 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaguna M.1/XS.2 Technical Report
May 26, 2026We present Laguna M.1 and Laguna XS.2, two Mixture-of-Experts foundation models built for long-horizon, agentic coding: M.1 has $225.8$B total parameters ($23.4$B activated per token) and XS.2 has $33.4$B total ($3$B activated). Both models were trained from scratch end-to-end inside the same internal system that we refer to as our Model Factory: a tightly-integrated stack of versioned data, training, evaluation, and inference components that turn model development into an industrial process. We describe the principles and design choices of the Model Factory and also detail the end-to-end training process of our models, throughout pre-training data and architecture, post-training stages, evaluation, and quantization. On agentic software engineering and terminal benchmarks (SWE-bench Verified, SWE-bench Multilingual, SWE-Bench Pro, and Terminal-Bench 2.0) M.1 and XS.2 are competitive with state-of-the-art open models in their respective weight classes. Laguna XS.2 weights are released under Apache~2.0 at https://huggingface.co/collections/poolside/laguna-xs2.
SparsePO: Controlling Preference Alignment of LLMs via Sparse Token Masks
Oct 07, 2024



Preference Optimization (PO) has proven an effective step for aligning language models to human-desired behaviors. Current variants, following the offline Direct Preference Optimization objective, have focused on a strict setting where all tokens are contributing signals of KL divergence and rewards to the loss function. However, human preference is not affected by each word in a sequence equally but is often dependent on specific words or phrases, e.g. existence of toxic terms leads to non-preferred responses. Based on this observation, we argue that not all tokens should be weighted equally during PO and propose a flexible objective termed SparsePO, that aims to automatically learn to weight the KL divergence and reward corresponding to each token during PO training. We propose two different variants of weight-masks that can either be derived from the reference model itself or learned on the fly. Notably, our method induces sparsity in the learned masks, allowing the model to learn how to best weight reward and KL divergence contributions at the token level, learning an optimal level of mask sparsity. Extensive experiments on multiple domains, including sentiment control, dialogue, text summarization and text-to-code generation, illustrate that our approach assigns meaningful weights to tokens according to the target task, generates more responses with the desired preference and improves reasoning tasks by up to 2 percentage points compared to other token- and response-level PO methods.
Human-like Episodic Memory for Infinite Context LLMs
Jul 12, 2024



Large language models (LLMs) have shown remarkable capabilities, but still struggle with processing extensive contexts, limiting their ability to maintain coherence and accuracy over long sequences. In contrast, the human brain excels at organising and retrieving episodic experiences across vast temporal scales, spanning a lifetime. In this work, we introduce EM-LLM, a novel approach that integrates key aspects of human episodic memory and event cognition into LLMs, enabling them to effectively handle practically infinite context lengths while maintaining computational efficiency. EM-LLM organises sequences of tokens into coherent episodic events using a combination of Bayesian surprise and graph-theoretic boundary refinement in an on-line fashion. When needed, these events are retrieved through a two-stage memory process, combining similarity-based and temporally contiguous retrieval for efficient and human-like access to relevant information. Experiments on the LongBench dataset demonstrate EM-LLM's superior performance, outperforming the state-of-the-art InfLLM model with an overall relative improvement of 4.3% across various tasks, including a 33% improvement on the PassageRetrieval task. Furthermore, our analysis reveals strong correlations between EM-LLM's event segmentation and human-perceived events, suggesting a bridge between this artificial system and its biological counterpart. This work not only advances LLM capabilities in processing extended contexts but also provides a computational framework for exploring human memory mechanisms, opening new avenues for interdisciplinary research in AI and cognitive science.
Text-to-Code Generation with Modality-relative Pre-training
Feb 12, 2024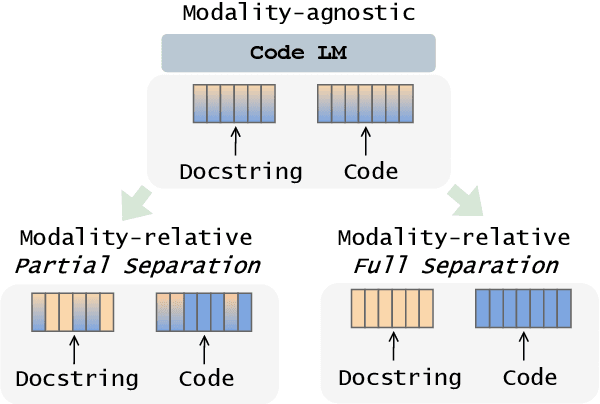



Large pre-trained language models have recently been expanded and applied to programming language tasks with great success, often through further pre-training of a strictly-natural language model--where training sequences typically contain both natural and (linearised) programming language. Such approaches effectively map both modalities of the sequence into the same embedding space. However, programming language keywords (e.g. "while") often have very strictly defined semantics. As such, transfer learning from their natural language usage may not necessarily be beneficial to their code application and vise versa. Assuming an already pre-trained language model, in this work we investigate how sequence tokens can be adapted and represented differently, depending on which modality they belong to, and to the ultimate benefit of the downstream task. We experiment with separating embedding spaces between modalities during further model pre-training with modality-relative training objectives. We focus on text-to-code generation and observe consistent improvements across two backbone models and two test sets, measuring pass@$k$ and a novel incremental variation.
EntityCS: Improving Zero-Shot Cross-lingual Transfer with Entity-Centric Code Switching
Oct 22, 2022Accurate alignment between languages is fundamental for improving cross-lingual pre-trained language models (XLMs). Motivated by the natural phenomenon of code-switching (CS) in multilingual speakers, CS has been used as an effective data augmentation method that offers language alignment at word- or phrase-level, in contrast to sentence-level via parallel instances. Existing approaches either use dictionaries or parallel sentences with word-alignment to generate CS data by randomly switching words in a sentence. However, such methods can be suboptimal as dictionaries disregard semantics, and syntax might become invalid after random word switching. In this work, we propose EntityCS, a method that focuses on Entity-level Code-Switching to capture fine-grained cross-lingual semantics without corrupting syntax. We use Wikidata and the English Wikipedia to construct an entity-centric CS corpus by switching entities to their counterparts in other languages. We further propose entity-oriented masking strategies during intermediate model training on the EntityCS corpus for improving entity prediction. Evaluation of the trained models on four entity-centric downstream tasks shows consistent improvements over the baseline with a notable increase of 10% in Fact Retrieval. We release the corpus and models to assist research on code-switching and enriching XLMs with external knowledge.
Training Dynamics for Curriculum Learning: A Study on Monolingual and Cross-lingual NLU
Oct 22, 2022Curriculum Learning (CL) is a technique of training models via ranking examples in a typically increasing difficulty trend with the aim of accelerating convergence and improving generalisability. Current approaches for Natural Language Understanding (NLU) tasks use CL to improve in-distribution data performance often via heuristic-oriented or task-agnostic difficulties. In this work, instead, we employ CL for NLU by taking advantage of training dynamics as difficulty metrics, i.e., statistics that measure the behavior of the model at hand on specific task-data instances during training and propose modifications of existing CL schedulers based on these statistics. Differently from existing works, we focus on evaluating models on in-distribution (ID), out-of-distribution (OOD) as well as zero-shot (ZS) cross-lingual transfer datasets. We show across several NLU tasks that CL with training dynamics can result in better performance mostly on zero-shot cross-lingual transfer and OOD settings with improvements up by 8.5% in certain cases. Overall, experiments indicate that training dynamics can lead to better performing models with smoother training compared to other difficulty metrics while being 20% faster on average. In addition, through analysis we shed light on the correlations of task-specific versus task-agnostic metrics.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
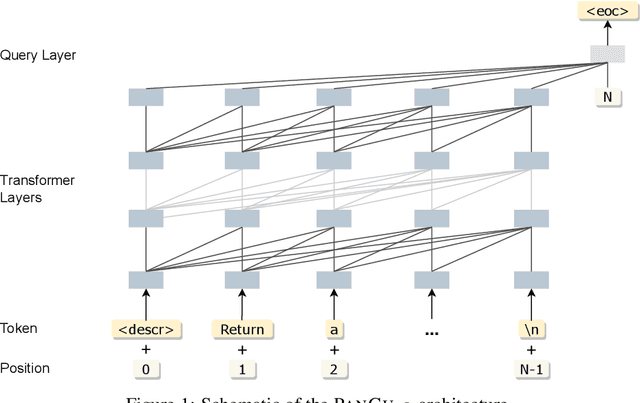
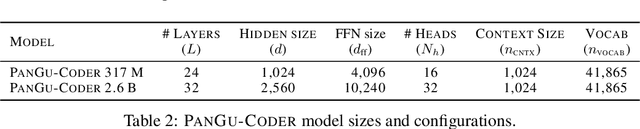
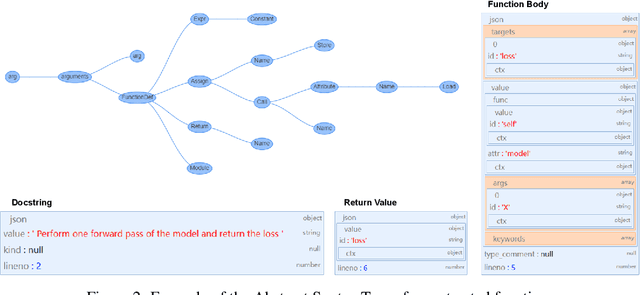
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.
Distantly Supervised Relation Extraction with Sentence Reconstruction and Knowledge Base Priors
Apr 16, 2021
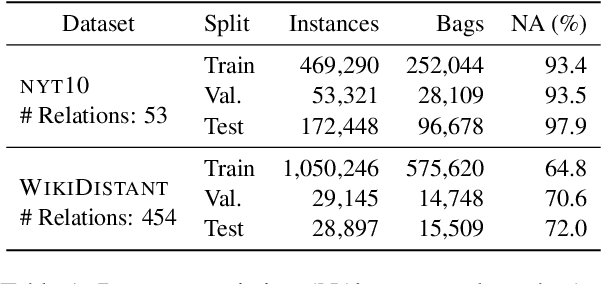
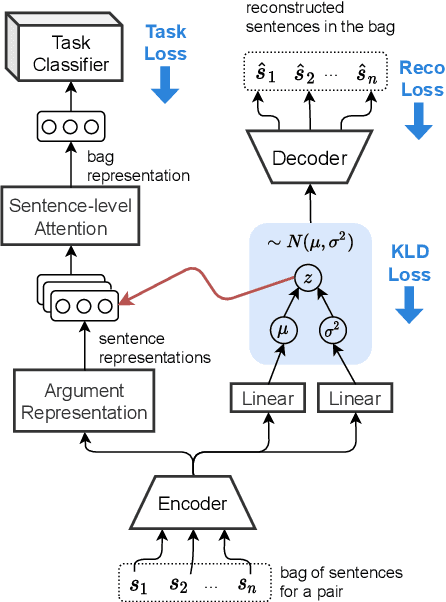
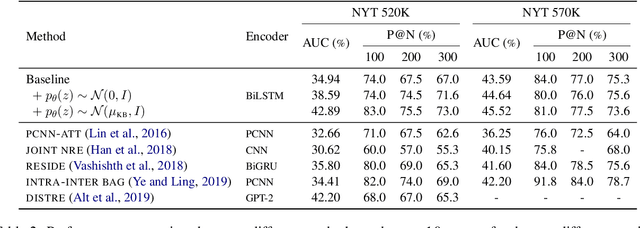
We propose a multi-task, probabilistic approach to facilitate distantly supervised relation extraction by bringing closer the representations of sentences that contain the same Knowledge Base pairs. To achieve this, we bias the latent space of sentences via a Variational Autoencoder (VAE) that is trained jointly with a relation classifier. The latent code guides the pair representations and influences sentence reconstruction. Experimental results on two datasets created via distant supervision indicate that multi-task learning results in performance benefits. Additional exploration of employing Knowledge Base priors into the VAE reveals that the sentence space can be shifted towards that of the Knowledge Base, offering interpretability and further improving results.
Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs
Aug 31, 2019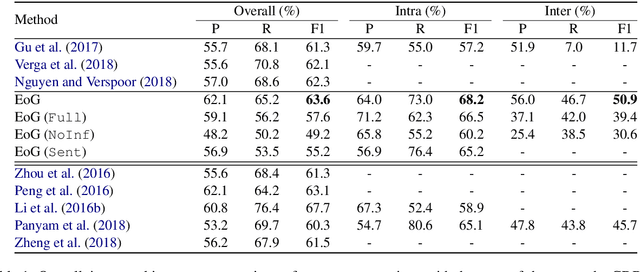
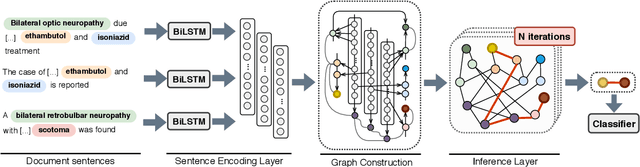
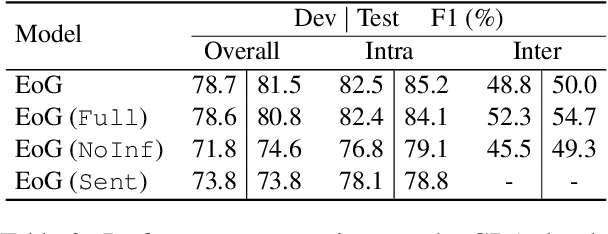
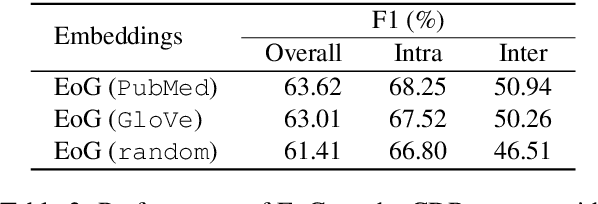
Document-level relation extraction is a complex human process that requires logical inference to extract relationships between named entities in text. Existing approaches use graph-based neural models with words as nodes and edges as relations between them, to encode relations across sentences. These models are node-based, i.e., they form pair representations based solely on the two target node representations. However, entity relations can be better expressed through unique edge representations formed as paths between nodes. We thus propose an edge-oriented graph neural model for document-level relation extraction. The model utilises different types of nodes and edges to create a document-level graph. An inference mechanism on the graph edges enables to learn intra- and inter-sentence relations using multi-instance learning internally. Experiments on two document-level biomedical datasets for chemical-disease and gene-disease associations show the usefulness of the proposed edge-oriented approach.
Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network
Jun 11, 2019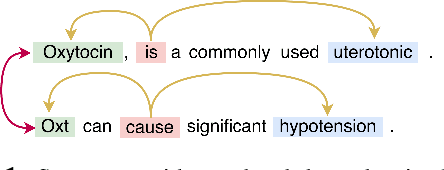
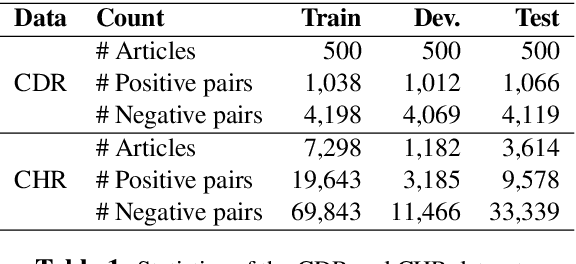
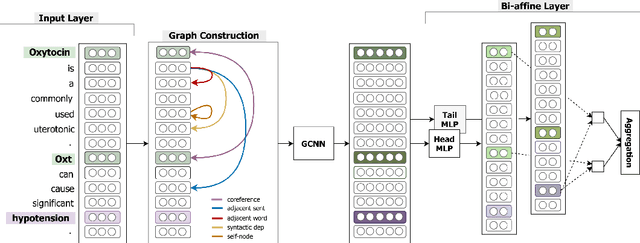
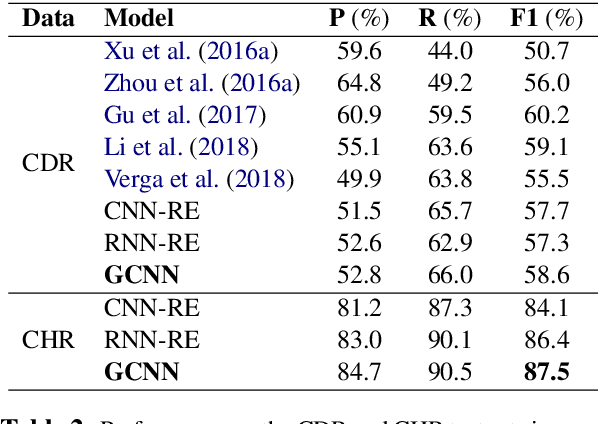
Inter-sentence relation extraction deals with a number of complex semantic relationships in documents, which require local, non-local, syntactic and semantic dependencies. Existing methods do not fully exploit such dependencies. We present a novel inter-sentence relation extraction model that builds a labelled edge graph convolutional neural network model on a document-level graph. The graph is constructed using various inter- and intra-sentence dependencies to capture local and non-local dependency information. In order to predict the relation of an entity pair, we utilise multi-instance learning with bi-affine pairwise scoring. Experimental results show that our model achieves comparable performance to the state-of-the-art neural models on two biochemistry datasets. Our analysis shows that all the types in the graph are effective for inter-sentence relation extraction.