reputation detection, we illustrate our approach's effectiveness, limitations, and insights. Taken together, we propose Firenze as a resource for fast, interpretable, and collaborative model development and evaluation by mixed teams of researchers, domain experts, and business owners.
Loss-calibrated expectation propagation for approximate Bayesian decision-making
Jan 10, 2022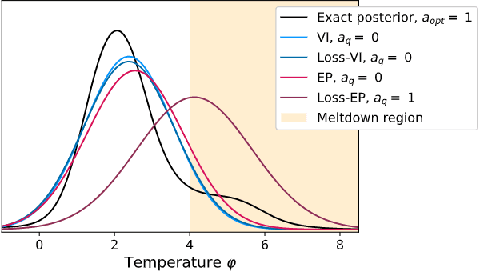
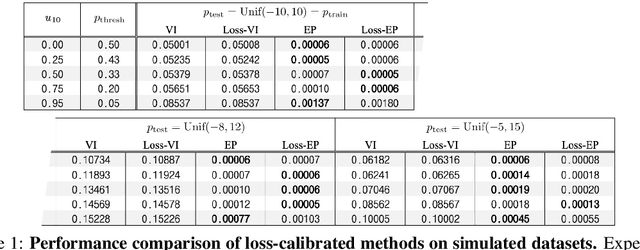
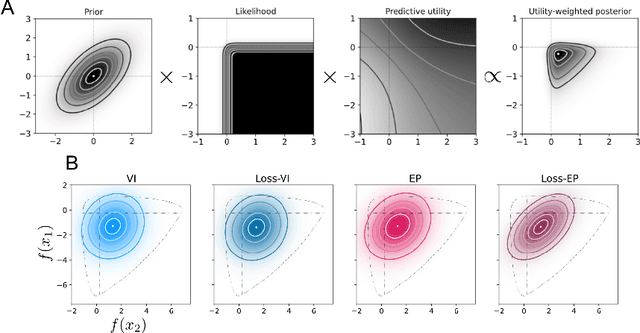
Approximate Bayesian inference methods provide a powerful suite of tools for finding approximations to intractable posterior distributions. However, machine learning applications typically involve selecting actions, which -- in a Bayesian setting -- depend on the posterior distribution only via its contribution to expected utility. A growing body of work on loss-calibrated approximate inference methods has therefore sought to develop posterior approximations sensitive to the influence of the utility function. Here we introduce loss-calibrated expectation propagation (Loss-EP), a loss-calibrated variant of expectation propagation. This method resembles standard EP with an additional factor that "tilts" the posterior towards higher-utility decisions. We show applications to Gaussian process classification under binary utility functions with asymmetric penalties on False Negative and False Positive errors, and show how this asymmetry can have dramatic consequences on what information is "useful" to capture in an approximation.