 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple is not Enough: Document-level Text Simplification using Readability and Coherence
Dec 24, 2024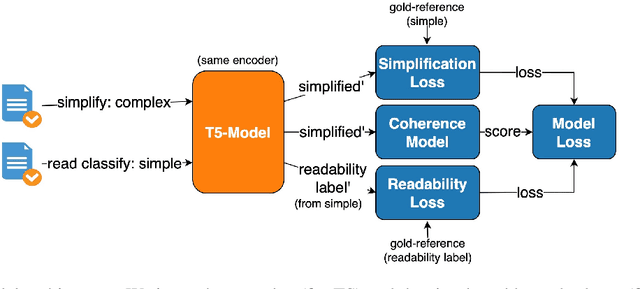

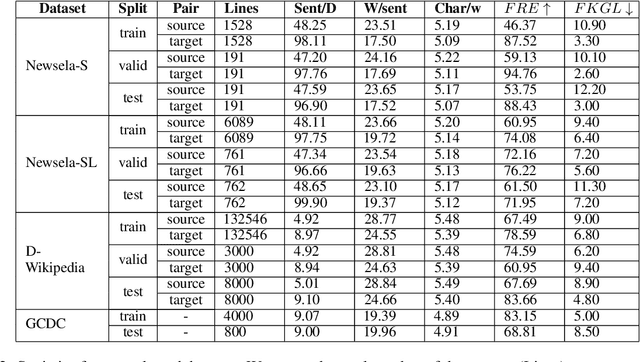
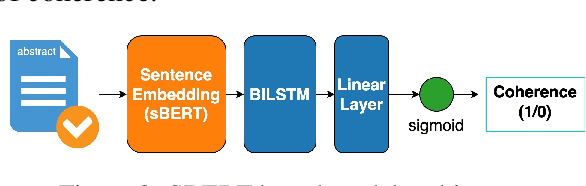
In this paper, we present the SimDoc system, a simplification model considering simplicity, readability, and discourse aspects, such as coherence. In the past decade, the progress of the Text Simplification (TS) field has been mostly shown at a sentence level, rather than considering paragraphs or documents, a setting from which most TS audiences would benefit. We propose a simplification system that is initially fine-tuned with professionally created corpora. Further, we include multiple objectives during training, considering simplicity, readability, and coherence altogether. Our contributions include the extension of professionally annotated simplification corpora by the association of existing annotations into (complex text, simple text, readability label) triples to benefit from readability during training. Also, we present a comparative analysis in which we evaluate our proposed models in a zero-shot, few-shot, and fine-tuning setting using document-level TS corpora, demonstrating novel methods for simplification. Finally, we show a detailed analysis of outputs, highlighting the difficulties of simplification at a document level.
Attacking Misinformation Detection Using Adversarial Examples Generated by Language Models
Oct 28, 2024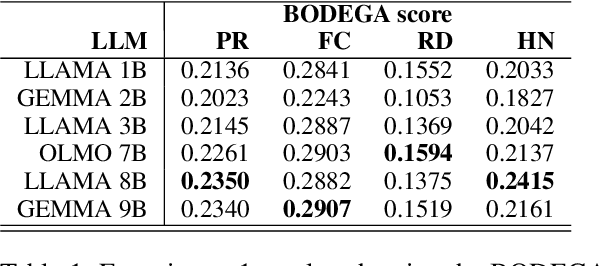

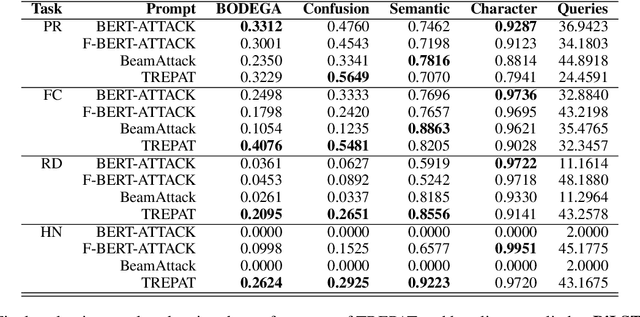
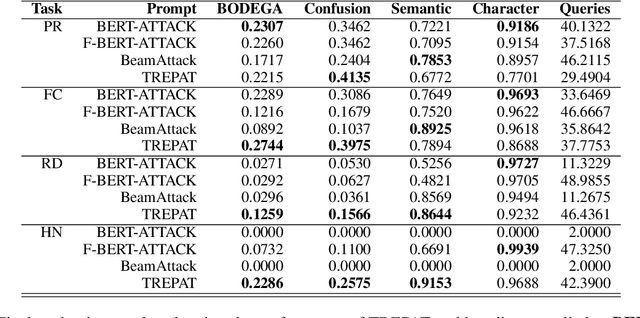
We investigate the challenge of generating adversarial examples to test the robustness of text classification algorithms detecting low-credibility content, including propaganda, false claims, rumours and hyperpartisan news. We focus on simulation of content moderation by setting realistic limits on the number of queries an attacker is allowed to attempt. Within our solution (TREPAT), initial rephrasings are generated by large language models with prompts inspired by meaning-preserving NLP tasks, e.g. text simplification and style transfer. Subsequently, these modifications are decomposed into small changes, applied through beam search procedure until the victim classifier changes its decision. The evaluation confirms the superiority of our approach in the constrained scenario, especially in case of long input text (news articles), where exhaustive search is not feasible.
BODEGA: Benchmark for Adversarial Example Generation in Credibility Assessment
Mar 14, 2023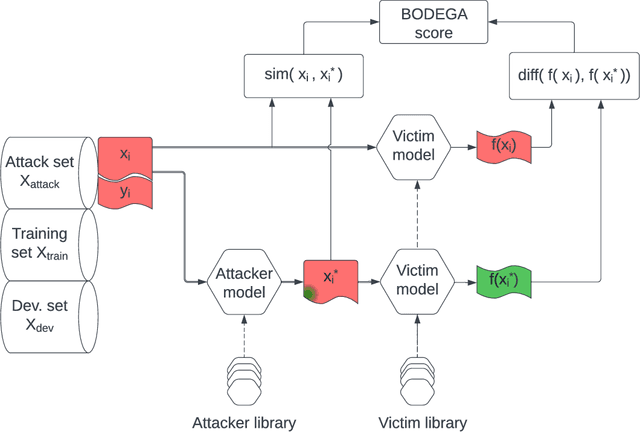
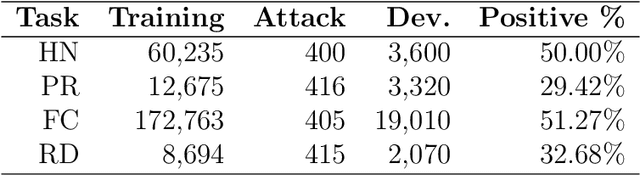

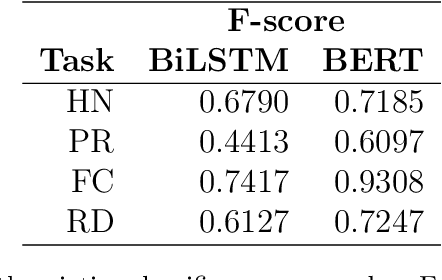
Text classification methods have been widely investigated as a way to detect content of low credibility: fake news, social media bots, propaganda, etc. Quite accurate models (likely based on deep neural networks) help in moderating public electronic platforms and often cause content creators to face rejection of their submissions or removal of already published texts. Having the incentive to evade further detection, content creators try to come up with a slightly modified version of the text (known as an attack with an adversarial example) that exploit the weaknesses of classifiers and result in a different output. Here we introduce BODEGA: a benchmark for testing both victim models and attack methods on four misinformation detection tasks in an evaluation framework designed to simulate real use-cases of content moderation. We also systematically test the robustness of popular text classifiers against available attacking techniques and discover that, indeed, in some cases barely significant changes in input text can mislead the models. We openly share the BODEGA code and data in hope of enhancing the comparability and replicability of further research in this area.
Improving Question Answering Performance through Manual Annotation: Costs, Benefits and Strategies
Dec 17, 2022



Recently proposed systems for open-domain question answering (OpenQA) require large amounts of training data to achieve state-of-the-art performance. However, data annotation is known to be time-consuming and therefore expensive to acquire. As a result, the appropriate datasets are available only for a handful of languages (mainly English and Chinese). In this work, we introduce and publicly release PolQA, the first Polish dataset for OpenQA. It consists of 7,000 questions, 87,525 manually labeled evidence passages, and a corpus of over 7,097,322 candidate passages. Each question is classified according to its formulation, type, as well as entity type of the answer. This resource allows us to evaluate the impact of different annotation choices on the performance of the QA system and propose an efficient annotation strategy that increases the passage retrieval performance by 10.55 p.p. while reducing the annotation cost by 82%.
Deanthropomorphising NLP: Can a Language Model Be Conscious?
Nov 21, 2022
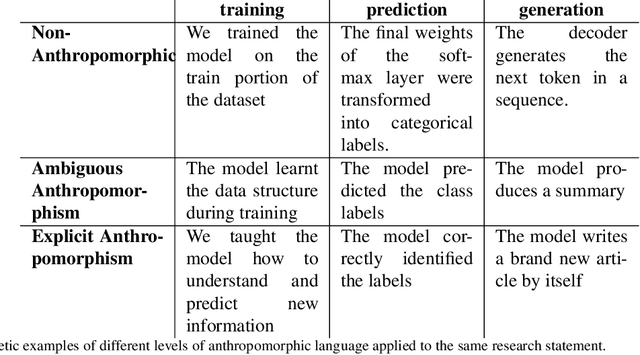
This work is intended as a voice in the discussion over the recent claims that LaMDA, a pretrained language model based on the Transformer model architecture, is sentient. This claim, if confirmed, would have serious ramifications in the Natural Language Processing (NLP) community due to wide-spread use of similar models. However, here we take the position that such a language model cannot be sentient, or conscious, and that LaMDA in particular exhibits no advances over other similar models that would qualify it. We justify this by analysing the Transformer architecture through Integrated Information Theory. We see the claims of consciousness as part of a wider tendency to use anthropomorphic language in NLP reporting. Regardless of the veracity of the claims, we consider this an opportune moment to take stock of progress in language modelling and consider the ethical implications of the task. In order to make this work helpful for readers outside the NLP community, we also present the necessary background in language modelling.
Investigating Text Simplification Evaluation
Jul 28, 2021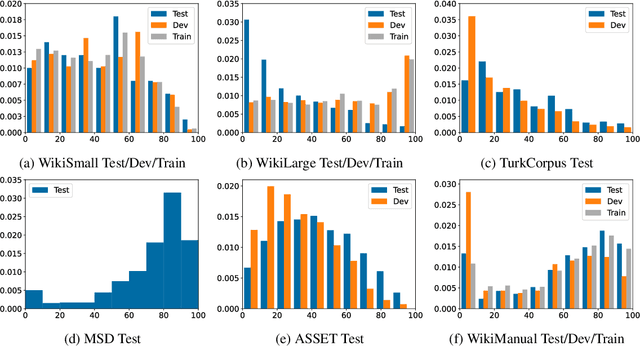
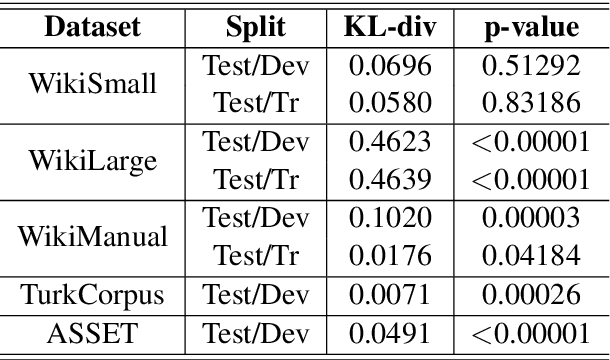
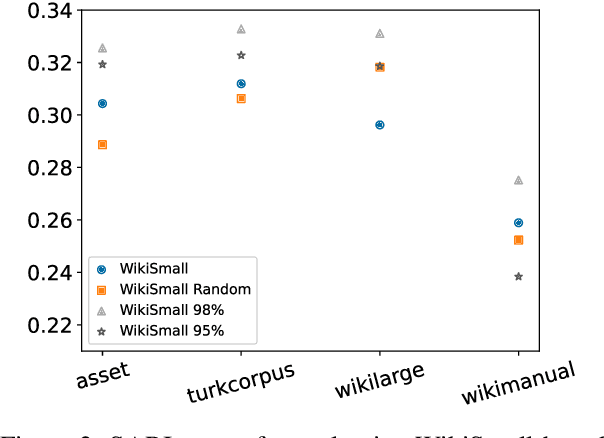
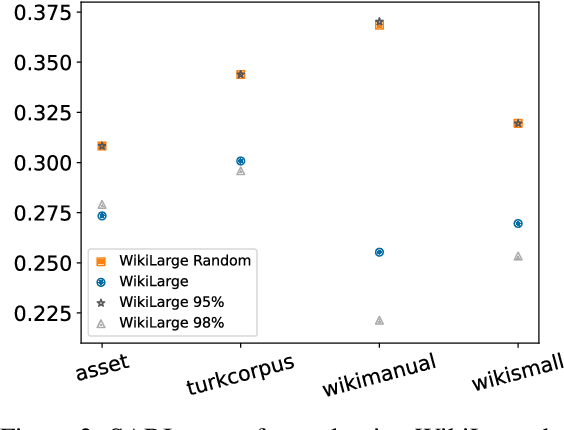
Modern text simplification (TS) heavily relies on the availability of gold standard data to build machine learning models. However, existing studies show that parallel TS corpora contain inaccurate simplifications and incorrect alignments. Additionally, evaluation is usually performed by using metrics such as BLEU or SARI to compare system output to the gold standard. A major limitation is that these metrics do not match human judgements and the performance on different datasets and linguistic phenomena vary greatly. Furthermore, our research shows that the test and training subsets of parallel datasets differ significantly. In this work, we investigate existing TS corpora, providing new insights that will motivate the improvement of existing state-of-the-art TS evaluation methods. Our contributions include the analysis of TS corpora based on existing modifications used for simplification and an empirical study on TS models performance by using better-distributed datasets. We demonstrate that by improving the distribution of TS datasets, we can build more robust TS models.
* 7 pages, 3 figures, 1 table
How big is big enough? Unsupervised word sense disambiguation using a very large corpus
Oct 22, 2017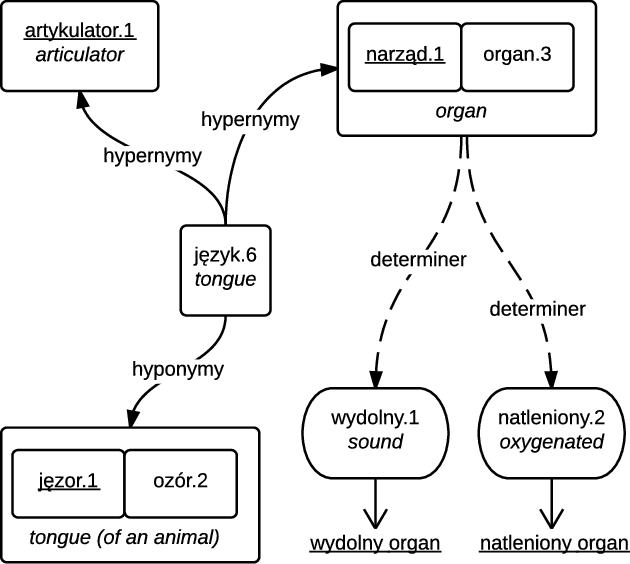

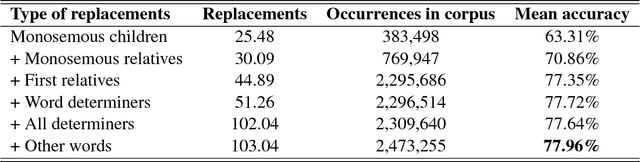
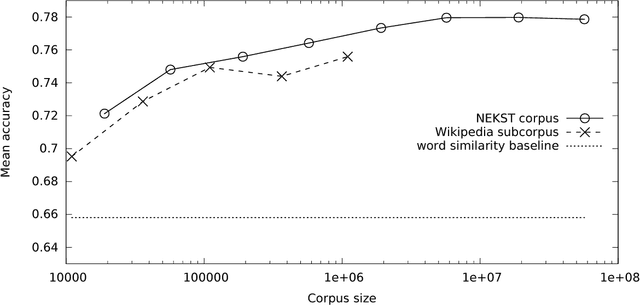
In this paper, the problem of disambiguating a target word for Polish is approached by searching for related words with known meaning. These relatives are used to build a training corpus from unannotated text. This technique is improved by proposing new rich sources of replacements that substitute the traditional requirement of monosemy with heuristics based on wordnet relations. The na\"ive Bayesian classifier has been modified to account for an unknown distribution of senses. A corpus of 600 million web documents (594 billion tokens), gathered by the NEKST search engine allows us to assess the relationship between training set size and disambiguation accuracy. The classifier is evaluated using both a wordnet baseline and a corpus with 17,314 manually annotated occurrences of 54 ambiguous words.
Boosting Question Answering by Deep Entity Recognition
May 27, 2016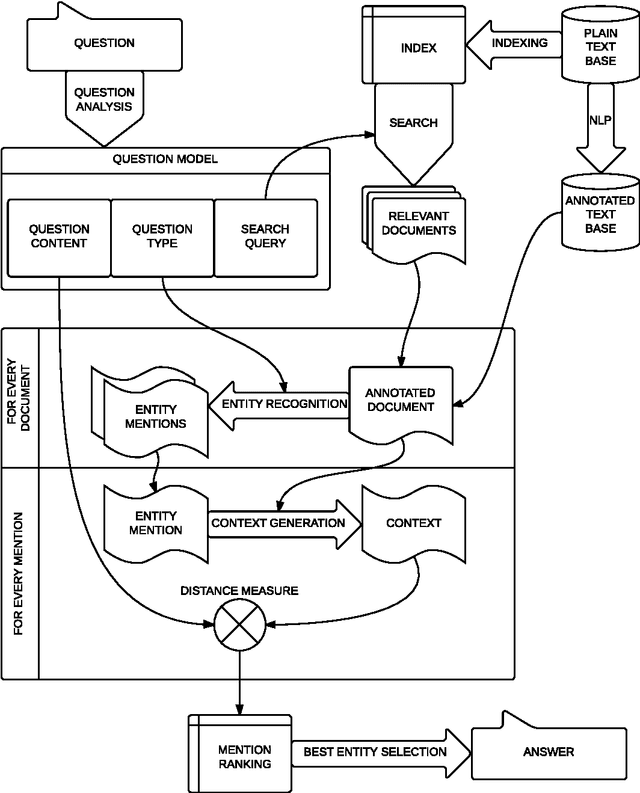
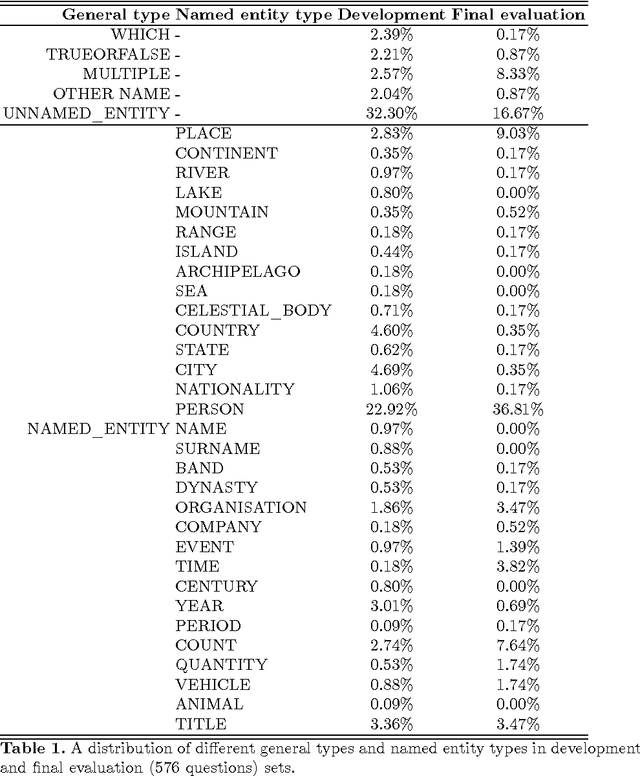


In this paper an open-domain factoid question answering system for Polish, RAFAEL, is presented. The system goes beyond finding an answering sentence; it also extracts a single string, corresponding to the required entity. Herein the focus is placed on different approaches to entity recognition, essential for retrieving information matching question constraints. Apart from traditional approach, including named entity recognition (NER) solutions, a novel technique, called Deep Entity Recognition (DeepER), is introduced and implemented. It allows a comprehensive search of all forms of entity references matching a given WordNet synset (e.g. an impressionist), based on a previously assembled entity library. It has been created by analysing the first sentences of encyclopaedia entries and disambiguation and redirect pages. DeepER also provides automatic evaluation, which makes possible numerous experiments, including over a thousand questions from a quiz TV show answered on the grounds of Polish Wikipedia. The final results of a manual evaluation on a separate question set show that the strength of DeepER approach lies in its ability to answer questions that demand answers beyond the traditional categories of named entities.