 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-SEC: Cross-Layer Semantic Error Correction Empowered by Language Models
Mar 27, 2026Achieving reliable communication has long been a fundamental challenge in networked systems. Semantic Error Correction (SEC) leverages the semantic understanding capabilities of language models (LMs) to perform application-layer error correction, complementing conventional channel decoding. While promising, existing SEC approaches rely solely on context captured by LMs at the application layer, ignoring the rich information available at the physical layer. To address this limitation, this paper introduces Cross-Layer SEC (CL-SEC), an LM-empowered error correction framework that integrates cross-layer information from both the physical and application layers to jointly correct corrupted words in text communication. Using a Bayesian combination in product form tailored to this framework, CL-SEC achieves significantly improved performance over methods that process information in isolated layers. CL-SEC shows substantial gains across multiple error-correction metrics, including bit-error rate, word-error rate, and semantic fidelity scores. Importantly, unlike most semantic communication systems that focus solely on recovering the semantic meaning of transmitted messages, CL-SEC aims to reconstruct the original transmitted message verbatim, leveraging the semantic understanding capabilities of LMs for precise reconstruction.
SA-OOSC: A Multimodal LLM-Distilled Semantic Communication Framework for Enhanced Coding Efficiency with Scenario Understanding
Sep 09, 2025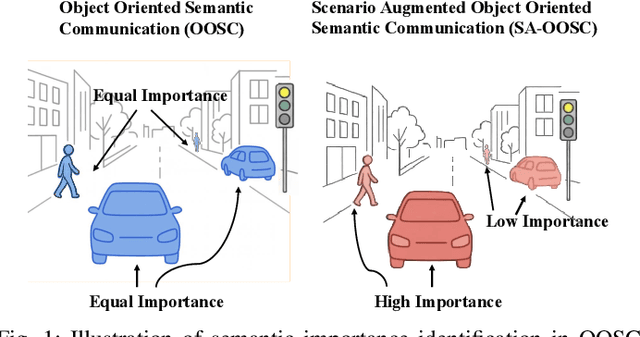

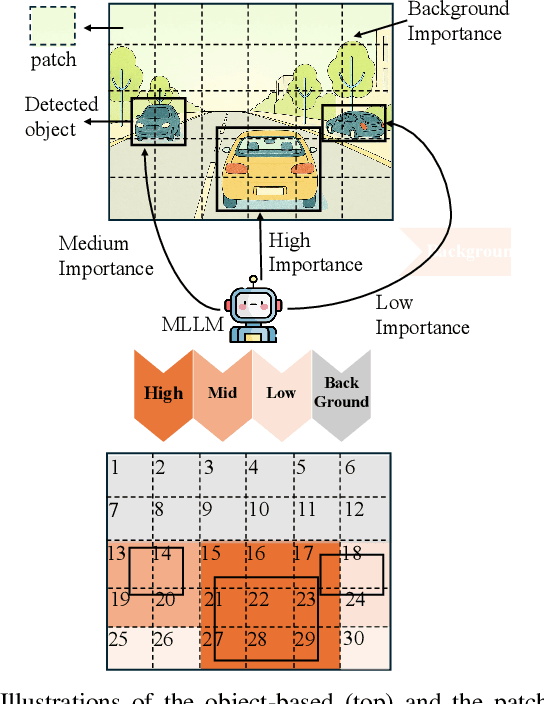
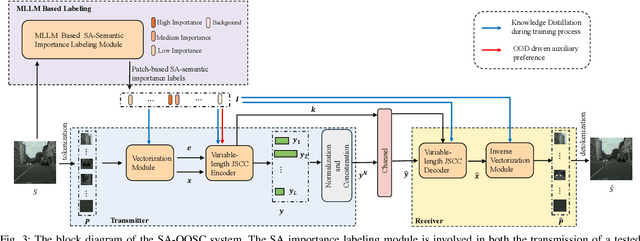
This paper introduces SA-OOSC, a multimodal large language models (MLLM)-distilled semantic communication framework that achieves efficient semantic coding with scenario-aware importance allocations. This approach addresses a critical limitation of existing object-oriented semantic communication (OOSC) systems - assigning static importance values to specific classes of objects regardless of their contextual relevance. Our framework utilizes MLLMs to identify the scenario-augmented (SA) semantic importance for objects within the image. Through knowledge distillation with the MLLM-annotated data, our vectorization/de-vectorization networks and JSCC encoder/decoder learn to dynamically allocate coding resources based on contextual significance, i.e., distinguishing between high-importance objects and low-importance according to the SA scenario information of the task. The framework features three core innovations: a MLLM-guided knowledge distillation pipeline, an importance-weighted variable-length JSCC framework, and novel loss function designs that facilitate the knowledge distillation within the JSCC framework. Experimental validation demonstrates our framework's superior coding efficiency over conventional semantic communication systems, with open-sourced MLLM-annotated and human-verified datasets established as new benchmarks for future research in semantic communications.
Intelligent Reconfigurable Optical Wireless Ether
Feb 10, 2025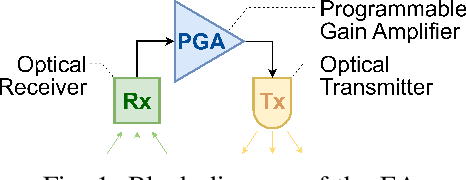
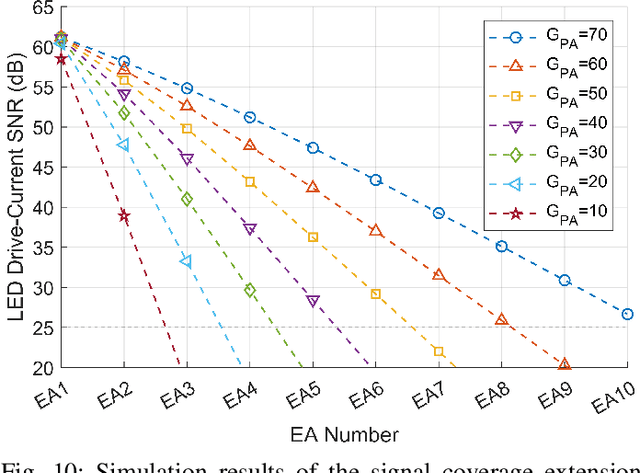
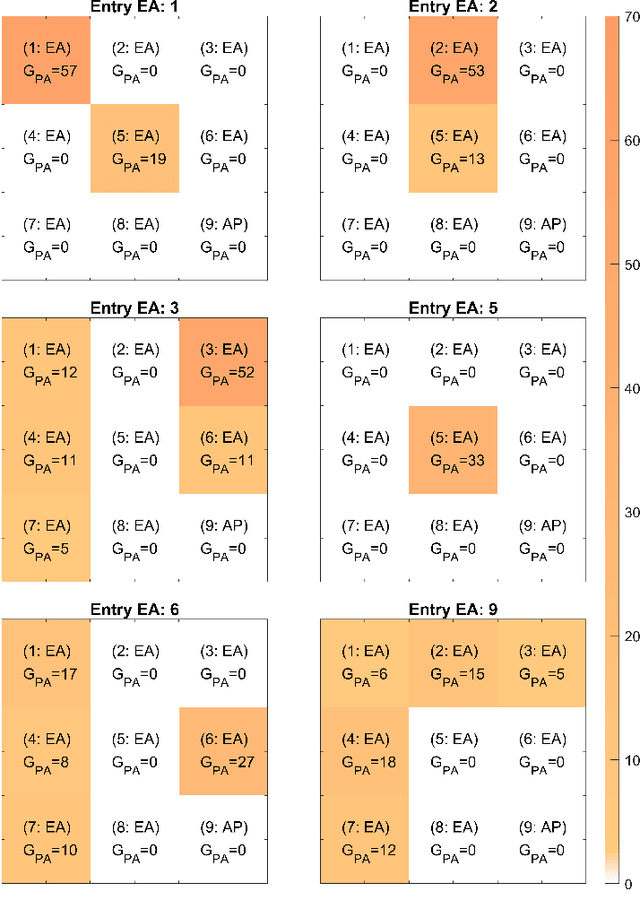
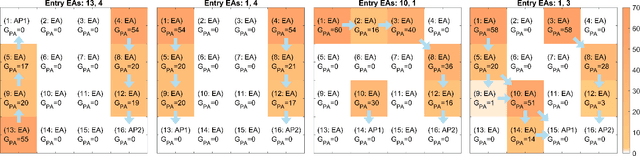
Optical wireless communication (OWC) uses light for wireless data transmission, potentially providing faster and more secure communication than traditional radio-frequency-based techniques like Wi-Fi. However, light's high directionality and its limited penetration ability restrict the signal coverage. To address this limitation, we propose an artificial "optical wireless ether" (OWE) fabric. OWE acts as a reconfigurable electromagnetic (EM) wave-propagating medium, intelligently enhancing the strength of light signals and redirecting their propagation to cover a broader area. Our proposed ether fabric comprises simple optical signal amplification units, called ether amplifiers (EAs), strategically placed in the environment, e.g., on ceilings. The EAs amplify and propagate signals at the analog level and are agnostic to the signal format: Signals propagate wirelessly between the EAs, losing strength due to attenuation during transmission but regaining it as they pass through the EAs. The key challenge in OWE design lies in the fact that, while increasing EA gains can extend signal coverage, it can also create positive feedback loops, resulting in self-interference and amplifier saturation, which distort the signals -- the key challenge in OWE design. This paper presents a systematic theoretical analysis to prevent amplifier saturation while optimizing the performance of OWE in both single-basic-service-set (single-BSS) and multiple-BSS scenarios. Optimization objectives could include signal-to-noise ratio, resource allocation fairness, and mutual interference. Furthermore, we conducted simulations and experiments to corroborate our theories. To our knowledge, ours is the first experimental demonstration of the feasibility of an artificial ether fabric for extending and guiding light propagation, laying a solid groundwork for future development and exploration of OWE.
GINO-Q: Learning an Asymptotically Optimal Index Policy for Restless Multi-armed Bandits
Aug 19, 2024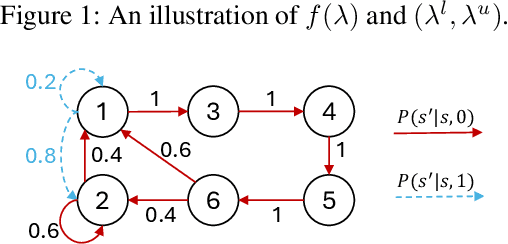

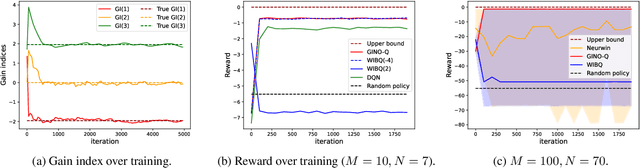
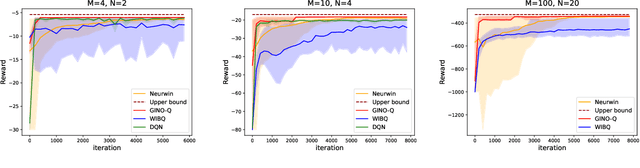
The restless multi-armed bandit (RMAB) framework is a popular model with applications across a wide variety of fields. However, its solution is hindered by the exponentially growing state space (with respect to the number of arms) and the combinatorial action space, making traditional reinforcement learning methods infeasible for large-scale instances. In this paper, we propose GINO-Q, a three-timescale stochastic approximation algorithm designed to learn an asymptotically optimal index policy for RMABs. GINO-Q mitigates the curse of dimensionality by decomposing the RMAB into a series of subproblems, each with the same dimension as a single arm, ensuring that complexity increases linearly with the number of arms. Unlike recently developed Whittle-index-based algorithms, GINO-Q does not require RMABs to be indexable, enhancing its flexibility and applicability. Our experimental results demonstrate that GINO-Q consistently learns near-optimal policies, even for non-indexable RMABs where Whittle-index-based algorithms perform poorly, and it converges significantly faster than existing baselines.
Addressing Out-of-Distribution Challenges in Image Semantic Communication Systems with Multi-modal Large Language Models
Jul 22, 2024



Semantic communication is a promising technology for next-generation wireless networks. However, the out-of-distribution (OOD) problem, where a pre-trained machine learning (ML) model is applied to unseen tasks that are outside the distribution of its training data, may compromise the integrity of semantic compression. This paper explores the use of multi-modal large language models (MLLMs) to address the OOD issue in image semantic communication. We propose a novel "Plan A - Plan B" framework that leverages the broad knowledge and strong generalization ability of an MLLM to assist a conventional ML model when the latter encounters an OOD input in the semantic encoding process. Furthermore, we propose a Bayesian optimization scheme that reshapes the probability distribution of the MLLM's inference process based on the contextual information of the image. The optimization scheme significantly enhances the MLLM's performance in semantic compression by 1) filtering out irrelevant vocabulary in the original MLLM output; and 2) using contextual similarities between prospective answers of the MLLM and the background information as prior knowledge to modify the MLLM's probability distribution during inference. Further, at the receiver side of the communication system, we put forth a "generate-criticize" framework that utilizes the cooperation of multiple MLLMs to enhance the reliability of image reconstruction.
LLMind: Orchestrating AI and IoT with LLMs for Complex Task Execution
Dec 14, 2023
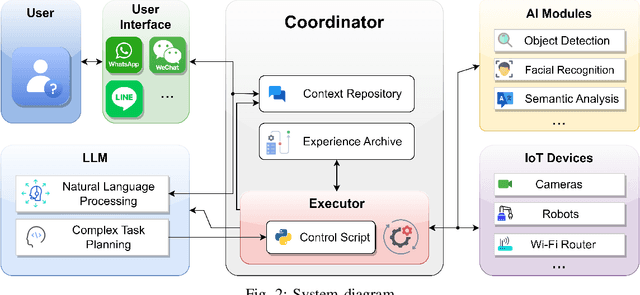
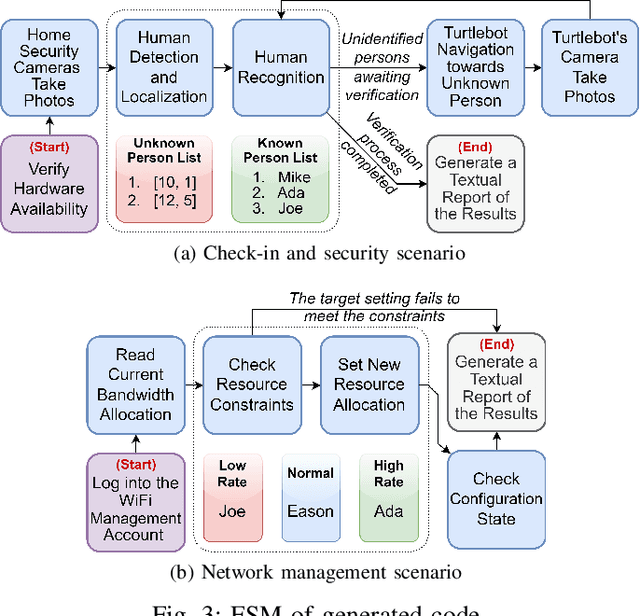
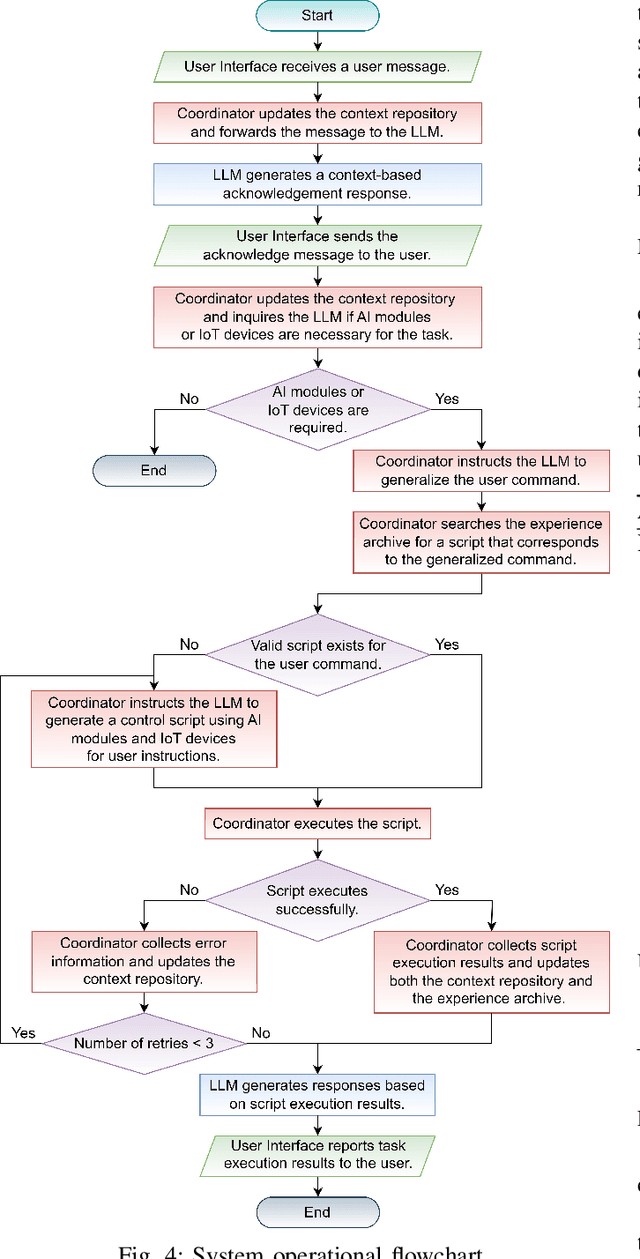
In this article, we introduce LLMind, an innovative AI framework that utilizes large language models (LLMs) as a central orchestrator. The framework integrates LLMs with domain-specific AI modules, enabling IoT devices to collaborate effectively in executing complex tasks. The LLM performs planning and generates control scripts using a reliable and precise language-code transformation approach based on finite state machines (FSMs). The LLM engages in natural conversations with users, employing role-playing techniques to generate contextually appropriate responses. Additionally, users can interact easily with the AI agent via a user-friendly social media platform. The framework also incorporates semantic analysis and response optimization techniques to enhance speed and effectiveness. Ultimately, this framework is designed not only to innovate IoT device control and enrich user experiences but also to foster an intelligent and integrated IoT device ecosystem that evolves and becomes more sophisticated through continuing user and machine interactions.
The Power of Large Language Models for Wireless Communication System Development: A Case Study on FPGA Platforms
Jul 14, 2023



Large language models (LLMs) have garnered significant attention across various research disciplines, including the wireless communication community. There have been several heated discussions on the intersection of LLMs and wireless technologies. While recent studies have demonstrated the ability of LLMs to generate hardware description language (HDL) code for simple computation tasks, developing wireless prototypes and products via HDL poses far greater challenges because of the more complex computation tasks involved. In this paper, we aim to address this challenge by investigating the role of LLMs in FPGA-based hardware development for advanced wireless signal processing. We begin by exploring LLM-assisted code refactoring, reuse, and validation, using an open-source software-defined radio (SDR) project as a case study. Through the case study, we find that an LLM assistant can potentially yield substantial productivity gains for researchers and developers. We then examine the feasibility of using LLMs to generate HDL code for advanced wireless signal processing, using the Fast Fourier Transform (FFT) algorithm as an example. This task presents two unique challenges: the scheduling of subtasks within the overall task and the multi-step thinking required to solve certain arithmetic problem within the task. To address these challenges, we employ in-context learning (ICL) and Chain-of-Thought (CoT) prompting techniques, culminating in the successful generation of a 64-point Verilog FFT module. Our results demonstrate the potential of LLMs for generalization and imitation, affirming their usefulness in writing HDL code for wireless communication systems. Overall, this work contributes to understanding the role of LLMs in wireless communication and motivates further exploration of their capabilities.
Efficient FFT Computation in IFDMA Transceivers
Mar 05, 2022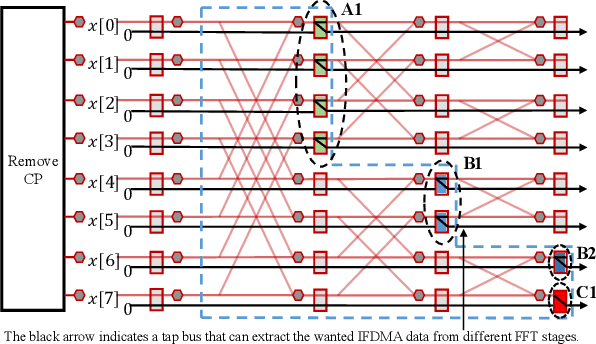
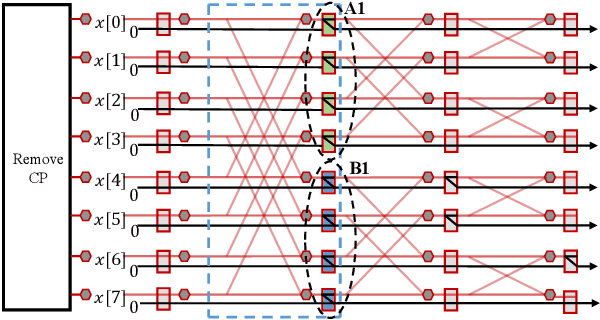
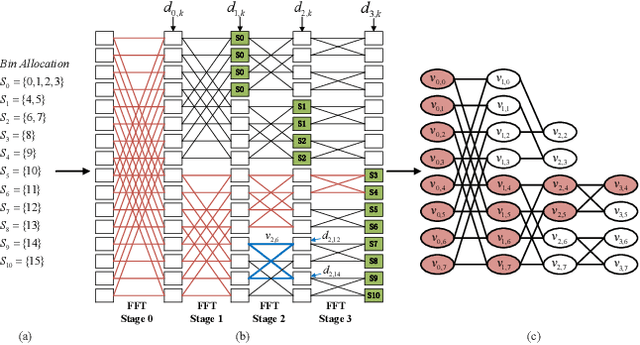

Interleaved Frequency Division Multiple Access (IFDMA) has the salient advantage of lower Peak-to-Average Power Ratio (PAPR) than its competitors like Orthogonal FDMA (OFDMA). A recent research effort put forth a new IFDMA transceiver design significantly less complex than conventional IFDMA transceivers. The new IFDMA transceiver design reduces the complexity by exploiting a certain correspondence between the IFDMA signal processing and the Cooley-Tukey IFFT/FFT algorithmic structure so that IFDMA streams can be inserted/extracted at different stages of an IFFT/FFT module according to the sizes of the streams. Although the prior work has laid down the theoretical foundation for the new IFDMA transceiver's structure, the practical realization of the transceiver on specific hardware with resource constraints has not been carefully investigated. This paper is an attempt to fill the gap. Specifically, this paper puts forth a heuristic algorithm called multi-priority scheduling (MPS) to schedule the execution of the butterfly computations in the IFDMA transceiver with the constraint of a limited number of hardware processors. The resulting FFT computation, referred to as MPS-FFT, has a much lower computation time than conventional FFT computation when applied to the IFDMA signal processing. Importantly, we derive a lower bound for the optimal IFDMA FFT computation time to benchmark MPS-FFT. Our experimental results indicate that when the number of hardware processors is a power of two: 1) MPS-FFT has near-optimal computation time; 2) MPS-FFT incurs less than 44.13\% of the computation time of the conventional pipelined FFT.
Bayesian Over-The-Air Computation
Sep 08, 2021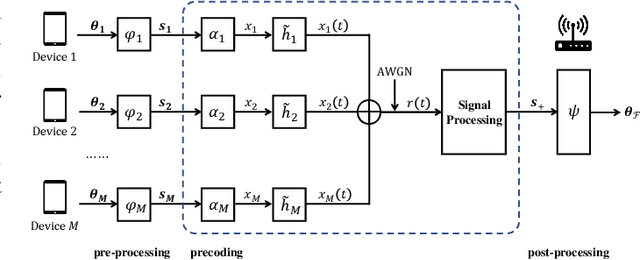
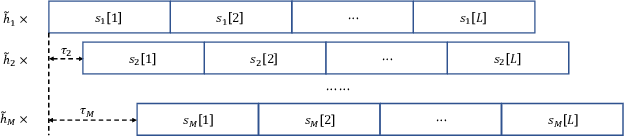
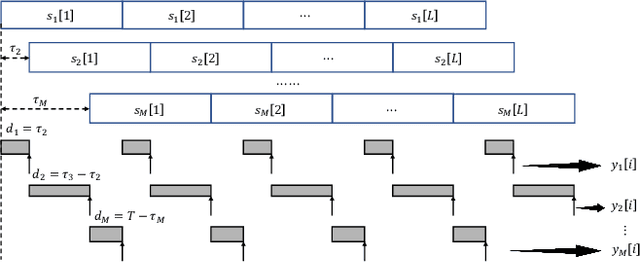
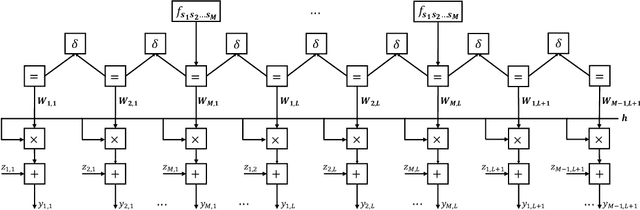
Analog over-the-air computation (OAC) is an efficient solution to a class of uplink data aggregation tasks over a multiple-access channel (MAC), wherein the receiver, dubbed the fusion center, aims to reconstruct a function of the data distributed at edge devices rather than the individual data themselves. Existing OAC relies exclusively on the maximum likelihood (ML) estimation at the fusion center to recover the arithmetic sum of the transmitted signals from different devices. ML estimation, however, is much susceptible to noise. In particular, in the misaligned OAC where there are channel misalignments among transmitted signals, ML estimation suffers from severe error propagation and noise enhancement. To address these challenges, this paper puts forth a Bayesian approach for OAC by letting each edge device transmit two pieces of prior information to the fusion center. Three OAC systems are studied: the aligned OAC with perfectly-aligned signals; the synchronous OAC with misaligned channel gains among the received signals; and the asynchronous OAC with both channel-gain and time misalignments. Using the prior information, we devise linear minimum mean squared error (LMMSE) estimators and a sum-product maximum a posteriori (SP-MAP) estimator for the three OAC systems. Numerical results verify that, 1) For the aligned and synchronous OAC, our LMMSE estimator significantly outperforms the ML estimator. In the low signal-to-noise ratio (SNR) regime, the LMMSE estimator reduces the mean squared error (MSE) by at least 6 dB; in the high SNR regime, the LMMSE estimator lowers the error floor on the MSE by 86.4%; 2) For the asynchronous OAC, our LMMSE and SP-MAP estimators are on an equal footing in terms of the MSE performance, and are significantly better than the ML estimator.
Denoising Noisy Neural Networks: A Bayesian Approach with Compensation
May 22, 2021

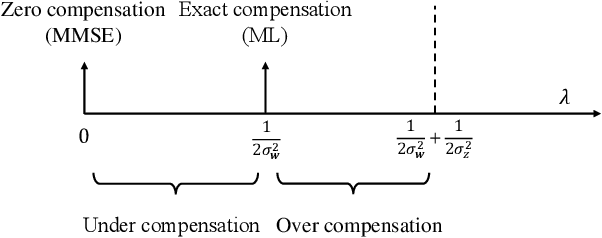
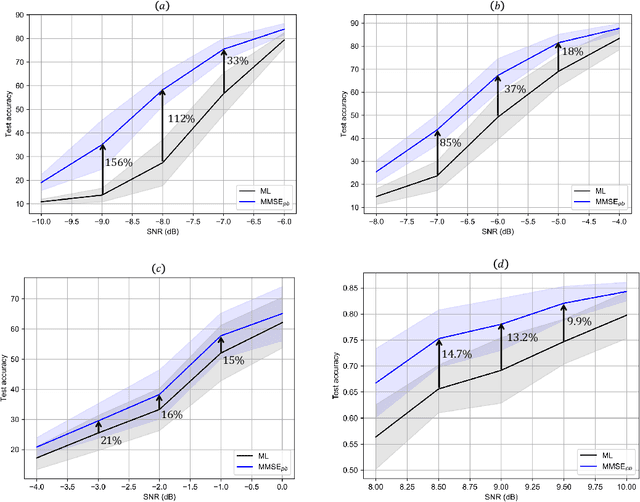
Noisy neural networks (NoisyNNs) refer to the inference and training of NNs in the presence of noise. Noise is inherent in most communication and storage systems; hence, NoisyNNs emerge in many new applications, including federated edge learning, where wireless devices collaboratively train a NN over a noisy wireless channel, or when NNs are implemented/stored in an analog storage medium. This paper studies a fundamental problem of NoisyNNs: how to estimate the uncontaminated NN weights from their noisy observations or manifestations. Whereas all prior works relied on the maximum likelihood (ML) estimation to maximize the likelihood function of the estimated NN weights, this paper demonstrates that the ML estimator is in general suboptimal. To overcome the suboptimality of the conventional ML estimator, we put forth an $\text{MMSE}_{pb}$ estimator to minimize a compensated mean squared error (MSE) with a population compensator and a bias compensator. Our approach works well for NoisyNNs arising in both 1) noisy inference, where noise is introduced only in the inference phase on the already-trained NN weights; and 2) noisy training, where noise is introduced over the course of training. Extensive experiments on the CIFAR-10 and SST-2 datasets with different NN architectures verify the significant performance gains of the $\text{MMSE}_{pb}$ estimator over the ML estimator when used to denoise the NoisyNN. For noisy inference, the average gains are up to $156\%$ for a noisy ResNet34 model and $14.7\%$ for a noisy BERT model; for noisy training, the average gains are up to $18.1$ dB for a noisy ResNet18 model.