 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Overfitting for Low-Complexity and Modality-Agnostic Joint Source-Channel Coding
Dec 24, 2025This paper introduces Implicit-JSCC, a novel overfitted joint source-channel coding paradigm that directly optimizes channel symbols and a lightweight neural decoder for each source. This instance-specific strategy eliminates the need for training datasets or pre-trained models, enabling a storage-free, modality-agnostic solution. As a low-complexity alternative, Implicit-JSCC achieves efficient image transmission with around 1000x lower decoding complexity, using as few as 607 model parameters and 641 multiplications per pixel. This overfitted design inherently addresses source generalizability and achieves state-of-the-art results in the high SNR regimes, underscoring its promise for future communication systems, especially streaming scenarios where one-time offline encoding supports multiple online decoding.
On the Anisotropy of Score-Based Generative Models
Oct 27, 2025We investigate the role of network architecture in shaping the inductive biases of modern score-based generative models. To this end, we introduce the Score Anisotropy Directions (SADs), architecture-dependent directions that reveal how different networks preferentially capture data structure. Our analysis shows that SADs form adaptive bases aligned with the architecture's output geometry, providing a principled way to predict generalization ability in score models prior to training. Through both synthetic data and standard image benchmarks, we demonstrate that SADs reliably capture fine-grained model behavior and correlate with downstream performance, as measured by Wasserstein metrics. Our work offers a new lens for explaining and predicting directional biases of generative models.
LotteryCodec: Searching the Implicit Representation in a Random Network for Low-Complexity Image Compression
Jul 01, 2025We introduce and validate the lottery codec hypothesis, which states that untrained subnetworks within randomly initialized networks can serve as synthesis networks for overfitted image compression, achieving rate-distortion (RD) performance comparable to trained networks. This hypothesis leads to a new paradigm for image compression by encoding image statistics into the network substructure. Building on this hypothesis, we propose LotteryCodec, which overfits a binary mask to an individual image, leveraging an over-parameterized and randomly initialized network shared by the encoder and the decoder. To address over-parameterization challenges and streamline subnetwork search, we develop a rewind modulation mechanism that improves the RD performance. LotteryCodec outperforms VTM and sets a new state-of-the-art in single-image compression. LotteryCodec also enables adaptive decoding complexity through adjustable mask ratios, offering flexible compression solutions for diverse device constraints and application requirements.
LatentINDIGO: An INN-Guided Latent Diffusion Algorithm for Image Restoration
May 19, 2025There is a growing interest in the use of latent diffusion models (LDMs) for image restoration (IR) tasks due to their ability to model effectively the distribution of natural images. While significant progress has been made, there are still key challenges that need to be addressed. First, many approaches depend on a predefined degradation operator, making them ill-suited for complex or unknown degradations that deviate from standard analytical models. Second, many methods struggle to provide a stable guidance in the latent space and finally most methods convert latent representations back to the pixel domain for guidance at every sampling iteration, which significantly increases computational and memory overhead. To overcome these limitations, we introduce a wavelet-inspired invertible neural network (INN) that simulates degradations through a forward transform and reconstructs lost details via the inverse transform. We further integrate this design into a latent diffusion pipeline through two proposed approaches: LatentINDIGO-PixelINN, which operates in the pixel domain, and LatentINDIGO-LatentINN, which stays fully in the latent space to reduce complexity. Both approaches alternate between updating intermediate latent variables under the guidance of our INN and refining the INN forward model to handle unknown degradations. In addition, a regularization step preserves the proximity of latent variables to the natural image manifold. Experiments demonstrate that our algorithm achieves state-of-the-art performance on synthetic and real-world low-quality images, and can be readily adapted to arbitrary output sizes.
Trustworthy Image Super-Resolution via Generative Pseudoinverse
May 18, 2025We consider the problem of trustworthy image restoration, taking the form of a constrained optimization over the prior density. To this end, we develop generative models for the task of image super-resolution that respect the degradation process and that can be made asymptotically consistent with the low-resolution measurements, outperforming existing methods by a large margin in that respect.
SING: Semantic Image Communications using Null-Space and INN-Guided Diffusion Models
Mar 16, 2025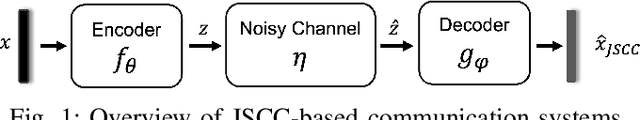
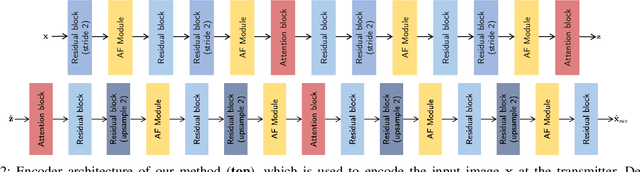

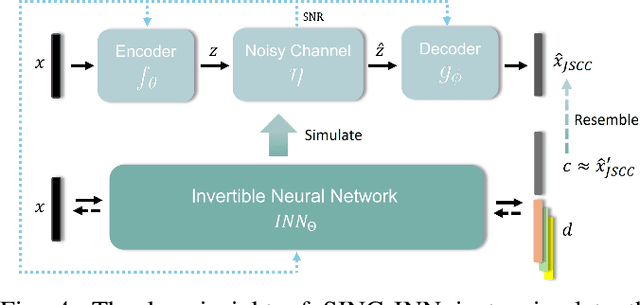
Joint source-channel coding systems based on deep neural networks (DeepJSCC) have recently demonstrated remarkable performance in wireless image transmission. Existing methods primarily focus on minimizing distortion between the transmitted image and the reconstructed version at the receiver, often overlooking perceptual quality. This can lead to severe perceptual degradation when transmitting images under extreme conditions, such as low bandwidth compression ratios (BCRs) and low signal-to-noise ratios (SNRs). In this work, we propose SING, a novel two-stage JSCC framework that formulates the recovery of high-quality source images from corrupted reconstructions as an inverse problem. Depending on the availability of information about the DeepJSCC encoder/decoder and the channel at the receiver, SING can either approximate the stochastic degradation as a linear transformation, or leverage invertible neural networks (INNs) for precise modeling. Both approaches enable the seamless integration of diffusion models into the reconstruction process, enhancing perceptual quality. Experimental results demonstrate that SING outperforms DeepJSCC and other approaches, delivering superior perceptual quality even under extremely challenging conditions, including scenarios with significant distribution mismatches between the training and test data.
SMILENet: Unleashing Extra-Large Capacity Image Steganography via a Synergistic Mosaic InvertibLE Hiding Network
Mar 07, 2025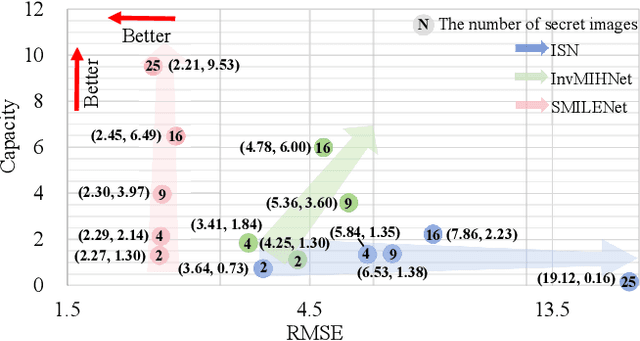
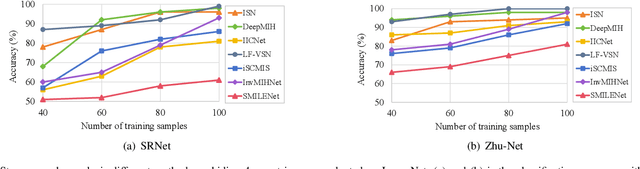

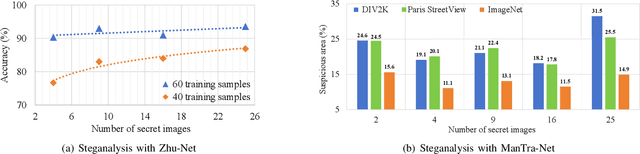
Existing image steganography methods face fundamental limitations in hiding capacity (typically $1\sim7$ images) due to severe information interference and uncoordinated capacity-distortion trade-off. We propose SMILENet, a novel synergistic framework that achieves 25 image hiding through three key innovations: (i) A synergistic network architecture coordinates reversible and non-reversible operations to efficiently exploit information redundancy in both secret and cover images. The reversible Invertible Cover-Driven Mosaic (ICDM) module and Invertible Mosaic Secret Embedding (IMSE) module establish cover-guided mosaic transformations and representation embedding with mathematically guaranteed invertibility for distortion-free embedding. The non-reversible Secret Information Selection (SIS) module and Secret Detail Enhancement (SDE) module implement learnable feature modulation for critical information selection and enhancement. (ii) A unified training strategy that coordinates complementary modules to achieve 3.0x higher capacity than existing methods with superior visual quality. (iii) Last but not least, we introduce a new metric to model Capacity-Distortion Trade-off for evaluating the image steganography algorithms that jointly considers hiding capacity and distortion, and provides a unified evaluation approach for accessing results with different number of secret image. Extensive experiments on DIV2K, Paris StreetView and ImageNet1K show that SMILENet outperforms state-of-the-art methods in terms of hiding capacity, recovery quality as well as security against steganalysis methods.
A Lightweight Deep Exclusion Unfolding Network for Single Image Reflection Removal
Mar 03, 2025Single Image Reflection Removal (SIRR) is a canonical blind source separation problem and refers to the issue of separating a reflection-contaminated image into a transmission and a reflection image. The core challenge lies in minimizing the commonalities among different sources. Existing deep learning approaches either neglect the significance of feature interactions or rely on heuristically designed architectures. In this paper, we propose a novel Deep Exclusion unfolding Network (DExNet), a lightweight, interpretable, and effective network architecture for SIRR. DExNet is principally constructed by unfolding and parameterizing a simple iterative Sparse and Auxiliary Feature Update (i-SAFU) algorithm, which is specifically designed to solve a new model-based SIRR optimization formulation incorporating a general exclusion prior. This general exclusion prior enables the unfolded SAFU module to inherently identify and penalize commonalities between the transmission and reflection features, ensuring more accurate separation. The principled design of DExNet not only enhances its interpretability but also significantly improves its performance. Comprehensive experiments on four benchmark datasets demonstrate that DExNet achieves state-of-the-art visual and quantitative results while utilizing only approximately 8\% of the parameters required by leading methods.
INDIGO+: A Unified INN-Guided Probabilistic Diffusion Algorithm for Blind and Non-Blind Image Restoration
Jan 23, 2025



Generative diffusion models are becoming one of the most popular prior in image restoration (IR) tasks due to their remarkable ability to generate realistic natural images. Despite achieving satisfactory results, IR methods based on diffusion models present several limitations. First of all, most non-blind approaches require an analytical expression of the degradation model to guide the sampling process. Secondly, most existing blind approaches rely on families of pre-defined degradation models for training their deep networks. The above issues limit the flexibility of these approaches and so their ability to handle real-world degradation tasks. In this paper, we propose a novel INN-guided probabilistic diffusion algorithm for non-blind and blind image restoration, namely INDIGO and BlindINDIGO, which combines the merits of the perfect reconstruction property of invertible neural networks (INN) with the strong generative capabilities of pre-trained diffusion models. Specifically, we train the forward process of the INN to simulate an arbitrary degradation process and use the inverse to obtain an intermediate image that we use to guide the reverse diffusion sampling process through a gradient step. We also introduce an initialization strategy, to further improve the performance and inference speed of our algorithm. Experiments demonstrate that our algorithm obtains competitive results compared with recently leading methods both quantitatively and visually on synthetic and real-world low-quality images.
Tracing the Roots: Leveraging Temporal Dynamics in Diffusion Trajectories for Origin Attribution
Nov 12, 2024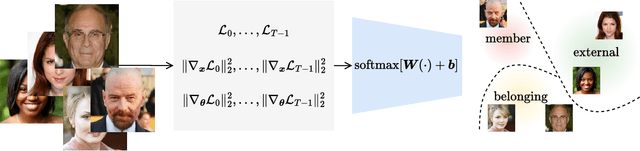
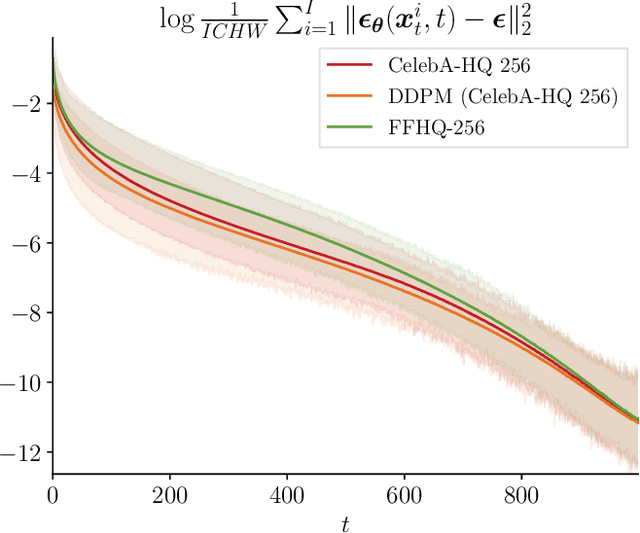

Diffusion models have revolutionized image synthesis, garnering significant research interest in recent years. Diffusion is an iterative algorithm in which samples are generated step-by-step, starting from pure noise. This process introduces the notion of diffusion trajectories, i.e., paths from the standard Gaussian distribution to the target image distribution. In this context, we study discriminative algorithms operating on these trajectories. Specifically, given a pre-trained diffusion model, we consider the problem of classifying images as part of the training dataset, generated by the model or originating from an external source. Our approach demonstrates the presence of patterns across steps that can be leveraged for classification. We also conduct ablation studies, which reveal that using higher-order gradient features to characterize the trajectories leads to significant performance gains and more robust algorithms.