 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignCoder: Aligning Retrieval with Target Intent for Repository-Level Code Completion
Jan 27, 2026Repository-level code completion remains a challenging task for existing code large language models (code LLMs) due to their limited understanding of repository-specific context and domain knowledge. While retrieval-augmented generation (RAG) approaches have shown promise by retrieving relevant code snippets as cross-file context, they suffer from two fundamental problems: misalignment between the query and the target code in the retrieval process, and the inability of existing retrieval methods to effectively utilize the inference information. To address these challenges, we propose AlignCoder, a repository-level code completion framework that introduces a query enhancement mechanism and a reinforcement learning based retriever training method. Our approach generates multiple candidate completions to construct an enhanced query that bridges the semantic gap between the initial query and the target code. Additionally, we employ reinforcement learning to train an AlignRetriever that learns to leverage inference information in the enhanced query for more accurate retrieval. We evaluate AlignCoder on two widely-used benchmarks (CrossCodeEval and RepoEval) across five backbone code LLMs, demonstrating an 18.1% improvement in EM score compared to baselines on the CrossCodeEval benchmark. The results show that our framework achieves superior performance and exhibits high generalizability across various code LLMs and programming languages.
ShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code Generation
Jan 14, 2026Code generation tasks aim to automate the conversion of user requirements into executable code, significantly reducing manual development efforts and enhancing software productivity. The emergence of large language models (LLMs) has significantly advanced code generation, though their efficiency is still impacted by certain inherent architectural constraints. Each token generation necessitates a complete inference pass, requiring persistent retention of contextual information in memory and escalating resource consumption. While existing research prioritizes inference-phase optimizations such as prompt compression and model quantization, the generation phase remains underexplored. To tackle these challenges, we propose a knowledge-infused framework named ShortCoder, which optimizes code generation efficiency while preserving semantic equivalence and readability. In particular, we introduce: (1) ten syntax-level simplification rules for Python, derived from AST-preserving transformations, achieving 18.1% token reduction without functional compromise; (2) a hybrid data synthesis pipeline integrating rule-based rewriting with LLM-guided refinement, producing ShorterCodeBench, a corpus of validated tuples of original code and simplified code with semantic consistency; (3) a fine-tuning strategy that injects conciseness awareness into the base LLMs. Extensive experimental results demonstrate that ShortCoder consistently outperforms state-of-the-art methods on HumanEval, achieving an improvement of 18.1%-37.8% in generation efficiency over previous methods while ensuring the performance of code generation.
Harvesting AlphaEarth: Benchmarking the Geospatial Foundation Model for Agricultural Downstream Tasks
Dec 30, 2025Geospatial foundation models (GFMs) have emerged as a promising approach to overcoming the limitations in existing featurization methods. More recently, Google DeepMind has introduced AlphaEarth Foundation (AEF), a GFM pre-trained using multi-source EOs across continuous time. An annual and global embedding dataset is produced using AEF that is ready for analysis and modeling. The internal experiments show that AEF embeddings have outperformed operational models in 15 EO tasks without re-training. However, those experiments are mostly about land cover and land use classification. Applying AEF and other GFMs to agricultural monitoring require an in-depth evaluation in critical agricultural downstream tasks. There is also a lack of comprehensive comparison between the AEF-based models and traditional remote sensing (RS)-based models under different scenarios, which could offer valuable guidance for researchers and practitioners. This study addresses some of these gaps by evaluating AEF embeddings in three agricultural downstream tasks in the U.S., including crop yield prediction, tillage mapping, and cover crop mapping. Datasets are compiled from both public and private sources to comprehensively evaluate AEF embeddings across tasks at different scales and locations, and RS-based models are trained as comparison models. AEF-based models generally exhibit strong performance on all tasks and are competitive with purpose-built RS-based models in yield prediction and county-level tillage mapping when trained on local data. However, we also find several limitations in current AEF embeddings, such as limited spatial transferability compared to RS-based models, low interpretability, and limited time sensitivity. These limitations recommend caution when applying AEF embeddings in agriculture, where time sensitivity, generalizability, and interpretability is important.
UCoder: Unsupervised Code Generation by Internal Probing of Large Language Models
Dec 19, 2025
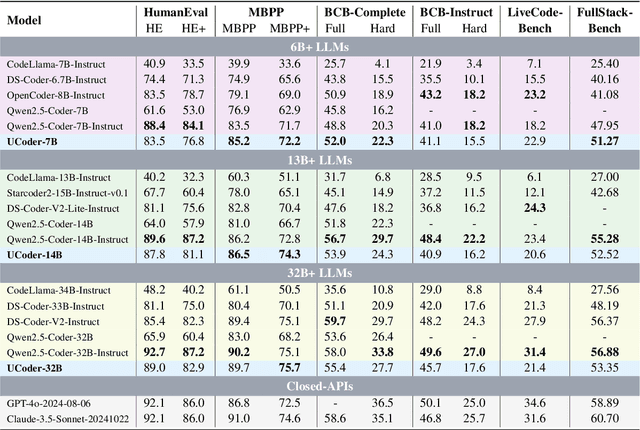
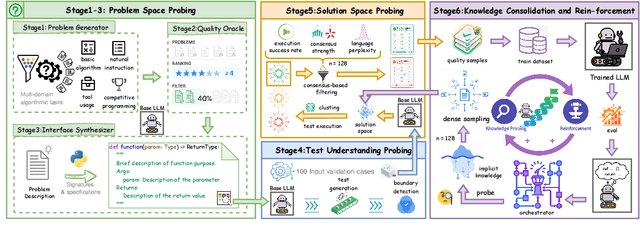
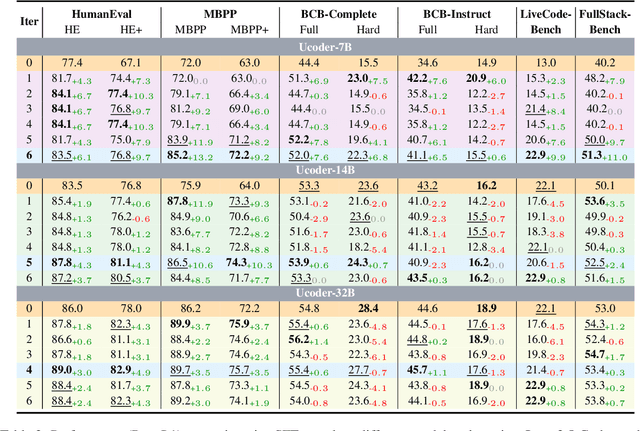
Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, their effectiveness heavily relies on supervised training with extensive labeled (e.g., question-answering pairs) or unlabeled datasets (e.g., code snippets), which are often expensive and difficult to obtain at scale. To address this limitation, this paper introduces a method IPC, an unsupervised framework that leverages Internal Probing of LLMs for Code generation without any external corpus, even unlabeled code snippets. We introduce the problem space probing, test understanding probing, solution space probing, and knowledge consolidation and reinforcement to probe the internal knowledge and confidence patterns existing in LLMs. Further, IPC identifies reliable code candidates through self-consistency mechanisms and representation-based quality estimation to train UCoder (coder with unsupervised learning). We validate the proposed approach across multiple code benchmarks, demonstrating that unsupervised methods can achieve competitive performance compared to supervised approaches while significantly reducing the dependency on labeled data and computational resources. Analytic experiments reveal that internal model states contain rich signals about code quality and correctness, and that properly harnessing these signals enables effective unsupervised learning for code generation tasks, opening new directions for training code LLMs in resource-constrained scenarios.
Towards an Understanding of Context Utilization in Code Intelligence
Apr 11, 2025Code intelligence is an emerging domain in software engineering, aiming to improve the effectiveness and efficiency of various code-related tasks. Recent research suggests that incorporating contextual information beyond the basic original task inputs (i.e., source code) can substantially enhance model performance. Such contextual signals may be obtained directly or indirectly from sources such as API documentation or intermediate representations like abstract syntax trees can significantly improve the effectiveness of code intelligence. Despite growing academic interest, there is a lack of systematic analysis of context in code intelligence. To address this gap, we conduct an extensive literature review of 146 relevant studies published between September 2007 and August 2024. Our investigation yields four main contributions. (1) A quantitative analysis of the research landscape, including publication trends, venues, and the explored domains; (2) A novel taxonomy of context types used in code intelligence; (3) A task-oriented analysis investigating context integration strategies across diverse code intelligence tasks; (4) A critical evaluation of evaluation methodologies for context-aware methods. Based on these findings, we identify fundamental challenges in context utilization in current code intelligence systems and propose a research roadmap that outlines key opportunities for future research.
In-depth Analysis of Graph-based RAG in a Unified Framework
Mar 06, 2025Graph-based Retrieval-Augmented Generation (RAG) has proven effective in integrating external knowledge into large language models (LLMs), improving their factual accuracy, adaptability, interpretability, and trustworthiness. A number of graph-based RAG methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework to incorporate all graph-based RAG methods from a high-level perspective. We then extensively compare representative graph-based RAG methods over a range of questing-answering (QA) datasets -- from specific questions to abstract questions -- and examine the effectiveness of all methods, providing a thorough analysis of graph-based RAG approaches. As a byproduct of our experimental analysis, we are also able to identify new variants of the graph-based RAG methods over specific QA and abstract QA tasks respectively, by combining existing techniques, which outperform the state-of-the-art methods. Finally, based on these findings, we offer promising research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide new valuable insights for future research.
RepoTransBench: A Real-World Benchmark for Repository-Level Code Translation
Dec 23, 2024



Repository-level code translation refers to translating an entire code repository from one programming language to another while preserving the functionality of the source repository. Many benchmarks have been proposed to evaluate the performance of such code translators. However, previous benchmarks mostly provide fine-grained samples, focusing at either code snippet, function, or file-level code translation. Such benchmarks do not accurately reflect real-world demands, where entire repositories often need to be translated, involving longer code length and more complex functionalities. To address this gap, we propose a new benchmark, named RepoTransBench, which is a real-world repository-level code translation benchmark with an automatically executable test suite. We conduct experiments on RepoTransBench to evaluate the translation performance of 11 advanced LLMs. We find that the Success@1 score (test success in one attempt) of the best-performing LLM is only 7.33%. To further explore the potential of LLMs for repository-level code translation, we provide LLMs with error-related feedback to perform iterative debugging and observe an average 7.09% improvement on Success@1. However, even with this improvement, the Success@1 score of the best-performing LLM is only 21%, which may not meet the need for reliable automatic repository-level code translation. Finally, we conduct a detailed error analysis and highlight current LLMs' deficiencies in repository-level code translation, which could provide a reference for further improvements.
Agents in Software Engineering: Survey, Landscape, and Vision
Sep 13, 2024



In recent years, Large Language Models (LLMs) have achieved remarkable success and have been widely used in various downstream tasks, especially in the tasks of the software engineering (SE) field. We find that many studies combining LLMs with SE have employed the concept of agents either explicitly or implicitly. However, there is a lack of an in-depth survey to sort out the development context of existing works, analyze how existing works combine the LLM-based agent technologies to optimize various tasks, and clarify the framework of LLM-based agents in SE. In this paper, we conduct the first survey of the studies on combining LLM-based agents with SE and present a framework of LLM-based agents in SE which includes three key modules: perception, memory, and action. We also summarize the current challenges in combining the two fields and propose future opportunities in response to existing challenges. We maintain a GitHub repository of the related papers at: https://github.com/DeepSoftwareAnalytics/Awesome-Agent4SE.
CodeR: Issue Resolving with Multi-Agent and Task Graphs
Jun 03, 2024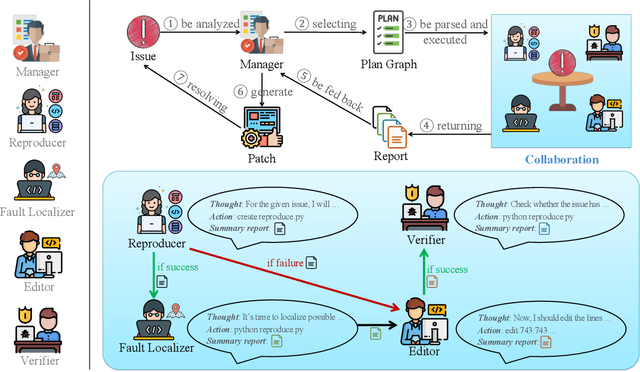
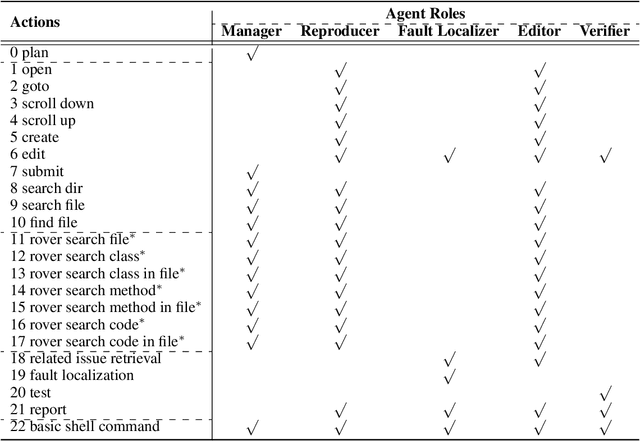

GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.00% of issues, in the case of submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.
Learning county from pixels: Corn yield prediction with attention-weighted multiple instance learning
Dec 02, 2023Remote sensing technology has become a promising tool in yield prediction. Most prior work employs satellite imagery for county-level corn yield prediction by spatially aggregating all pixels within a county into a single value, potentially overlooking the detailed information and valuable insights offered by more granular data. To this end, this research examines each county at the pixel level and applies multiple instance learning to leverage detailed information within a county. In addition, our method addresses the "mixed pixel" issue caused by the inconsistent resolution between feature datasets and crop mask, which may introduce noise into the model and therefore hinder accurate yield prediction. Specifically, the attention mechanism is employed to automatically assign weights to different pixels, which can mitigate the influence of mixed pixels. The experimental results show that the developed model outperforms four other machine learning models over the past five years in the U.S. corn belt and demonstrates its best performance in 2022, achieving a coefficient of determination (R2) value of 0.84 and a root mean square error (RMSE) of 0.83. This paper demonstrates the advantages of our approach from both spatial and temporal perspectives. Furthermore, through an in-depth study of the relationship between mixed pixels and attention, it is verified that our approach can capture critical feature information while filtering out noise from mixed pixels.