 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDC-Cache: A Trustworthy Decentralized Cooperative Caching Framework for Web3.0
Dec 10, 2025



The rapid growth of Web3.0 is transforming the Internet from a centralized structure to decentralized, which empowers users with unprecedented self-sovereignty over their own data. However, in the context of decentralized data access within Web3.0, it is imperative to cope with efficiency concerns caused by the replication of redundant data, as well as security vulnerabilities caused by data inconsistency. To address these challenges, we develop a Trustworthy Decentralized Cooperative Caching (TDC-Cache) framework for Web3.0 to ensure efficient caching and enhance system resilience against adversarial threats. This framework features a two-layer architecture, wherein the Decentralized Oracle Network (DON) layer serves as a trusted intermediary platform for decentralized caching, bridging the contents from decentralized storage and the content requests from users. In light of the complexity of Web3.0 network topologies and data flows, we propose a Deep Reinforcement Learning-Based Decentralized Caching (DRL-DC) for TDC-Cache to dynamically optimize caching strategies of distributed oracles. Furthermore, we develop a Proof of Cooperative Learning (PoCL) consensus to maintain the consistency of decentralized caching decisions within DON. Experimental results show that, compared with existing approaches, the proposed framework reduces average access latency by 20%, increases the cache hit rate by at most 18%, and improves the average success consensus rate by 10%. Overall, this paper serves as a first foray into the investigation of decentralized caching framework and strategy for Web3.0.
Privacy-preserving Preselection for Face Identification Based on Packing
Jul 03, 2025Face identification systems operating in the ciphertext domain have garnered significant attention due to increasing privacy concerns and the potential recovery of original facial data. However, as the size of ciphertext template libraries grows, the face retrieval process becomes progressively more time-intensive. To address this challenge, we propose a novel and efficient scheme for face retrieval in the ciphertext domain, termed Privacy-Preserving Preselection for Face Identification Based on Packing (PFIP). PFIP incorporates an innovative preselection mechanism to reduce computational overhead and a packing module to enhance the flexibility of biometric systems during the enrollment stage. Extensive experiments conducted on the LFW and CASIA datasets demonstrate that PFIP preserves the accuracy of the original face recognition model, achieving a 100% hit rate while retrieving 1,000 ciphertext face templates within 300 milliseconds. Compared to existing approaches, PFIP achieves a nearly 50x improvement in retrieval efficiency.
Semi-supervised Node Importance Estimation with Informative Distribution Modeling for Uncertainty Regularization
Mar 26, 2025Node importance estimation, a classical problem in network analysis, underpins various web applications. Previous methods either exploit intrinsic topological characteristics, e.g., graph centrality, or leverage additional information, e.g., data heterogeneity, for node feature enhancement. However, these methods follow the supervised learning setting, overlooking the fact that ground-truth node-importance data are usually partially labeled in practice. In this work, we propose the first semi-supervised node importance estimation framework, i.e., EASING, to improve learning quality for unlabeled data in heterogeneous graphs. Different from previous approaches, EASING explicitly captures uncertainty to reflect the confidence of model predictions. To jointly estimate the importance values and uncertainties, EASING incorporates DJE, a deep encoder-decoder neural architecture. DJE introduces distribution modeling for graph nodes, where the distribution representations derive both importance and uncertainty estimates. Additionally, DJE facilitates effective pseudo-label generation for the unlabeled data to enrich the training samples. Based on labeled and pseudo-labeled data, EASING develops effective semi-supervised heteroscedastic learning with varying node uncertainty regularization. Extensive experiments on three real-world datasets highlight the superior performance of EASING compared to competing methods. Codes are available via https://github.com/yankai-chen/EASING.
Zero-Knowledge Federated Learning: A New Trustworthy and Privacy-Preserving Distributed Learning Paradigm
Mar 18, 2025


Federated Learning (FL) has emerged as a promising paradigm in distributed machine learning, enabling collaborative model training while preserving data privacy. However, despite its many advantages, FL still contends with significant challenges -- most notably regarding security and trust. Zero-Knowledge Proofs (ZKPs) offer a potential solution by establishing trust and enhancing system integrity throughout the FL process. Although several studies have explored ZKP-based FL (ZK-FL), a systematic framework and comprehensive analysis are still lacking. This article makes two key contributions. First, we propose a structured ZK-FL framework that categorizes and analyzes the technical roles of ZKPs across various FL stages and tasks. Second, we introduce a novel algorithm, Verifiable Client Selection FL (Veri-CS-FL), which employs ZKPs to refine the client selection process. In Veri-CS-FL, participating clients generate verifiable proofs for the performance metrics of their local models and submit these concise proofs to the server for efficient verification. The server then selects clients with high-quality local models for uploading, subsequently aggregating the contributions from these selected clients. By integrating ZKPs, Veri-CS-FL not only ensures the accuracy of performance metrics but also fortifies trust among participants while enhancing the overall efficiency and security of FL systems.
In-depth Analysis of Graph-based RAG in a Unified Framework
Mar 06, 2025Graph-based Retrieval-Augmented Generation (RAG) has proven effective in integrating external knowledge into large language models (LLMs), improving their factual accuracy, adaptability, interpretability, and trustworthiness. A number of graph-based RAG methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework to incorporate all graph-based RAG methods from a high-level perspective. We then extensively compare representative graph-based RAG methods over a range of questing-answering (QA) datasets -- from specific questions to abstract questions -- and examine the effectiveness of all methods, providing a thorough analysis of graph-based RAG approaches. As a byproduct of our experimental analysis, we are also able to identify new variants of the graph-based RAG methods over specific QA and abstract QA tasks respectively, by combining existing techniques, which outperform the state-of-the-art methods. Finally, based on these findings, we offer promising research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide new valuable insights for future research.
A Survey of Zero-Knowledge Proof Based Verifiable Machine Learning
Feb 25, 2025



As machine learning technologies advance rapidly across various domains, concerns over data privacy and model security have grown significantly. These challenges are particularly pronounced when models are trained and deployed on cloud platforms or third-party servers due to the computational resource limitations of users' end devices. In response, zero-knowledge proof (ZKP) technology has emerged as a promising solution, enabling effective validation of model performance and authenticity in both training and inference processes without disclosing sensitive data. Thus, ZKP ensures the verifiability and security of machine learning models, making it a valuable tool for privacy-preserving AI. Although some research has explored the verifiable machine learning solutions that exploit ZKP, a comprehensive survey and summary of these efforts remain absent. This survey paper aims to bridge this gap by reviewing and analyzing all the existing Zero-Knowledge Machine Learning (ZKML) research from June 2017 to December 2024. We begin by introducing the concept of ZKML and outlining its ZKP algorithmic setups under three key categories: verifiable training, verifiable inference, and verifiable testing. Next, we provide a comprehensive categorization of existing ZKML research within these categories and analyze the works in detail. Furthermore, we explore the implementation challenges faced in this field and discuss the improvement works to address these obstacles. Additionally, we highlight several commercial applications of ZKML technology. Finally, we propose promising directions for future advancements in this domain.
A deep-learning-based MAC for integrating channel access, rate adaptation and channel switch
Jun 04, 2024



With increasing density and heterogeneity in unlicensed wireless networks, traditional MAC protocols, such as carrier-sense multiple access with collision avoidance (CSMA/CA) in Wi-Fi networks, are experiencing performance degradation. This is manifested in increased collisions and extended backoff times, leading to diminished spectrum efficiency and protocol coordination. Addressing these issues, this paper proposes a deep-learning-based MAC paradigm, dubbed DL-MAC, which leverages spectrum sensing data readily available from energy detection modules in wireless devices to achieve the MAC functionalities of channel access, rate adaptation and channel switch. First, we utilize DL-MAC to realize a joint design of channel access and rate adaptation. Subsequently, we integrate the capability of channel switch into DL-MAC, enhancing its functionality from single-channel to multi-channel operation. Specifically, the DL-MAC protocol incorporates a deep neural network (DNN) for channel selection and a recurrent neural network (RNN) for the joint design of channel access and rate adaptation. We conducted real-world data collection within the 2.4 GHz frequency band to validate the effectiveness of DL-MAC, and our experiments reveal that DL-MAC exhibits superior performance over traditional algorithms in both single and multi-channel environments and also outperforms single-function approaches in terms of overall performance. Additionally, the performance of DL-MAC remains robust, unaffected by channel switch overhead within the evaluated range.
Learning-based Autonomous Channel Access in the Presence of Hidden Terminals
Jul 07, 2022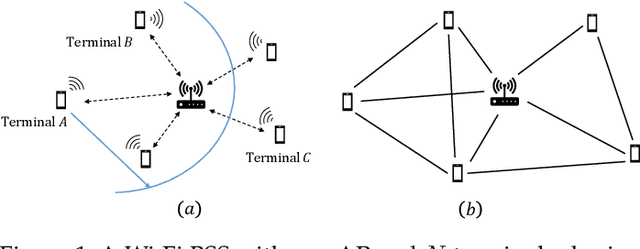
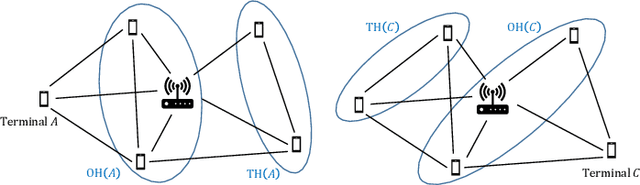
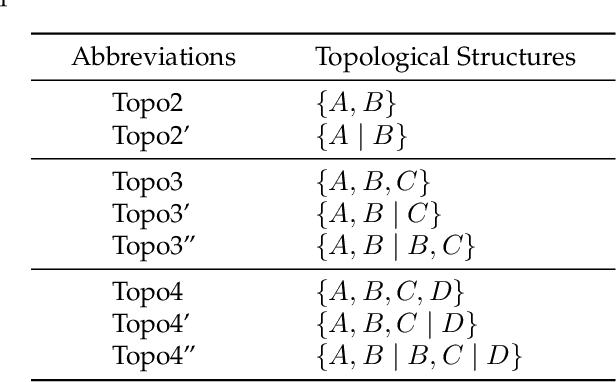
We consider the problem of autonomous channel access (AutoCA), where a group of terminals tries to discover a communication strategy with an access point (AP) via a common wireless channel in a distributed fashion. Due to the irregular topology and the limited communication range of terminals, a practical challenge for AutoCA is the hidden terminal problem, which is notorious in wireless networks for deteriorating the throughput and delay performances. To meet the challenge, this paper presents a new multi-agent deep reinforcement learning paradigm, dubbed MADRL-HT, tailored for AutoCA in the presence of hidden terminals. MADRL-HT exploits topological insights and transforms the observation space of each terminal into a scalable form independent of the number of terminals. To compensate for the partial observability, we put forth a look-back mechanism such that the terminals can infer behaviors of their hidden terminals from the carrier sensed channel states as well as feedback from the AP. A window-based global reward function is proposed, whereby the terminals are instructed to maximize the system throughput while balancing the terminals' transmission opportunities over the course of learning. Extensive numerical experiments verified the superior performance of our solution benchmarked against the legacy carrier-sense multiple access with collision avoidance (CSMA/CA) protocol.
PNC Enabled IIoT: A General Framework for Channel-Coded Asymmetric Physical-Layer Network Coding
Jul 08, 2021


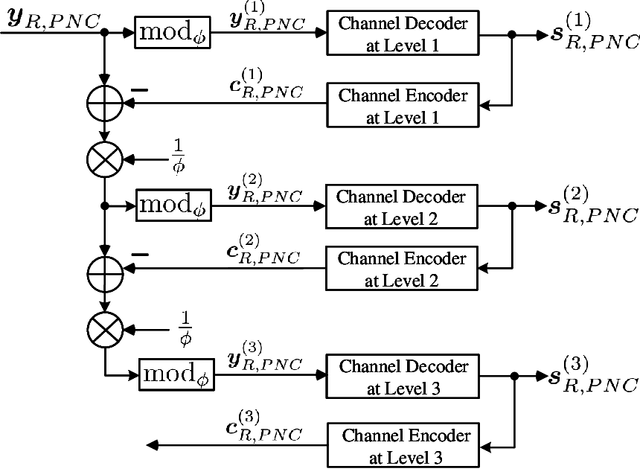
This paper investigates the application of physical-layer network coding (PNC) to Industrial Internet-of-Things (IIoT) where a controller and a robot are out of each other's transmission range, and they exchange messages with the assistance of a relay. We particularly focus on a scenario where the controller has more transmitted information, and the channel of the controller is stronger than that of the robot. To reduce the communication latency, we propose an asymmetric transmission scheme where the controller and robot transmit different amount of information in the uplink of PNC simultaneously. To achieve this, the controller chooses a higher order modulation. In addition, the both users apply channel codes to guarantee the reliability. A problem is a superimposed symbol at the relay contains different amount of source information from the two end users. It is thus hard for the relay to deduce meaningful network-coded messages by applying the current PNC decoding techniques which require the end users to transmit the same amount of information. To solve this problem, we propose a lattice-based scheme where the two users encode-and-modulate their information in lattices with different lattice construction levels. Our design is versatile on that the two end users can freely choose their modulation orders based on their channel power, and the design is applicable for arbitrary channel codes.
AlphaSeq: Sequence Discovery with Deep Reinforcement Learning
Sep 26, 2018
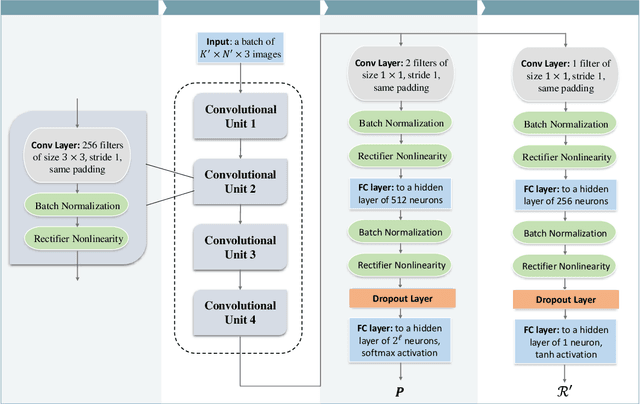

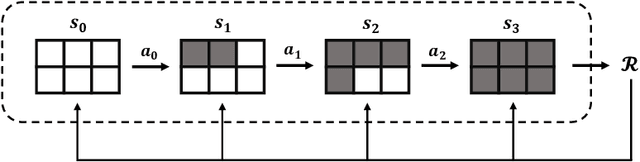
Sequences play an important role in many applications and systems. Discovering sequences with desired properties has long been an interesting intellectual pursuit. This paper puts forth a new paradigm, AlphaSeq, to discover desired sequences algorithmically using deep reinforcement learning (DRL) techniques. AlphaSeq treats the sequence discovery problem as an episodic symbol-filling game, in which a player fills symbols in the vacant positions of a sequence set sequentially during an episode of the game. Each episode ends with a completely-filled sequence set, upon which a reward is given based on the desirability of the sequence set. AlphaSeq models the game as a Markov Decision Process (MDP), and adapts the DRL framework of AlphaGo to solve the MDP. Sequences discovered improve progressively as AlphaSeq, starting as a novice, learns to become an expert game player through many episodes of game playing. Compared with traditional sequence construction by mathematical tools, AlphaSeq is particularly suitable for problems with complex objectives intractable to mathematical analysis. We demonstrate the searching capabilities of AlphaSeq in two applications: 1) AlphaSeq successfully rediscovers a set of ideal complementary codes that can zero-force all potential interferences in multi-carrier CDMA systems. 2) AlphaSeq discovers new sequences that triple the signal-to-interference ratio -- benchmarked against the well-known Legendre sequence -- of a mismatched filter estimator in pulse compression radar systems.