 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Source-Channel Coding: Fundamentals and Recent Progress in Practical Designs
Sep 26, 2024


Semantic- and task-oriented communication has emerged as a promising approach to reducing the latency and bandwidth requirements of next-generation mobile networks by transmitting only the most relevant information needed to complete a specific task at the receiver. This is particularly advantageous for machine-oriented communication of high data rate content, such as images and videos, where the goal is rapid and accurate inference, rather than perfect signal reconstruction. While semantic- and task-oriented compression can be implemented in conventional communication systems, joint source-channel coding (JSCC) offers an alternative end-to-end approach by optimizing compression and channel coding together, or even directly mapping the source signal to the modulated waveform. Although all digital communication systems today rely on separation, thanks to its modularity, JSCC is known to achieve higher performance in finite blocklength scenarios, and to avoid cliff and the levelling-off effects in time-varying channel scenarios. This article provides an overview of the information theoretic foundations of JSCC, surveys practical JSCC designs over the decades, and discusses the reasons for their limited adoption in practical systems. We then examine the recent resurgence of JSCC, driven by the integration of deep learning techniques, particularly through DeepJSCC, highlighting its many surprising advantages in various scenarios. Finally, we discuss why it may be time to reconsider today's strictly separate architectures, and reintroduce JSCC to enable high-fidelity, low-latency communications in critical applications such as autonomous driving, drone surveillance, or wearable systems.
Multi-level Reliability Interface for Semantic Communications over Wireless Networks
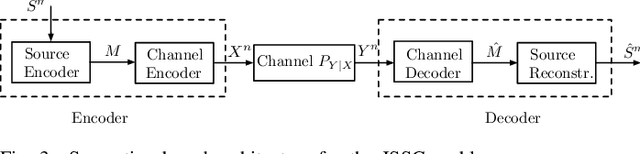
Jul 07, 2024Semantic communication, when examined through the lens of joint source-channel coding (JSCC), maps source messages directly into channel input symbols, where the measure of success is defined by end-to-end distortion rather than traditional metrics such as block error rate. Previous studies have shown significant improvements achieved through deep learning (DL)-driven JSCC compared to traditional separate source and channel coding. However, JSCC is impractical in existing communication networks, where application and network providers are typically different entities connected over general-purpose TCP/IP links. In this paper, we propose designing the source and channel mappings separately and sequentially via a novel multi-level reliability interface. This conceptual interface enables semi-JSCC at both the learned source and channel mappers and achieves many of the gains observed in existing DL-based JSCC work (which would require a fully joint design between the application and the network), such as lower end-to-end distortion and graceful degradation of distortion with channel quality. We believe this work represents an important step towards realizing semantic communications in wireless networks.
Deep Joint Source-Channel Coding for Semantic Communications
Dec 05, 2022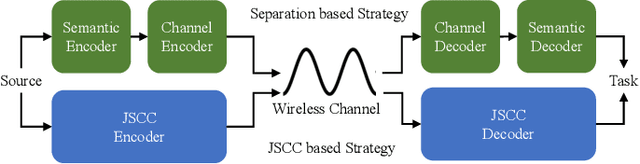
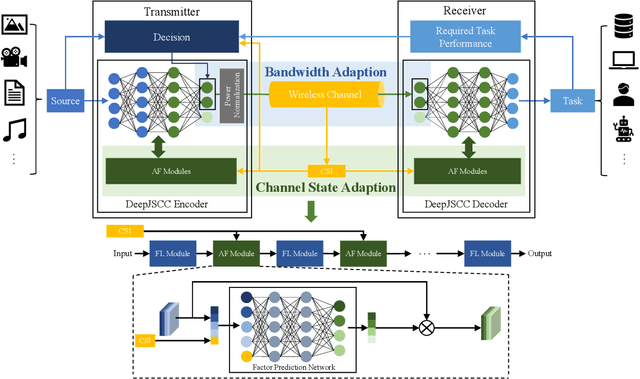
Semantic communications is considered as a promising technology for reducing the bandwidth requirements of next-generation communication systems, particularly targeting human-machine interactions. In contrast to the source-agnostic approach of conventional wireless communication systems, semantic communication seeks to ensure that only the relevant information for the underlying task is communicated to the receiver. A prominent approach to semantic communications is to model it as a joint source-channel coding (JSCC) problem. Although JSCC has been a long-standing open problem in communication and coding theory, remarkable performance gains have been shown recently over existing separate source and channel coding systems, particularly in low-latency and low-power scenarios, typically encountered in edge intelligence applications. Recent progress is thanks to the adoption of deep learning techniques for JSCC code design, which are shown to outperform the concatenation of state-of-the-art compression and channel coding schemes, each of which is a result of decades-long research efforts. In this article, we present an adaptive deep learning based JSCC (DeepJSCC) architecture for semantic communications, introduce its design principles, highlight its benefits, and outline future research challenges that lie ahead.
Generative Joint Source-Channel Coding for Semantic Image Transmission
Nov 24, 2022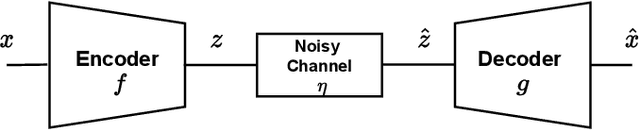
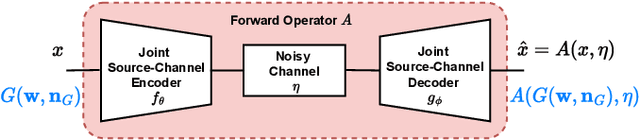
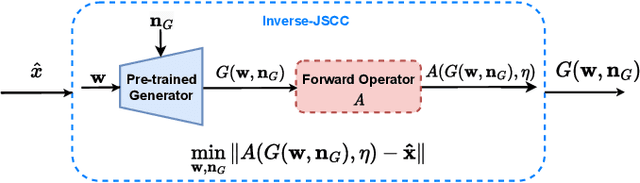
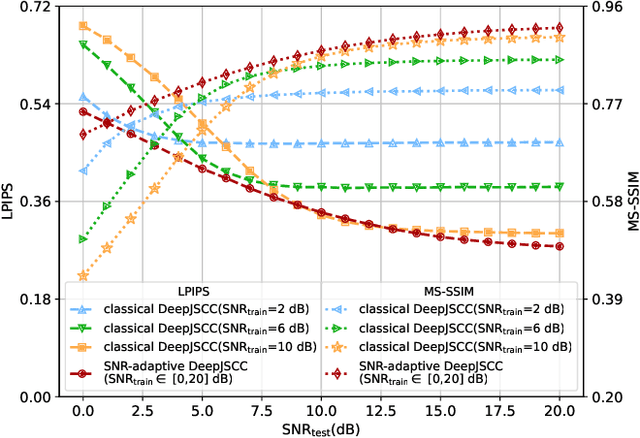
Recent works have shown that joint source-channel coding (JSCC) schemes using deep neural networks (DNNs), called DeepJSCC, provide promising results in wireless image transmission. However, these methods mostly focus on the distortion of the reconstructed signals with respect to the input image, rather than their perception by humans. However, focusing on traditional distortion metrics alone does not necessarily result in high perceptual quality, especially in extreme physical conditions, such as very low bandwidth compression ratio (BCR) and low signal-to-noise ratio (SNR) regimes. In this work, we propose two novel JSCC schemes that leverage the perceptual quality of deep generative models (DGMs) for wireless image transmission, namely InverseJSCC and GenerativeJSCC. While the former is an inverse problem approach to DeepJSCC, the latter is an end-to-end optimized JSCC scheme. In both, we optimize a weighted sum of mean squared error (MSE) and learned perceptual image patch similarity (LPIPS) losses, which capture more semantic similarities than other distortion metrics. InverseJSCC performs denoising on the distorted reconstructions of a DeepJSCC model by solving an inverse optimization problem using style-based generative adversarial network (StyleGAN). Our simulation results show that InverseJSCC significantly improves the state-of-the-art (SotA) DeepJSCC in terms of perceptual quality in edge cases. In GenerativeJSCC, we carry out end-to-end training of an encoder and a StyleGAN-based decoder, and show that GenerativeJSCC significantly outperforms DeepJSCC both in terms of distortion and perceptual quality.
Deep Joint Source-Channel and Encryption Coding: Secure Semantic Communications
Aug 31, 2022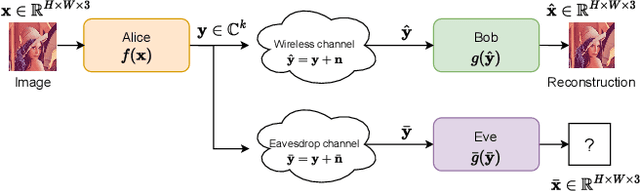
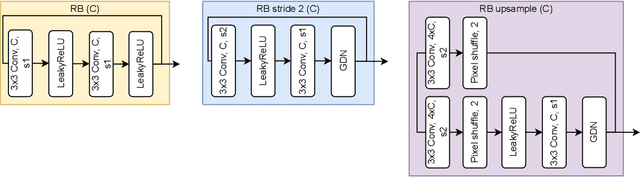
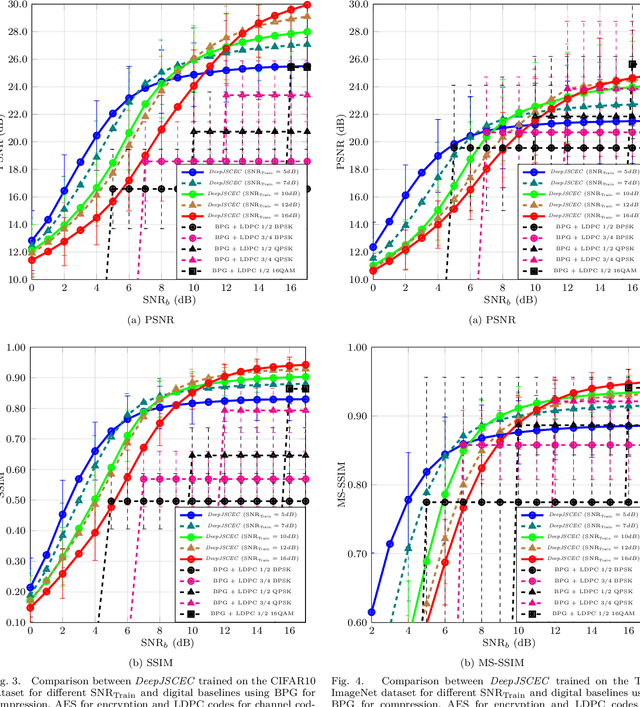
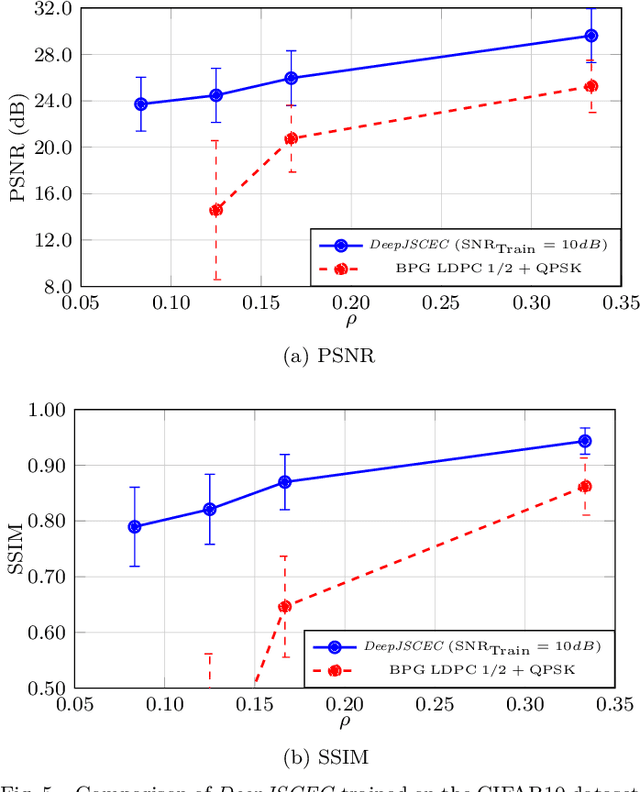
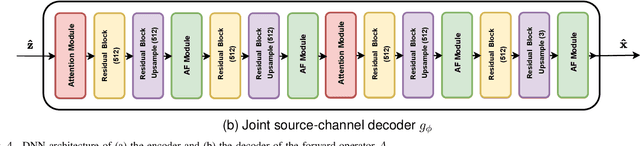
Deep learning driven joint source-channel coding (JSCC) for wireless image or video transmission, also called DeepJSCC, has been a topic of interest recently with very promising results. The idea is to map similar source samples to nearby points in the channel input space such that, despite the noise introduced by the channel, the input can be recovered with minimal distortion. In DeepJSCC, this is achieved by an autoencoder architecture with a non-trainable channel layer between the encoder and decoder. DeepJSCC has many favorable properties, such as better end-to-end distortion performance than its separate source and channel coding counterpart as well as graceful degradation with respect to channel quality. However, due to the inherent correlation between the source sample and channel input, DeepJSCC is vulnerable to eavesdropping attacks. In this paper, we propose the first DeepJSCC scheme for wireless image transmission that is secure against eavesdroppers, called DeepJSCEC. DeepJSCEC not only preserves the favorable properties of DeepJSCC, it also provides security against chosen-plaintext attacks from the eavesdropper, without the need to make assumptions about the eavesdropper's channel condition, or its intended use of the intercepted signal. Numerical results show that DeepJSCEC achieves similar or better image quality than separate source coding using BPG compression, AES encryption, and LDPC codes for channel coding, while preserving the graceful degradation of image quality with respect to channel quality. We also show that the proposed encryption method is problem agnostic, meaning it can be applied to other end-to-end JSCC problems, such as remote classification, without modification. Given the importance of security in modern wireless communication systems, we believe this work brings DeepJSCC schemes much closer to adoption in practice.
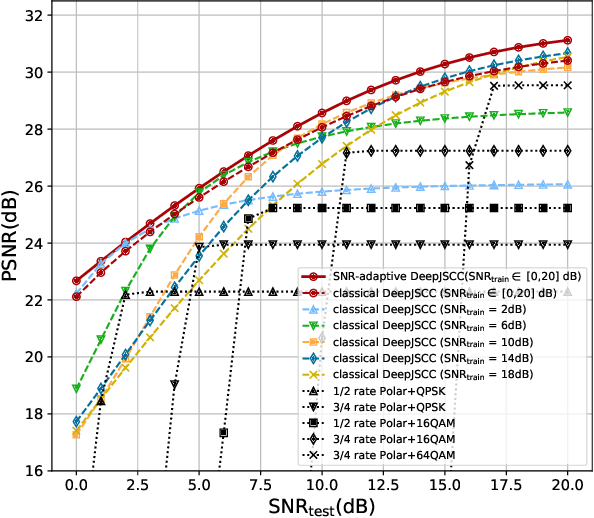
DeepJSCC-Q: Constellation Constrained Deep Joint Source-Channel Coding
Jun 16, 2022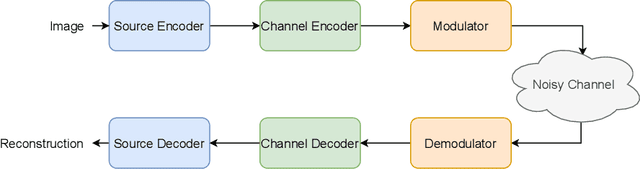
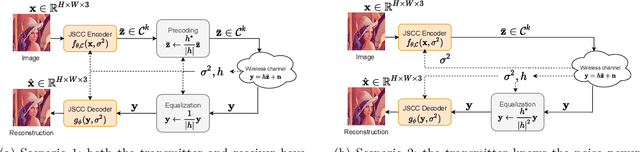
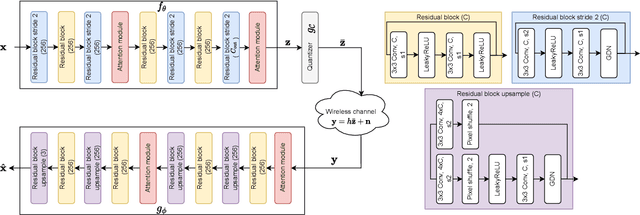
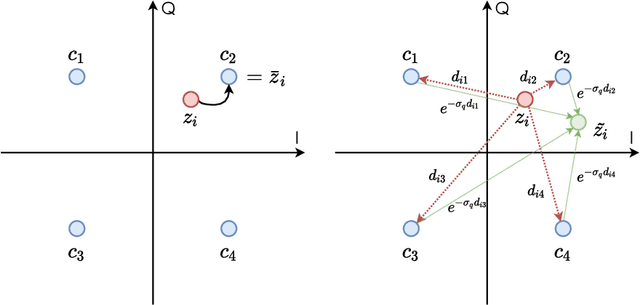
Recent works have shown that modern machine learning techniques can provide an alternative approach to the long-standing joint source-channel coding (JSCC) problem. Very promising initial results, superior to popular digital schemes that utilize separate source and channel codes, have been demonstrated for wireless image and video transmission using deep neural networks (DNNs). However, end-to-end training of such schemes requires a differentiable channel input representation; hence, prior works have assumed that any complex value can be transmitted over the channel. This can prevent the application of these codes in scenarios where the hardware or protocol can only admit certain sets of channel inputs, prescribed by a digital constellation. Herein, we propose DeepJSCC-Q, an end-to-end optimized JSCC solution for wireless image transmission using a finite channel input alphabet. We show that DeepJSCC-Q can achieve similar performance to prior works that allow any complex valued channel input, especially when high modulation orders are available, and that the performance asymptotically approaches that of unconstrained channel input as the modulation order increases. Importantly, DeepJSCC-Q preserves the graceful degradation of image quality in unpredictable channel conditions, a desirable property for deployment in mobile systems with rapidly changing channel conditions.
DeepJSCC-Q: Channel Input Constrained Deep Joint Source-Channel Coding
Nov 25, 2021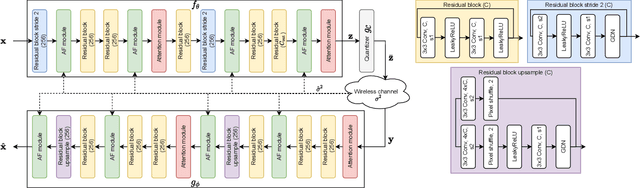
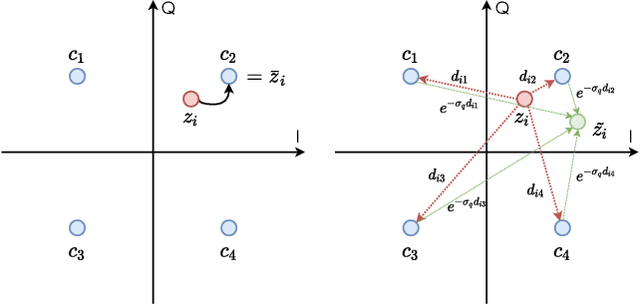
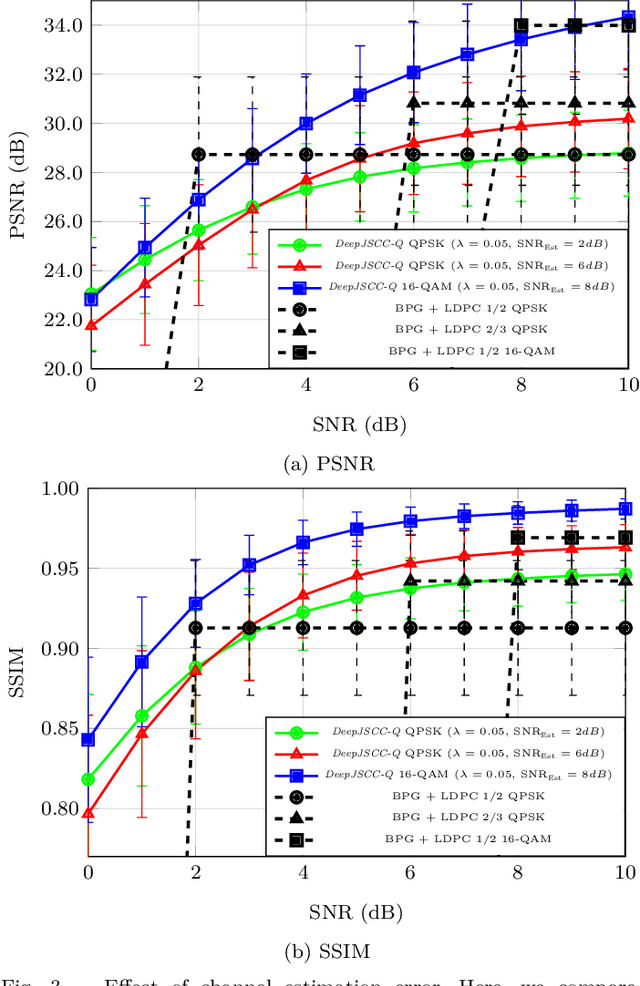
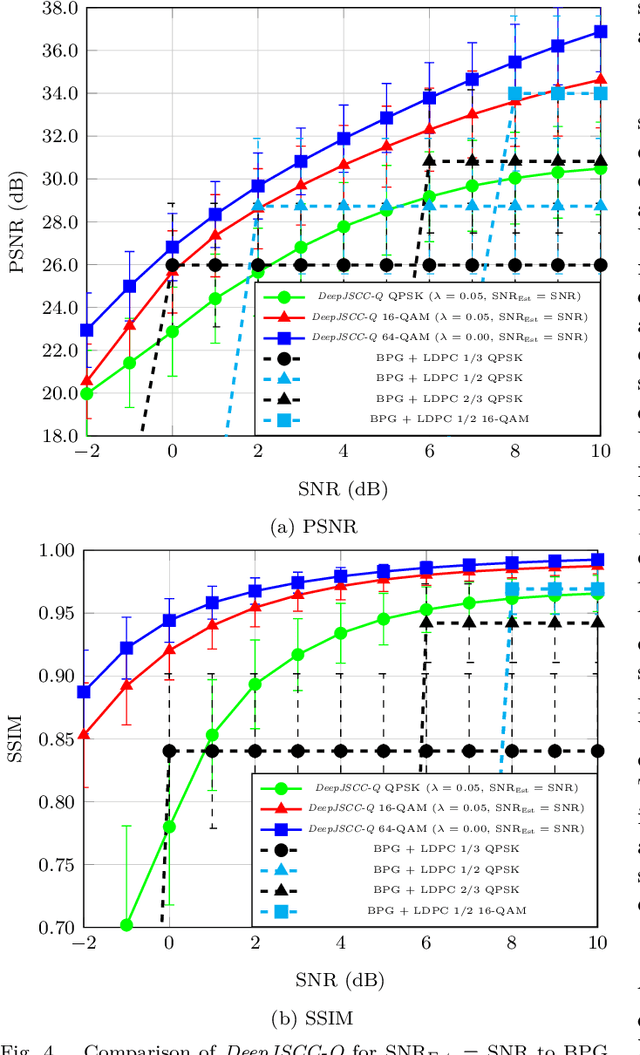
Recent works have shown that the task of wireless transmission of images can be learned with the use of machine learning techniques. Very promising results in end-to-end image quality, superior to popular digital schemes that utilize source and channel coding separation, have been demonstrated through the training of an autoencoder, with a non-trainable channel layer in the middle. However, these methods assume that any complex value can be transmitted over the channel, which can prevent the application of the algorithm in scenarios where the hardware or protocol can only admit certain sets of channel inputs, such as the use of a digital constellation. Herein, we propose DeepJSCC-Q, an end-to-end optimized joint source-channel coding scheme for wireless image transmission, which is able to operate with a fixed channel input alphabet. We show that DeepJSCC-Q can achieve similar performance to models that use continuous-valued channel input. Importantly, it preserves the graceful degradation of image quality observed in prior work when channel conditions worsen, making DeepJSCC-Q much more attractive for deployment in practical systems.
DeepWiVe: Deep-Learning-Aided Wireless Video Transmission
Nov 25, 2021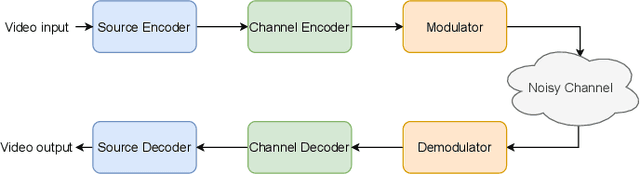
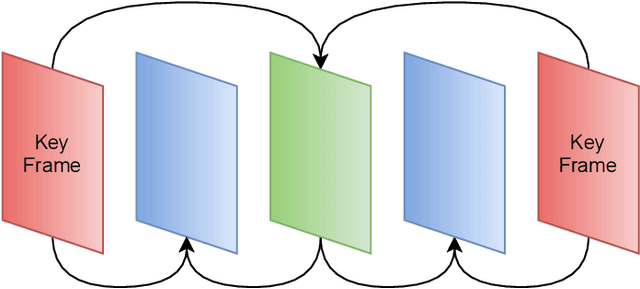
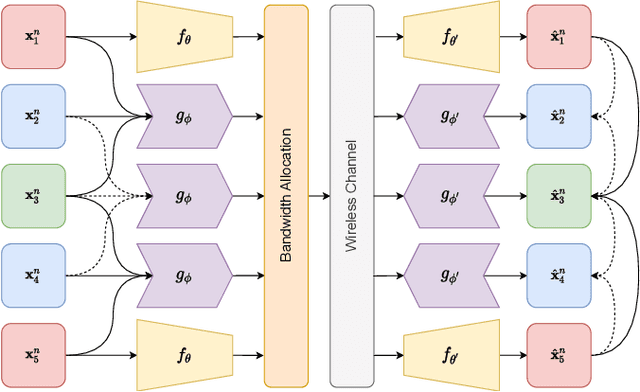
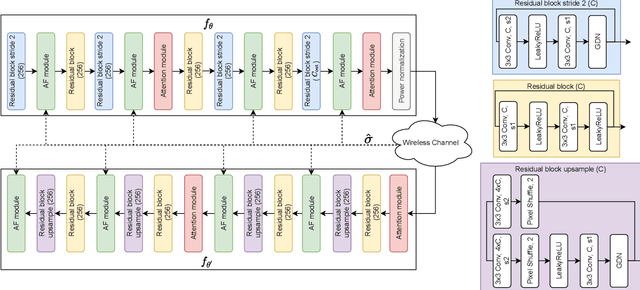
We present DeepWiVe, the first-ever end-to-end joint source-channel coding (JSCC) video transmission scheme that leverages the power of deep neural networks (DNNs) to directly map video signals to channel symbols, combining video compression, channel coding, and modulation steps into a single neural transform. Our DNN decoder predicts residuals without distortion feedback, which improves video quality by accounting for occlusion/disocclusion and camera movements. We simultaneously train different bandwidth allocation networks for the frames to allow variable bandwidth transmission. Then, we train a bandwidth allocation network using reinforcement learning (RL) that optimizes the allocation of limited available channel bandwidth among video frames to maximize overall visual quality. Our results show that DeepWiVe can overcome the cliff-effect, which is prevalent in conventional separation-based digital communication schemes, and achieve graceful degradation with the mismatch between the estimated and actual channel qualities. DeepWiVe outperforms H.264 video compression followed by low-density parity check (LDPC) codes in all channel conditions by up to 0.0462 on average in terms of the multi-scale structural similarity index measure (MS-SSIM), while beating H.265 + LDPC by up to 0.0058 on average. We also illustrate the importance of optimizing bandwidth allocation in JSCC video transmission by showing that our optimal bandwidth allocation policy is superior to the na\"ive uniform allocation. We believe this is an important step towards fulfilling the potential of an end-to-end optimized JSCC wireless video transmission system that is superior to the current separation-based designs.
Federated mmWave Beam Selection Utilizing LIDAR Data
Feb 04, 2021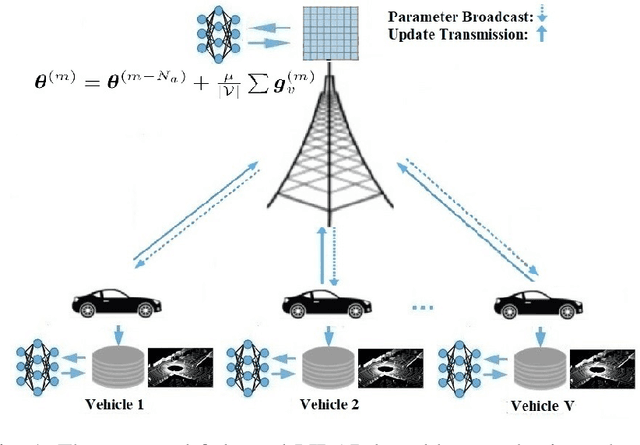

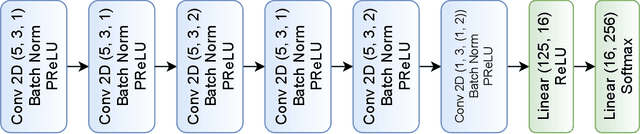
Efficient link configuration in millimeter wave (mmWave) communication systems is a crucial yet challenging task due to the overhead imposed by beam selection on the network performance. For vehicle-to-infrastructure (V2I) networks, side information from LIDAR sensors mounted on the vehicles has been leveraged to reduce the beam search overhead. In this letter, we propose distributed LIDAR aided beam selection for V2I mmWave communication systems utilizing federated training. In the proposed scheme, connected vehicles collaborate to train a shared neural network (NN) on their locally available LIDAR data during normal operation of the system. We also propose an alternative reduced-complexity convolutional NN (CNN) architecture and LIDAR preprocessing, which significantly outperforms previous works in terms of both the performance and the complexity.
A Joint Learning and Communication Framework for Multi-Agent Reinforcement Learning over Noisy Channels
Jan 02, 2021
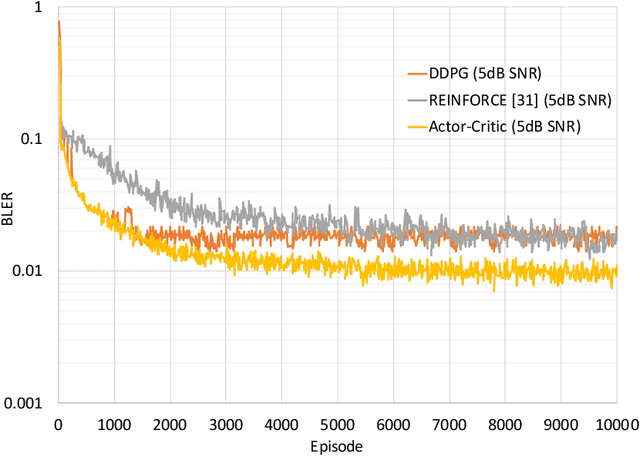
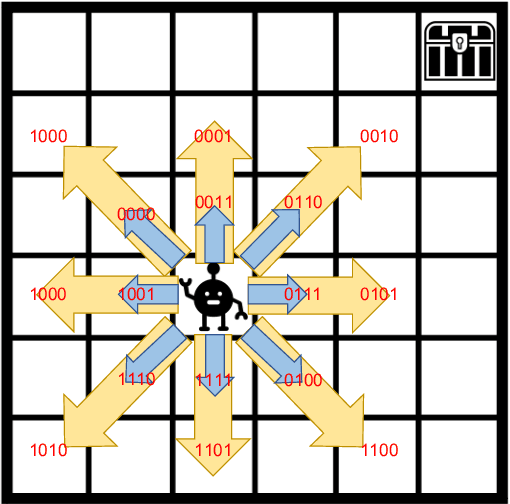
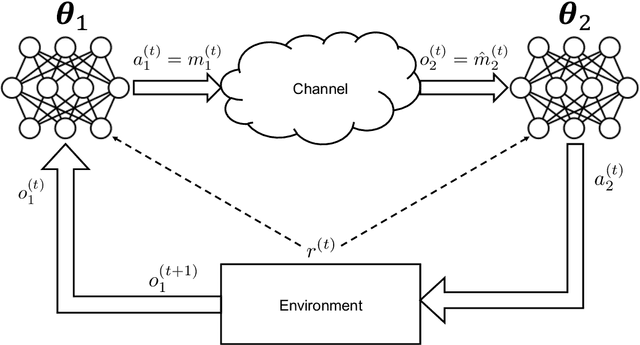
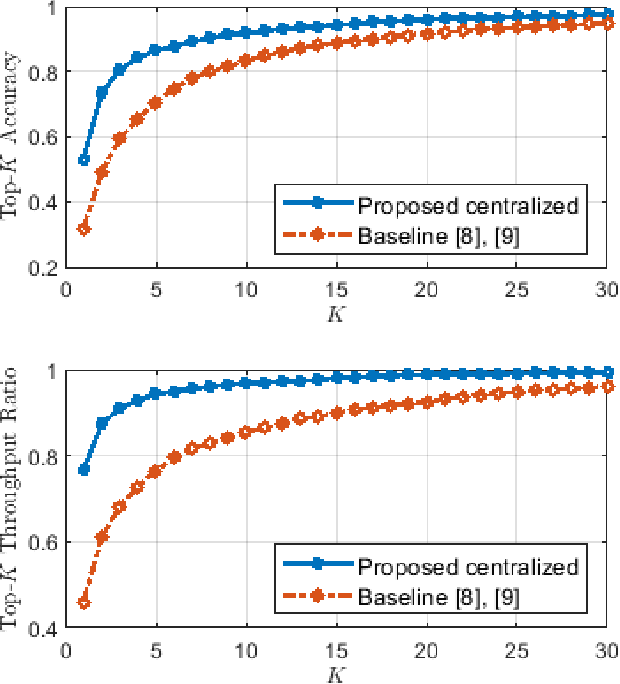
We propose a novel formulation of the "effectiveness problem" in communications, put forth by Shannon and Weaver in their seminal work [2], by considering multiple agents communicating over a noisy channel in order to achieve better coordination and cooperation in a multi-agent reinforcement learning (MARL) framework. Specifically, we consider a multi-agent partially observable Markov decision process (MA-POMDP), in which the agents, in addition to interacting with the environment can also communicate with each other over a noisy communication channel. The noisy communication channel is considered explicitly as part of the dynamics of the environment and the message each agent sends is part of the action that the agent can take. As a result, the agents learn not only to collaborate with each other but also to communicate "effectively" over a noisy channel. This framework generalizes both the traditional communication problem, where the main goal is to convey a message reliably over a noisy channel, and the "learning to communicate" framework that has received recent attention in the MARL literature, where the underlying communication channels are assumed to be error-free. We show via examples that the joint policy learned using the proposed framework is superior to that where the communication is considered separately from the underlying MA-POMDP. This is a very powerful framework, which has many real world applications, from autonomous vehicle planning to drone swarm control, and opens up the rich toolbox of deep reinforcement learning for the design of multi-user communication systems.