 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLotteryCodec: Searching the Implicit Representation in a Random Network for Low-Complexity Image Compression
Jul 01, 2025We introduce and validate the lottery codec hypothesis, which states that untrained subnetworks within randomly initialized networks can serve as synthesis networks for overfitted image compression, achieving rate-distortion (RD) performance comparable to trained networks. This hypothesis leads to a new paradigm for image compression by encoding image statistics into the network substructure. Building on this hypothesis, we propose LotteryCodec, which overfits a binary mask to an individual image, leveraging an over-parameterized and randomly initialized network shared by the encoder and the decoder. To address over-parameterization challenges and streamline subnetwork search, we develop a rewind modulation mechanism that improves the RD performance. LotteryCodec outperforms VTM and sets a new state-of-the-art in single-image compression. LotteryCodec also enables adaptive decoding complexity through adjustable mask ratios, offering flexible compression solutions for diverse device constraints and application requirements.
GINO-Q: Learning an Asymptotically Optimal Index Policy for Restless Multi-armed Bandits
Aug 19, 2024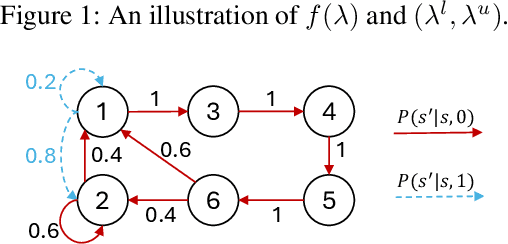

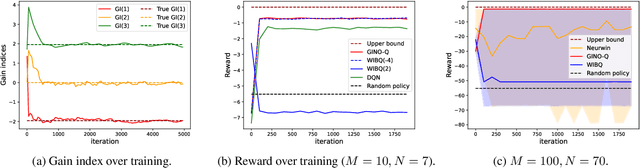
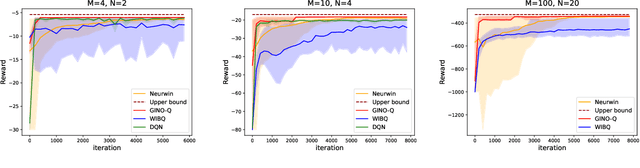
The restless multi-armed bandit (RMAB) framework is a popular model with applications across a wide variety of fields. However, its solution is hindered by the exponentially growing state space (with respect to the number of arms) and the combinatorial action space, making traditional reinforcement learning methods infeasible for large-scale instances. In this paper, we propose GINO-Q, a three-timescale stochastic approximation algorithm designed to learn an asymptotically optimal index policy for RMABs. GINO-Q mitigates the curse of dimensionality by decomposing the RMAB into a series of subproblems, each with the same dimension as a single arm, ensuring that complexity increases linearly with the number of arms. Unlike recently developed Whittle-index-based algorithms, GINO-Q does not require RMABs to be indexable, enhancing its flexibility and applicability. Our experimental results demonstrate that GINO-Q consistently learns near-optimal policies, even for non-indexable RMABs where Whittle-index-based algorithms perform poorly, and it converges significantly faster than existing baselines.
Intermittently Observable Markov Decision Processes
Feb 23, 2023This paper investigates MDPs with intermittent state information. We consider a scenario where the controller perceives the state information of the process via an unreliable communication channel. The transmissions of state information over the whole time horizon are modeled as a Bernoulli lossy process. Hence, the problem is finding an optimal policy for selecting actions in the presence of state information losses. We first formulate the problem as a belief MDP to establish structural results. The effect of state information losses on the expected total discounted reward is studied systematically. Then, we reformulate the problem as a tree MDP whose state space is organized in a tree structure. Two finite-state approximations to the tree MDP are developed to find near-optimal policies efficiently. Finally, we put forth a nested value iteration algorithm for the finite-state approximations, which is proved to be faster than standard value iteration. Numerical results demonstrate the effectiveness of our methods.