 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple is not Enough: Document-level Text Simplification using Readability and Coherence
Dec 24, 2024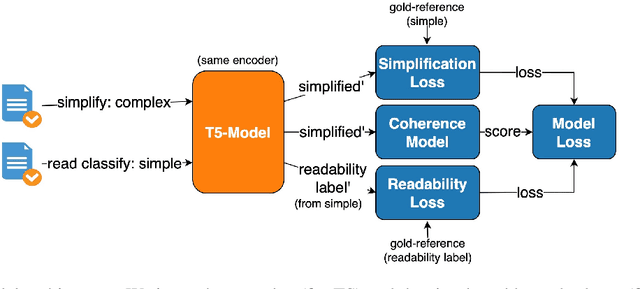

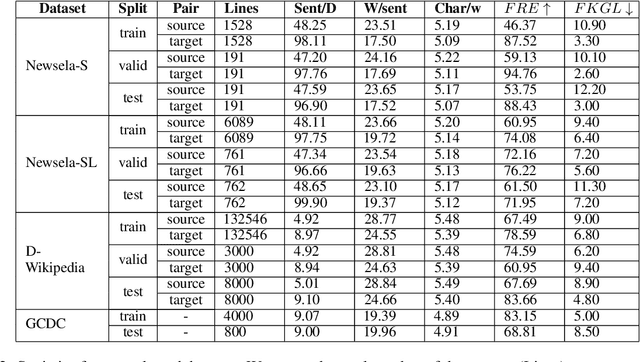
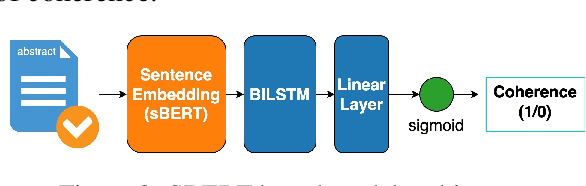
In this paper, we present the SimDoc system, a simplification model considering simplicity, readability, and discourse aspects, such as coherence. In the past decade, the progress of the Text Simplification (TS) field has been mostly shown at a sentence level, rather than considering paragraphs or documents, a setting from which most TS audiences would benefit. We propose a simplification system that is initially fine-tuned with professionally created corpora. Further, we include multiple objectives during training, considering simplicity, readability, and coherence altogether. Our contributions include the extension of professionally annotated simplification corpora by the association of existing annotations into (complex text, simple text, readability label) triples to benefit from readability during training. Also, we present a comparative analysis in which we evaluate our proposed models in a zero-shot, few-shot, and fine-tuning setting using document-level TS corpora, demonstrating novel methods for simplification. Finally, we show a detailed analysis of outputs, highlighting the difficulties of simplification at a document level.
Span-based Named Entity Recognition by Generating and Compressing Information
Feb 10, 2023The information bottleneck (IB) principle has been proven effective in various NLP applications. The existing work, however, only used either generative or information compression models to improve the performance of the target task. In this paper, we propose to combine the two types of IB models into one system to enhance Named Entity Recognition (NER). For one type of IB model, we incorporate two unsupervised generative components, span reconstruction and synonym generation, into a span-based NER system. The span reconstruction ensures that the contextualised span representation keeps the span information, while the synonym generation makes synonyms have similar representations even in different contexts. For the other type of IB model, we add a supervised IB layer that performs information compression into the system to preserve useful features for NER in the resulting span representations. Experiments on five different corpora indicate that jointly training both generative and information compression models can enhance the performance of the baseline span-based NER system. Our source code is publicly available at https://github.com/nguyennth/joint-ib-models.