 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffProxy: Multi-View Human Mesh Recovery via Diffusion-Generated Dense Proxies
Jan 05, 2026Human mesh recovery from multi-view images faces a fundamental challenge: real-world datasets contain imperfect ground-truth annotations that bias the models' training, while synthetic data with precise supervision suffers from domain gap. In this paper, we propose DiffProxy, a novel framework that generates multi-view consistent human proxies for mesh recovery. Central to DiffProxy is leveraging the diffusion-based generative priors to bridge the synthetic training and real-world generalization. Its key innovations include: (1) a multi-conditional mechanism for generating multi-view consistent, pixel-aligned human proxies; (2) a hand refinement module that incorporates flexible visual prompts to enhance local details; and (3) an uncertainty-aware test-time scaling method that increases robustness to challenging cases during optimization. These designs ensure that the mesh recovery process effectively benefits from the precise synthetic ground truth and generative advantages of the diffusion-based pipeline. Trained entirely on synthetic data, DiffProxy achieves state-of-the-art performance across five real-world benchmarks, demonstrating strong zero-shot generalization particularly on challenging scenarios with occlusions and partial views. Project page: https://wrk226.github.io/DiffProxy.html
Garment Animation NeRF with Color Editing
Jul 29, 2024



Generating high-fidelity garment animations through traditional workflows, from modeling to rendering, is both tedious and expensive. These workflows often require repetitive steps in response to updates in character motion, rendering viewpoint changes, or appearance edits. Although recent neural rendering offers an efficient solution for computationally intensive processes, it struggles with rendering complex garment animations containing fine wrinkle details and realistic garment-and-body occlusions, while maintaining structural consistency across frames and dense view rendering. In this paper, we propose a novel approach to directly synthesize garment animations from body motion sequences without the need for an explicit garment proxy. Our approach infers garment dynamic features from body motion, providing a preliminary overview of garment structure. Simultaneously, we capture detailed features from synthesized reference images of the garment's front and back, generated by a pre-trained image model. These features are then used to construct a neural radiance field that renders the garment animation video. Additionally, our technique enables garment recoloring by decomposing its visual elements. We demonstrate the generalizability of our method across unseen body motions and camera views, ensuring detailed structural consistency. Furthermore, we showcase its applicability to color editing on both real and synthetic garment data. Compared to existing neural rendering techniques, our method exhibits qualitative and quantitative improvements in garment dynamics and wrinkle detail modeling. Code is available at \url{https://github.com/wrk226/GarmentAnimationNeRF}.
Reconstructing classes of 3D FRI signals from sampled tomographic projections at unknown angles
Apr 15, 2024



Traditional sampling schemes often assume that the sampling locations are known. Motivated by the recent bioimaging technique known as cryogenic electron microscopy (cryoEM), we consider the problem of reconstructing an unknown 3D structure from samples of its 2D tomographic projections at unknown angles. We focus on 3D convex bilevel polyhedra and 3D point sources and show that the exact estimation of these 3D structures and of the projection angles can be achieved up to an orthogonal transformation. Moreover, we are able to show that the minimum number of projections needed to achieve perfect reconstruction is independent of the complexity of the signal model. By using the divergence theorem, we are able to retrieve the projected vertices of the polyhedron from the sampled tomographic projections, and then we show how to retrieve the 3D object and the projection angles from this information. The proof of our theorem is constructive and leads to a robust reconstruction algorithm, which we validate under various conditions. Finally, we apply aspects of the proposed framework to calibration of X-ray computed tomography (CT) data.
Creative Birds: Self-Supervised Single-View 3D Style Transfer
Jul 27, 2023In this paper, we propose a novel method for single-view 3D style transfer that generates a unique 3D object with both shape and texture transfer. Our focus lies primarily on birds, a popular subject in 3D reconstruction, for which no existing single-view 3D transfer methods have been developed.The method we propose seeks to generate a 3D mesh shape and texture of a bird from two single-view images. To achieve this, we introduce a novel shape transfer generator that comprises a dual residual gated network (DRGNet), and a multi-layer perceptron (MLP). DRGNet extracts the features of source and target images using a shared coordinate gate unit, while the MLP generates spatial coordinates for building a 3D mesh. We also introduce a semantic UV texture transfer module that implements textural style transfer using semantic UV segmentation, which ensures consistency in the semantic meaning of the transferred regions. This module can be widely adapted to many existing approaches. Finally, our method constructs a novel 3D bird using a differentiable renderer. Experimental results on the CUB dataset verify that our method achieves state-of-the-art performance on the single-view 3D style transfer task. Code is available in https://github.com/wrk226/creative_birds.
A Probabilistic Model Of Interaction Dynamics for Dyadic Face-to-Face Settings
Jul 10, 2022
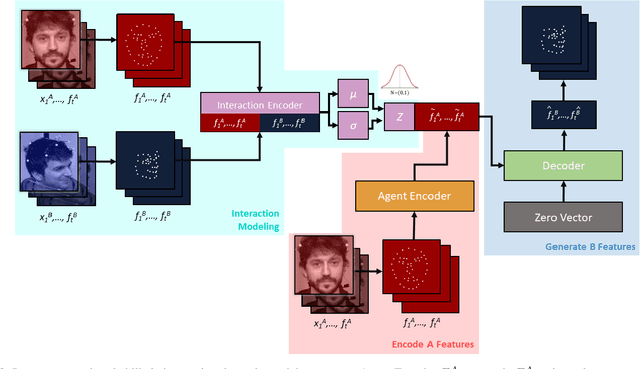


Natural conversations between humans often involve a large number of non-verbal nuanced expressions, displayed at key times throughout the conversation. Understanding and being able to model these complex interactions is essential for creating realistic human-agent communication, whether in the virtual or physical world. As social robots and intelligent avatars emerge in popularity and utility, being able to realistically model and generate these dynamic expressions throughout conversations is critical. We develop a probabilistic model to capture the interaction dynamics between pairs of participants in a face-to-face setting, allowing for the encoding of synchronous expressions between the interlocutors. This interaction encoding is then used to influence the generation when predicting one agent's future dynamics, conditioned on the other's current dynamics. FLAME features are extracted from videos containing natural conversations between subjects to train our interaction model. We successfully assess the efficacy of our proposed model via quantitative metrics and qualitative metrics, and show that it successfully captures the dynamics of a pair of interacting dyads. We also test the model with a never-before-seen parent-infant dataset comprising of two different modes of communication between the dyads, and show that our model successfully delineates between the modes, based on their interacting dynamics.