 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Trainable Soft Retriever for Low-resource Relation Extraction
Jun 06, 2024This study addresses a crucial challenge in instance-based relation extraction using text generation models: end-to-end training in target relation extraction task is not applicable to retrievers due to the non-differentiable nature of instance selection. We propose a novel End-to-end TRAinable Soft K-nearest neighbor retriever (ETRASK) by the neural prompting method that utilizes a soft, differentiable selection of the $k$ nearest instances. This approach enables the end-to-end training of retrievers in target tasks. On the TACRED benchmark dataset with a low-resource setting where the training data was reduced to 10\%, our method achieved a state-of-the-art F1 score of 71.5\%. Moreover, ETRASK consistently improved the baseline model by adding instances for all settings. These results highlight the efficacy of our approach in enhancing relation extraction performance, especially in resource-constrained environments. Our findings offer a promising direction for future research with extraction and the broader application of text generation in natural language processing.
Span-based Named Entity Recognition by Generating and Compressing Information
Feb 10, 2023The information bottleneck (IB) principle has been proven effective in various NLP applications. The existing work, however, only used either generative or information compression models to improve the performance of the target task. In this paper, we propose to combine the two types of IB models into one system to enhance Named Entity Recognition (NER). For one type of IB model, we incorporate two unsupervised generative components, span reconstruction and synonym generation, into a span-based NER system. The span reconstruction ensures that the contextualised span representation keeps the span information, while the synonym generation makes synonyms have similar representations even in different contexts. For the other type of IB model, we add a supervised IB layer that performs information compression into the system to preserve useful features for NER in the resulting span representations. Experiments on five different corpora indicate that jointly training both generative and information compression models can enhance the performance of the baseline span-based NER system. Our source code is publicly available at https://github.com/nguyennth/joint-ib-models.
Learning Disentangled Representations of Negation and Uncertainty
Apr 01, 2022
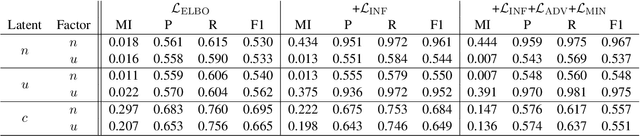

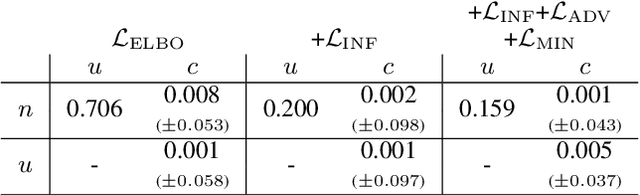
Negation and uncertainty modeling are long-standing tasks in natural language processing. Linguistic theory postulates that expressions of negation and uncertainty are semantically independent from each other and the content they modify. However, previous works on representation learning do not explicitly model this independence. We therefore attempt to disentangle the representations of negation, uncertainty, and content using a Variational Autoencoder. We find that simply supervising the latent representations results in good disentanglement, but auxiliary objectives based on adversarial learning and mutual information minimization can provide additional disentanglement gains.
Physical Context and Timing Aware Sequence Generating GANs
Sep 28, 2021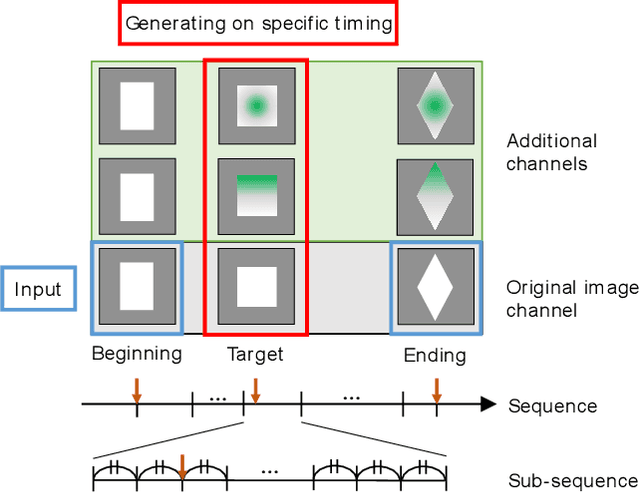
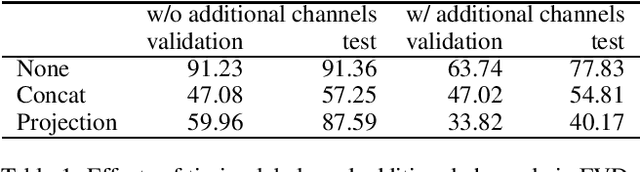
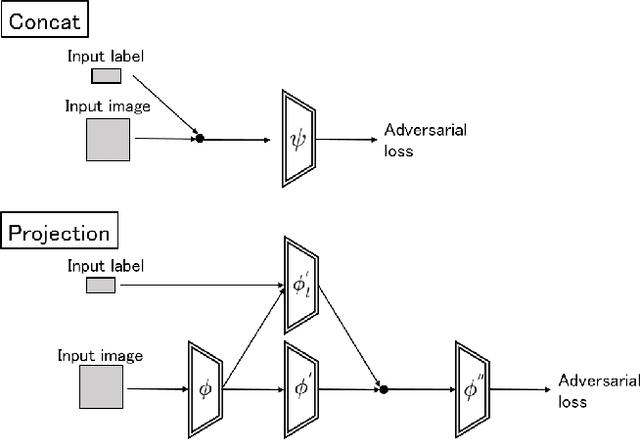
Generative Adversarial Networks (GANs) have shown remarkable successes in generating realistic images and interpolating changes between images. Existing models, however, do not take into account physical contexts behind images in generating the images, which may cause unrealistic changes. Furthermore, it is difficult to generate the changes at a specific timing and they often do not match with actual changes. This paper proposes a novel GAN, named Physical Context and Timing aware sequence generating GANs (PCTGAN), that generates an image in a sequence at a specific timing between two images with considering physical contexts behind them. Our method consists of three components: an encoder, a generator, and a discriminator. The encoder estimates latent vectors from the beginning and ending images, their timings, and a target timing. The generator generates images and the physical contexts at the beginning, ending, and target timing from the corresponding latent vectors. The discriminator discriminates whether the generated images and contexts are real or not. In the experiments, PCTGAN is applied to a data set of sequential changes of shapes in die forging processes. We show that both timing and physical contexts are effective in generating sequential images.
Analyzing Research Trends in Inorganic Materials Literature Using NLP
Jun 27, 2021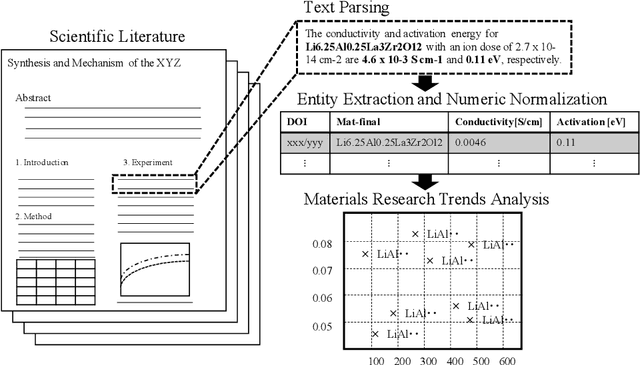
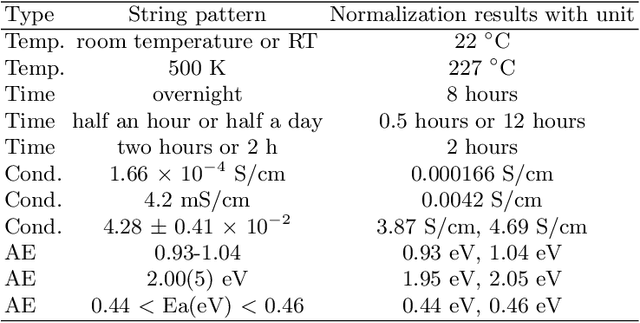
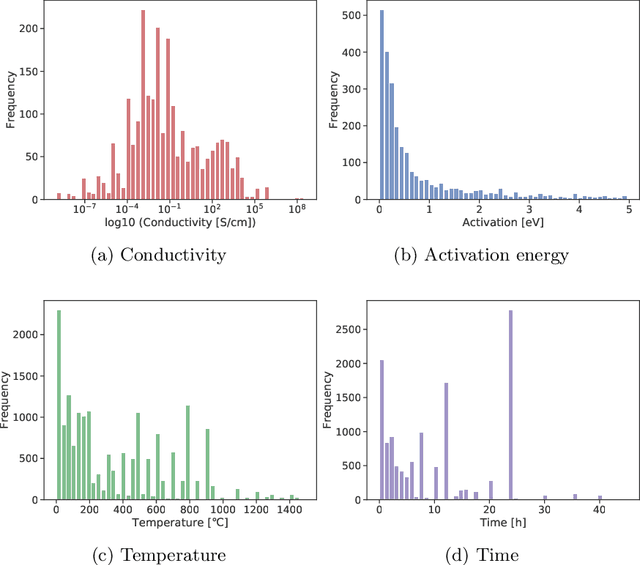

In the field of inorganic materials science, there is a growing demand to extract knowledge such as physical properties and synthesis processes of materials by machine-reading a large number of papers. This is because materials researchers refer to many papers in order to come up with promising terms of experiments for material synthesis. However, there are only a few systems that can extract material names and their properties. This study proposes a large-scale natural language processing (NLP) pipeline for extracting material names and properties from materials science literature to enable the search and retrieval of results in materials science. Therefore, we propose a label definition for extracting material names and properties and accordingly build a corpus containing 836 annotated paragraphs extracted from 301 papers for training a named entity recognition (NER) model. Experimental results demonstrate the utility of this NER model; it achieves successful extraction with a micro-F1 score of 78.1%. To demonstrate the efficacy of our approach, we present a thorough evaluation on a real-world automatically annotated corpus by applying our trained NER model to 12,895 materials science papers. We analyze the trend in materials science by visualizing the outputs of the NLP pipeline. For example, the country-by-year analysis indicates that in recent years, the number of papers on "MoS2," a material used in perovskite solar cells, has been increasing rapidly in China but decreasing in the United States. Further, according to the conditions-by-year analysis, the processing temperature of the catalyst material "PEDOT:PSS" is shifting below 200 degree, and the number of reports with a processing time exceeding 5 h is increasing slightly.
A Neural Edge-Editing Approach for Document-Level Relation Graph Extraction
Jun 18, 2021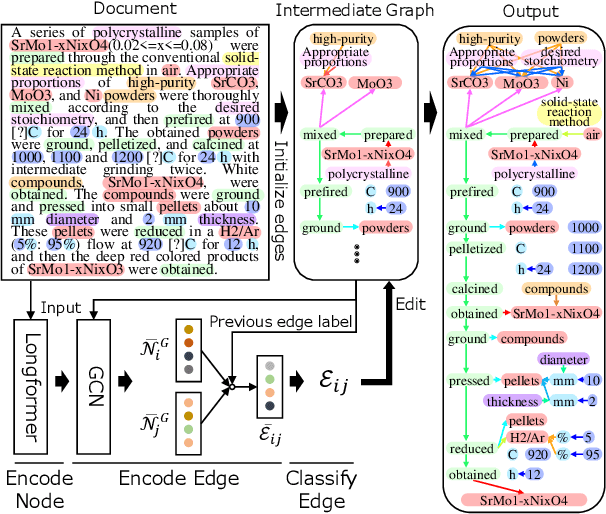

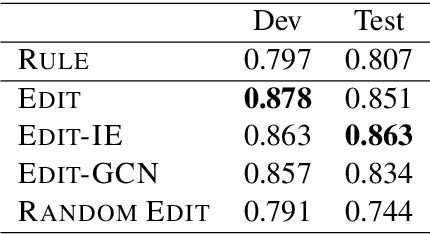
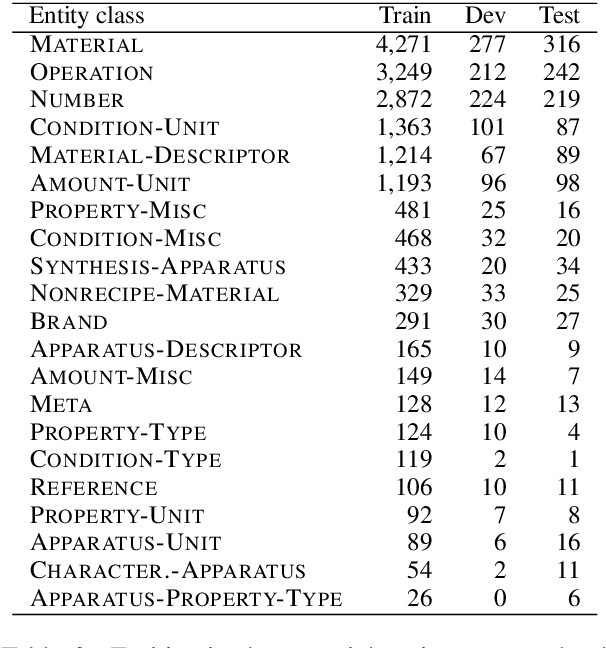
In this paper, we propose a novel edge-editing approach to extract relation information from a document. We treat the relations in a document as a relation graph among entities in this approach. The relation graph is iteratively constructed by editing edges of an initial graph, which might be a graph extracted by another system or an empty graph. The way to edit edges is to classify them in a close-first manner using the document and temporally-constructed graph information; each edge is represented with a document context information by a pretrained transformer model and a graph context information by a graph convolutional neural network model. We evaluate our approach on the task to extract material synthesis procedures from materials science texts. The experimental results show the effectiveness of our approach in editing the graphs initialized by our in-house rule-based system and empty graphs.
Distantly Supervised Relation Extraction with Sentence Reconstruction and Knowledge Base Priors
Apr 16, 2021
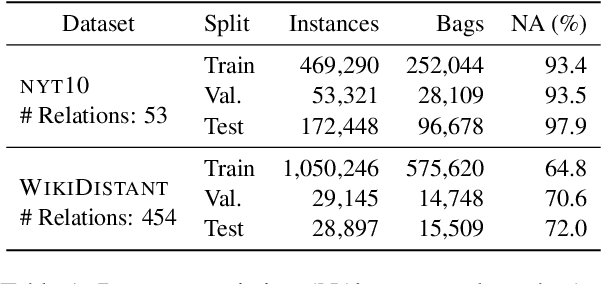
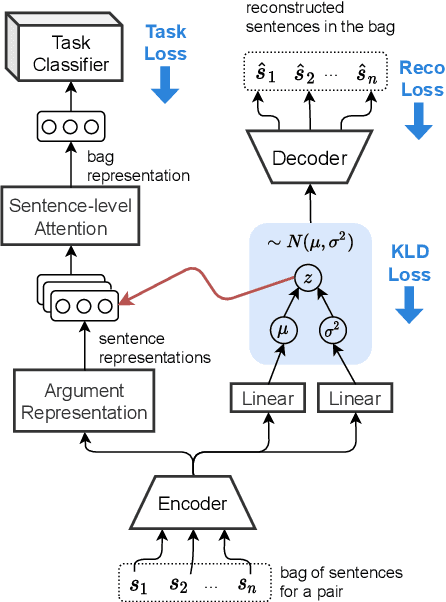
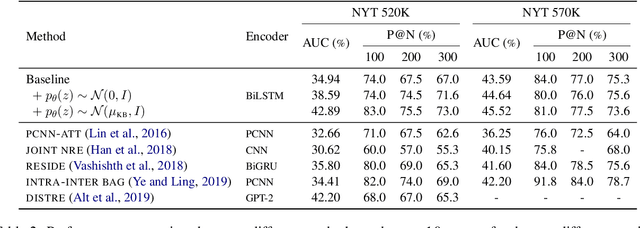
We propose a multi-task, probabilistic approach to facilitate distantly supervised relation extraction by bringing closer the representations of sentences that contain the same Knowledge Base pairs. To achieve this, we bias the latent space of sentences via a Variational Autoencoder (VAE) that is trained jointly with a relation classifier. The latent code guides the pair representations and influences sentence reconstruction. Experimental results on two datasets created via distant supervision indicate that multi-task learning results in performance benefits. Additional exploration of employing Knowledge Base priors into the VAE reveals that the sentence space can be shifted towards that of the Knowledge Base, offering interpretability and further improving results.
Annotating and Extracting Synthesis Process of All-Solid-State Batteries from Scientific Literature
Feb 18, 2020
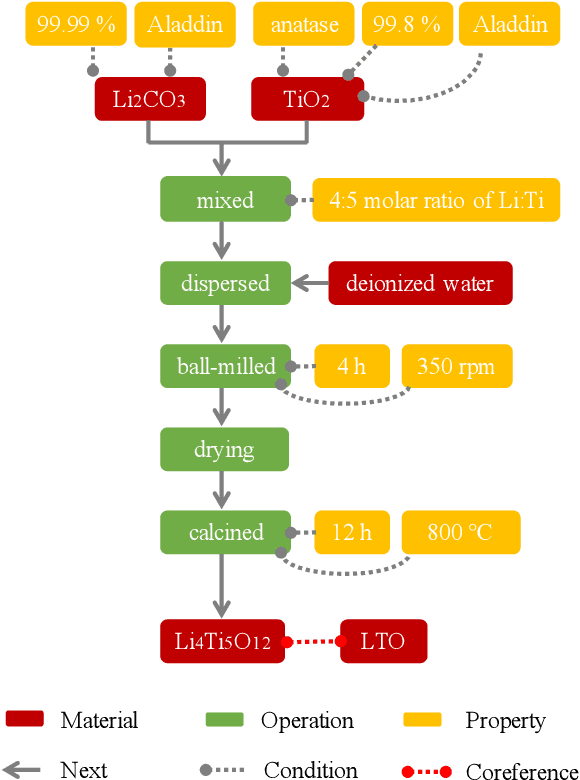

The synthesis process is essential for achieving computational experiment design in the field of inorganic materials chemistry. In this work, we present a novel corpus of the synthesis process for all-solid-state batteries and an automated machine reading system for extracting the synthesis processes buried in the scientific literature. We define the representation of the synthesis processes using flow graphs, and create a corpus from the experimental sections of 243 papers. The automated machine-reading system is developed by a deep learning-based sequence tagger and simple heuristic rule-based relation extractor. Our experimental results demonstrate that the sequence tagger with the optimal setting can detect the entities with a macro-averaged F1 score of 0.826, while the rule-based relation extractor can achieve high performance with a macro-averaged F1 score of 0.887.
A Search-based Neural Model for Biomedical Nested and Overlapping Event Detection
Oct 25, 2019
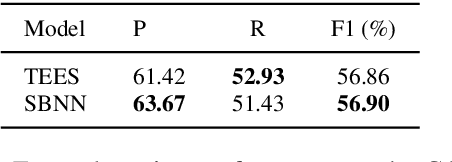

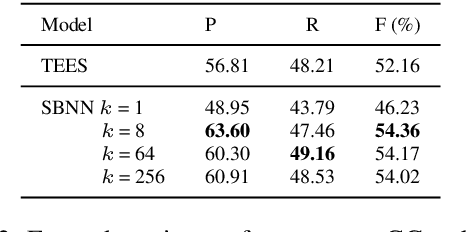
We tackle the nested and overlapping event detection task and propose a novel search-based neural network (SBNN) structured prediction model that treats the task as a search problem on a relation graph of trigger-argument structures. Unlike existing structured prediction tasks such as dependency parsing, the task targets to detect DAG structures, which constitute events, from the relation graph. We define actions to construct events and use all the beams in a beam search to detect all event structures that may be overlapping and nested. The search process constructs events in a bottom-up manner while modelling the global properties for nested and overlapping structures simultaneously using neural networks. We show that the model achieves performance comparable to the state-of-the-art model Turku Event Extraction System (TEES) on the BioNLP Cancer Genetics (CG) Shared Task 2013 without the use of any syntactic and hand-engineered features. Further analyses on the development set show that our model is more computationally efficient while yielding higher F1-score performance.
Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs
Aug 31, 2019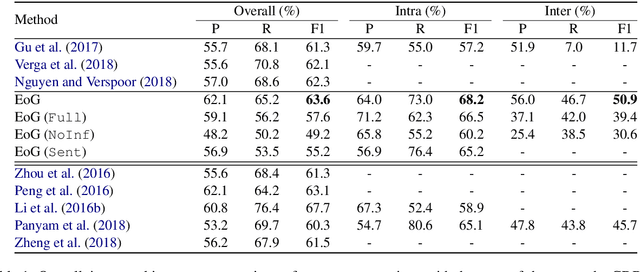
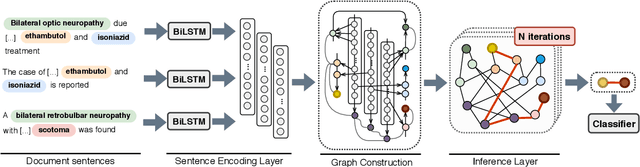
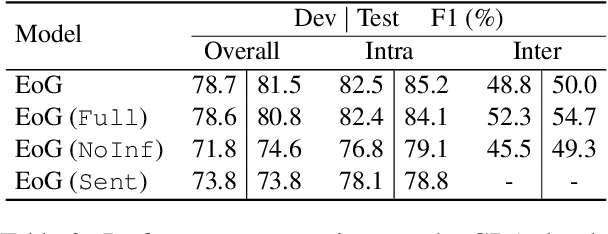
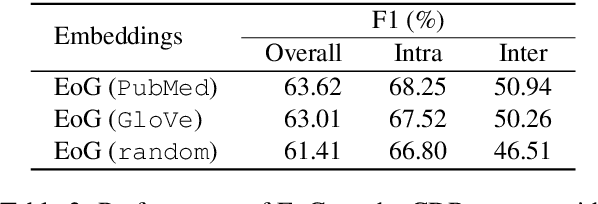
Document-level relation extraction is a complex human process that requires logical inference to extract relationships between named entities in text. Existing approaches use graph-based neural models with words as nodes and edges as relations between them, to encode relations across sentences. These models are node-based, i.e., they form pair representations based solely on the two target node representations. However, entity relations can be better expressed through unique edge representations formed as paths between nodes. We thus propose an edge-oriented graph neural model for document-level relation extraction. The model utilises different types of nodes and edges to create a document-level graph. An inference mechanism on the graph edges enables to learn intra- and inter-sentence relations using multi-instance learning internally. Experiments on two document-level biomedical datasets for chemical-disease and gene-disease associations show the usefulness of the proposed edge-oriented approach.