 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Joint Source Channel Coding for Secure End-to-End Image Transmission
Dec 22, 2024Deep neural network (DNN)-based joint source and channel coding is proposed for end-to-end secure image transmission against multiple eavesdroppers. Both scenarios of colluding and non-colluding eavesdroppers are considered. Instead of idealistic assumptions of perfectly known and i.i.d. source and channel distributions, the proposed scheme assumes unknown source and channel statistics. The goal is to transmit images with minimum distortion, while simultaneously preventing eavesdroppers from inferring private attributes of images. Simultaneously generalizing the ideas of privacy funnel and wiretap coding, a multi-objective optimization framework is expressed that characterizes the trade-off between image reconstruction quality and information leakage to eavesdroppers, taking into account the structural similarity index (SSIM) for improving the perceptual quality of image reconstruction. Extensive experiments over CIFAR-10 and CelebFaces Attributes (CelebA) datasets, together with ablation studies are provided to highlight the performance gain in terms of SSIM, adversarial accuracy, and cross-entropy metric compared with benchmarks. Experiments show that the proposed scheme restrains the adversarially-trained eavesdroppers from intercepting privatized data for both cases of eavesdropping a common secret, as well as the case in which eavesdroppers are interested in different secrets. Furthermore, useful insights on the privacy-utility trade-off are also provided.
SCORE: Syntactic Code Representations for Static Script Malware Detection
Nov 12, 2024As businesses increasingly adopt cloud technologies, they also need to be aware of new security challenges, such as server-side script attacks, to ensure the integrity of their systems and data. These scripts can steal data, compromise credentials, and disrupt operations. Unlike executables with standardized formats (e.g., ELF, PE), scripts are plaintext files with diverse syntax, making them harder to detect using traditional methods. As a result, more sophisticated approaches are needed to protect cloud infrastructures from these evolving threats. In this paper, we propose novel feature extraction and deep learning (DL)-based approaches for static script malware detection, targeting server-side threats. We extract features from plain-text code using two techniques: syntactic code highlighting (SCH) and abstract syntax tree (AST) construction. SCH leverages complex regexes to parse syntactic elements of code, such as keywords, variable names, etc. ASTs generate a hierarchical representation of a program's syntactic structure. We then propose a sequential and a graph-based model that exploits these feature representations to detect script malware. We evaluate our approach on more than 400K server-side scripts in Bash, Python and Perl. We use a balanced dataset of 90K scripts for training, validation, and testing, with the remaining from 400K reserved for further analysis. Experiments show that our method achieves a true positive rate (TPR) up to 81% higher than leading signature-based antivirus solutions, while maintaining a low false positive rate (FPR) of 0.17%. Moreover, our approach outperforms various neural network-based detectors, demonstrating its effectiveness in learning code maliciousness for accurate detection of script malware.
Secure Deep-JSCC Against Multiple Eavesdroppers
Aug 05, 2023In this paper, a generalization of deep learning-aided joint source channel coding (Deep-JSCC) approach to secure communications is studied. We propose an end-to-end (E2E) learning-based approach for secure communication against multiple eavesdroppers over complex-valued fading channels. Both scenarios of colluding and non-colluding eavesdroppers are studied. For the colluding strategy, eavesdroppers share their logits to collaboratively infer private attributes based on ensemble learning method, while for the non-colluding setup they act alone. The goal is to prevent eavesdroppers from inferring private (sensitive) information about the transmitted images, while delivering the images to a legitimate receiver with minimum distortion. By generalizing the ideas of privacy funnel and wiretap channel coding, the trade-off between the image recovery at the legitimate node and the information leakage to the eavesdroppers is characterized. To solve this secrecy funnel framework, we implement deep neural networks (DNNs) to realize a data-driven secure communication scheme, without relying on a specific data distribution. Simulations over CIFAR-10 dataset verifies the secrecy-utility trade-off. Adversarial accuracy of eavesdroppers are also studied over Rayleigh fading, Nakagami-m, and AWGN channels to verify the generalization of the proposed scheme. Our experiments show that employing the proposed secure neural encoding can decrease the adversarial accuracy by 28%.
Generative Joint Source-Channel Coding for Semantic Image Transmission
Nov 24, 2022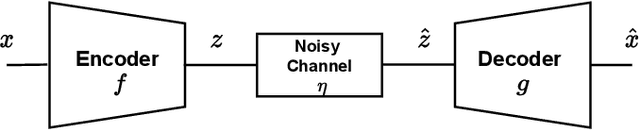
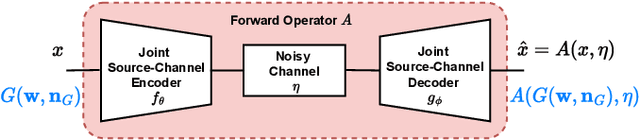
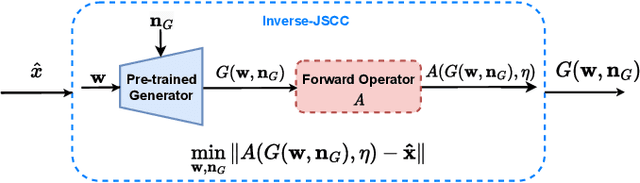
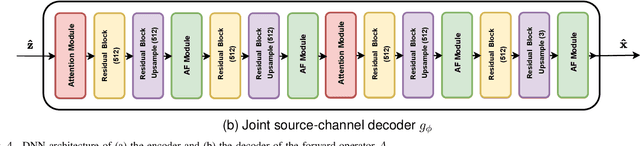
Recent works have shown that joint source-channel coding (JSCC) schemes using deep neural networks (DNNs), called DeepJSCC, provide promising results in wireless image transmission. However, these methods mostly focus on the distortion of the reconstructed signals with respect to the input image, rather than their perception by humans. However, focusing on traditional distortion metrics alone does not necessarily result in high perceptual quality, especially in extreme physical conditions, such as very low bandwidth compression ratio (BCR) and low signal-to-noise ratio (SNR) regimes. In this work, we propose two novel JSCC schemes that leverage the perceptual quality of deep generative models (DGMs) for wireless image transmission, namely InverseJSCC and GenerativeJSCC. While the former is an inverse problem approach to DeepJSCC, the latter is an end-to-end optimized JSCC scheme. In both, we optimize a weighted sum of mean squared error (MSE) and learned perceptual image patch similarity (LPIPS) losses, which capture more semantic similarities than other distortion metrics. InverseJSCC performs denoising on the distorted reconstructions of a DeepJSCC model by solving an inverse optimization problem using style-based generative adversarial network (StyleGAN). Our simulation results show that InverseJSCC significantly improves the state-of-the-art (SotA) DeepJSCC in terms of perceptual quality in edge cases. In GenerativeJSCC, we carry out end-to-end training of an encoder and a StyleGAN-based decoder, and show that GenerativeJSCC significantly outperforms DeepJSCC both in terms of distortion and perceptual quality.
Active Privacy-Utility Trade-off Against Inference in Time-Series Data Sharing
Feb 11, 2022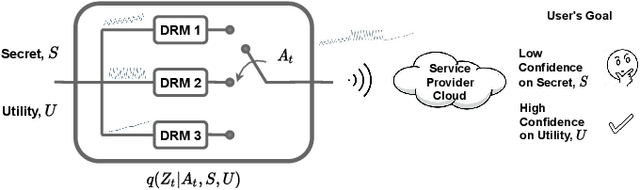
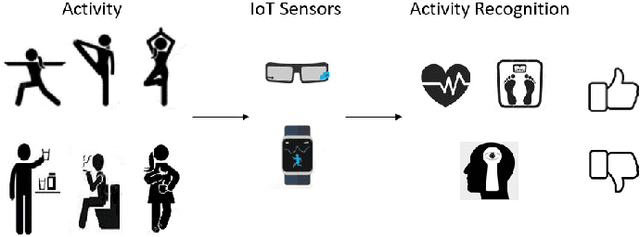
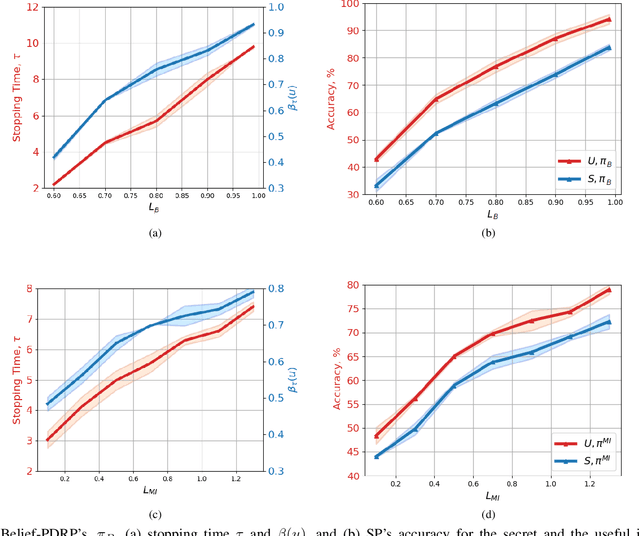
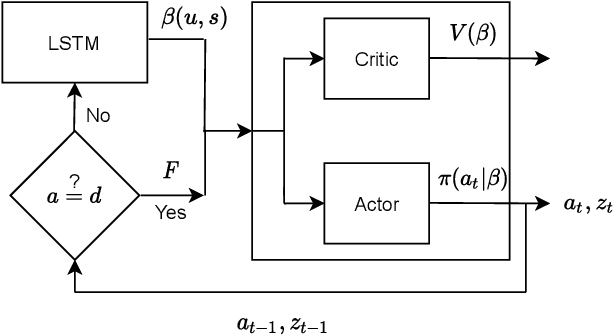
Internet of things (IoT) devices, such as smart meters, smart speakers and activity monitors, have become highly popular thanks to the services they offer. However, in addition to their many benefits, they raise privacy concerns since they share fine-grained time-series user data with untrusted third parties. In this work, we consider a user releasing her data containing personal information in return of a service from an honest-but-curious service provider (SP). We model user's personal information as two correlated random variables (r.v.'s), one of them, called the secret variable, is to be kept private, while the other, called the useful variable, is to be disclosed for utility. We consider active sequential data release, where at each time step the user chooses from among a finite set of release mechanisms, each revealing some information about the user's personal information, i.e., the true values of the r.v.'s, albeit with different statistics. The user manages data release in an online fashion such that the maximum amount of information is revealed about the latent useful variable as quickly as possible, while the confidence for the sensitive variable is kept below a predefined level. For privacy measure, we consider both the probability of correctly detecting the true value of the secret and the mutual information (MI) between the secret and the released data. We formulate both problems as partially observable Markov decision processes (POMDPs), and numerically solve them by advantage actor-critic (A2C) deep reinforcement learning (DRL). We evaluate the privacy-utility trade-off (PUT) of the proposed policies on both the synthetic data and smoking activity dataset, and show their validity by testing the activity detection accuracy of the SP modeled by a long short-term memory (LSTM) neural network.
Privacy-Aware Communication Over the Wiretap Channel with Generative Networks
Oct 08, 2021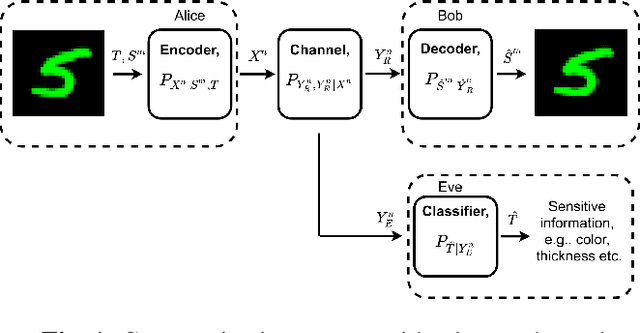
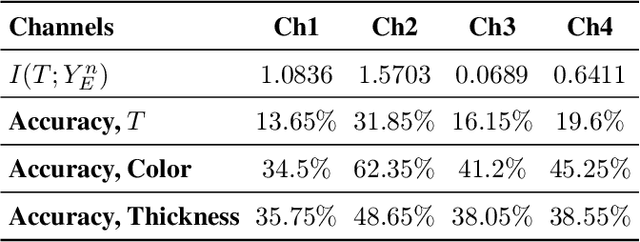
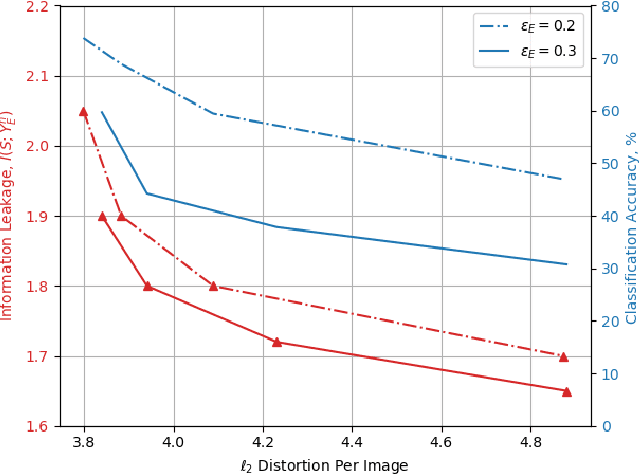

We study privacy-aware communication over a wiretap channel using end-to-end learning. Alice wants to transmit a source signal to Bob over a binary symmetric channel, while passive eavesdropper Eve tries to infer some sensitive attribute of Alice's source based on its overheard signal. Since we usually do not have access to true distributions, we propose a data-driven approach using variational autoencoder (VAE)-based joint source channel coding (JSCC). We show through simulations with the colored MNIST dataset that our approach provides high reconstruction quality at the receiver while confusing the eavesdropper about the latent sensitive attribute, which consists of the color and thickness of the digits. Finally, we consider a parallel-channel scenario, and show that our approach arranges the information transmission such that the channels with higher noise levels at the eavesdropper carry the sensitive information, while the non-sensitive information is transmitted over more vulnerable channels.
Adversarial Robustness with Non-uniform Perturbations
Feb 24, 2021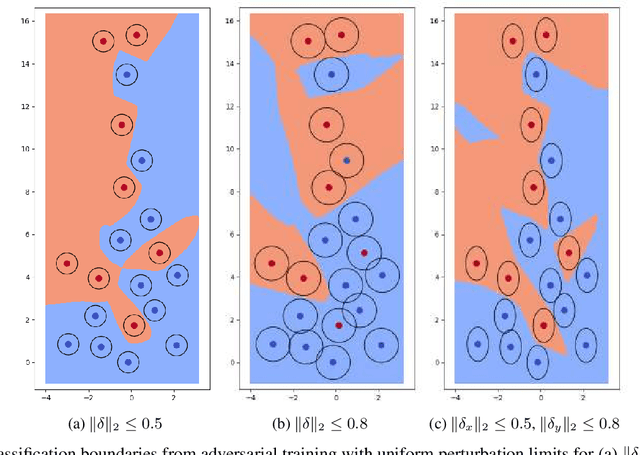
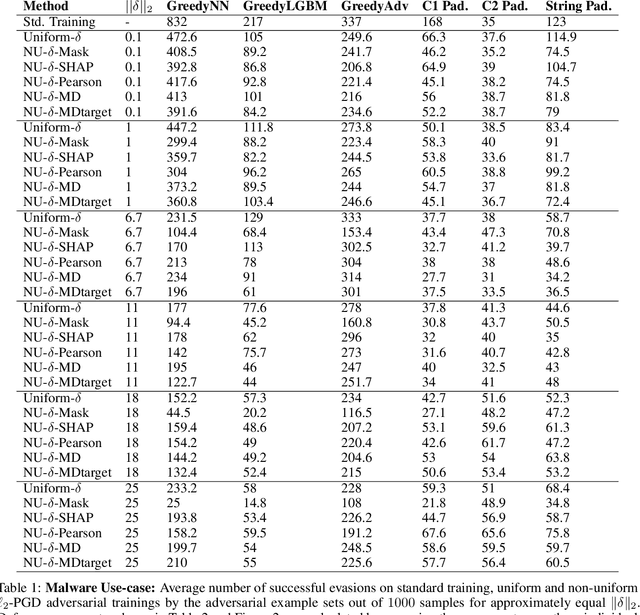
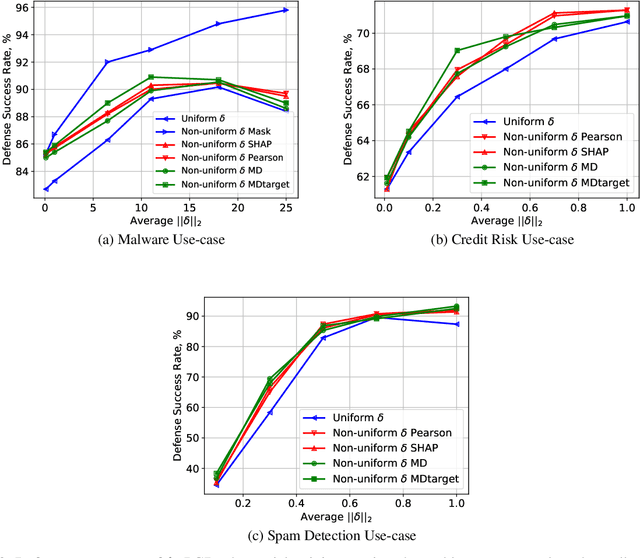
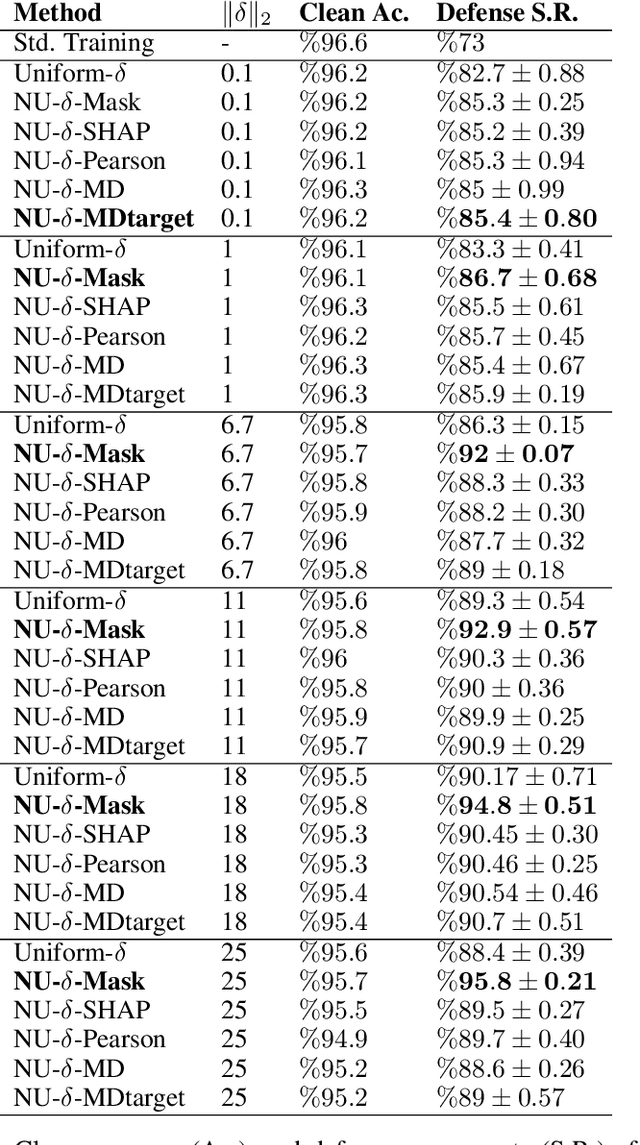
Robustness of machine learning models is critical for security related applications, where real-world adversaries are uniquely focused on evading neural network based detectors. Prior work mainly focus on crafting adversarial examples with small uniform norm-bounded perturbations across features to maintain the requirement of imperceptibility. Although such approaches are valid for images, uniform perturbations do not result in realistic adversarial examples in domains such as malware, finance, and social networks. For these types of applications, features typically have some semantically meaningful dependencies. The key idea of our proposed approach is to enable non-uniform perturbations that can adequately represent these feature dependencies during adversarial training. We propose using characteristics of the empirical data distribution, both on correlations between the features and the importance of the features themselves. Using experimental datasets for malware classification, credit risk prediction, and spam detection, we show that our approach is more robust to real-world attacks. Our approach can be adapted to other domains where non-uniform perturbations more accurately represent realistic adversarial examples.
Active Privacy-utility Trade-off Against a Hypothesis Testing Adversary
Feb 18, 2021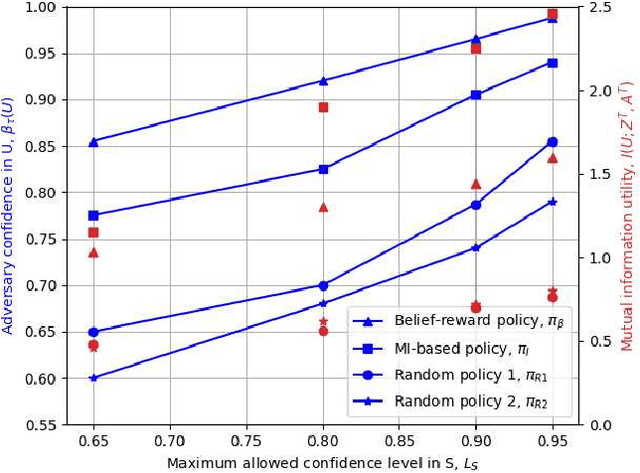
We consider a user releasing her data containing some personal information in return of a service. We model user's personal information as two correlated random variables, one of them, called the secret variable, is to be kept private, while the other, called the useful variable, is to be disclosed for utility. We consider active sequential data release, where at each time step the user chooses from among a finite set of release mechanisms, each revealing some information about the user's personal information, i.e., the true hypotheses, albeit with different statistics. The user manages data release in an online fashion such that maximum amount of information is revealed about the latent useful variable, while the confidence for the sensitive variable is kept below a predefined level. For the utility, we consider both the probability of correct detection of the useful variable and the mutual information (MI) between the useful variable and released data. We formulate both problems as a Markov decision process (MDP), and numerically solve them by advantage actor-critic (A2C) deep reinforcement learning (RL).
Privacy-Aware Time-Series Data Sharing with Deep Reinforcement Learning
Mar 04, 2020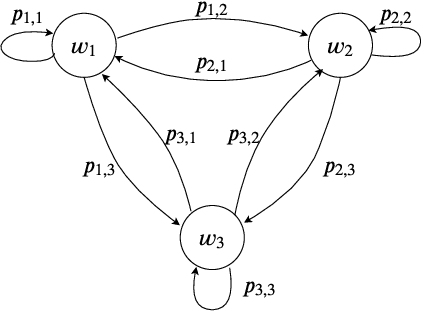
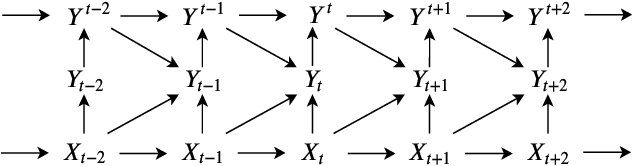
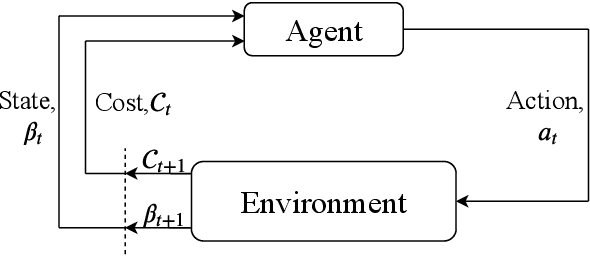
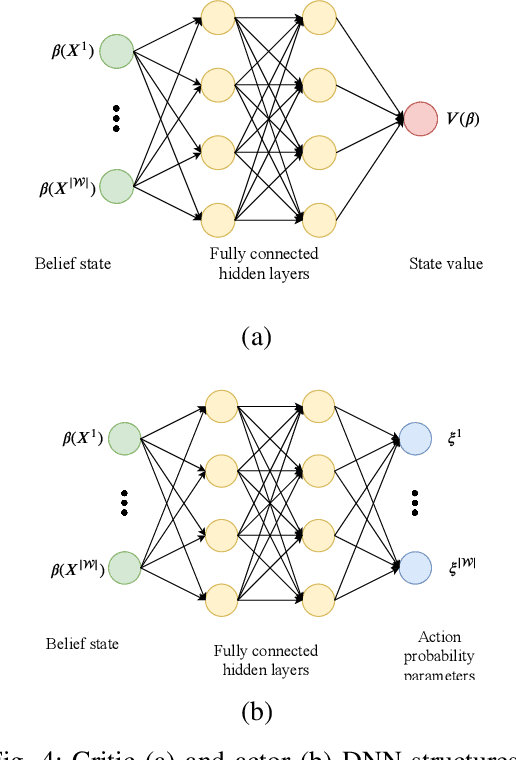
Internet of things (IoT) devices are becoming increasingly popular thanks to many new services and applications they offer. However, in addition to their many benefits, they raise privacy concerns since they share fine-grained time-series user data with untrusted third parties. In this work, we study the privacy-utility trade-off (PUT) in time-series data sharing. Existing approaches to PUT mainly focus on a single data point; however, temporal correlations in time-series data introduce new challenges. Methods that preserve the privacy for the current time may leak significant amount of information at the trace level as the adversary can exploit temporal correlations in a trace. We consider sharing the distorted version of a user's true data sequence with an untrusted third party. We measure the privacy leakage by the mutual information between the user's true data sequence and shared version. We consider both instantaneous and average distortion between the two sequences, under a given distortion measure, as the utility loss metric. To tackle the history-dependent mutual information minimization, we reformulate the problem as a Markov decision process (MDP), and solve it using asynchronous actor-critic deep reinforcement learning (RL). We apply our optimal data release policies to location trace privacy scenario, and evaluate the performance of the proposed policy numerically.