 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLLuM: A Family of Polish Large Language Models
Nov 05, 2025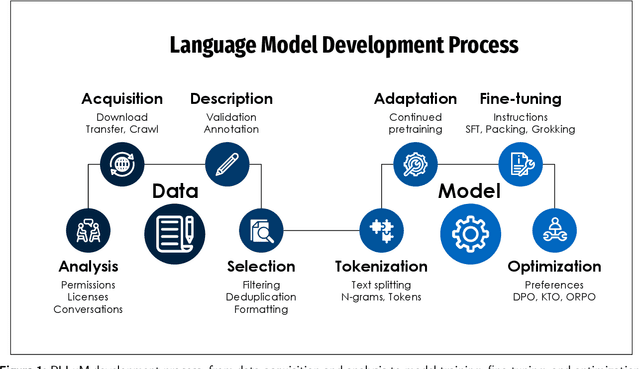
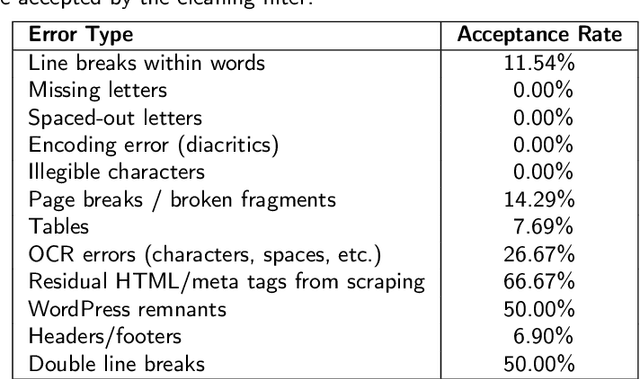
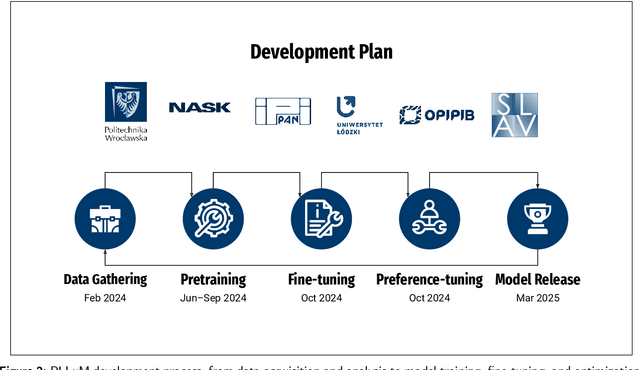

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
NeoN: A Tool for Automated Detection, Linguistic and LLM-Driven Analysis of Neologisms in Polish
May 21, 2025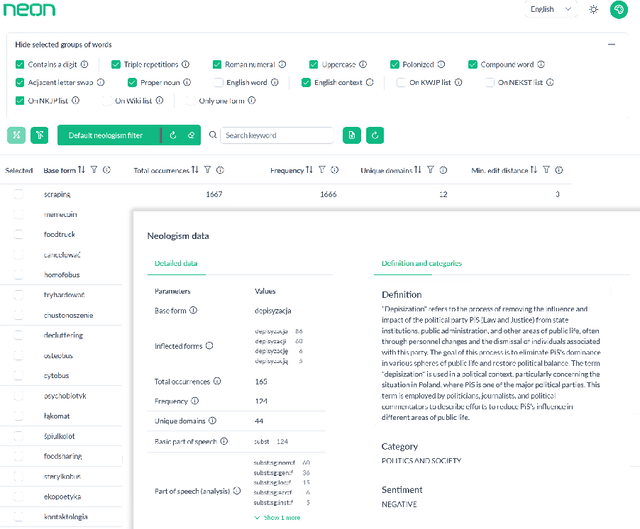
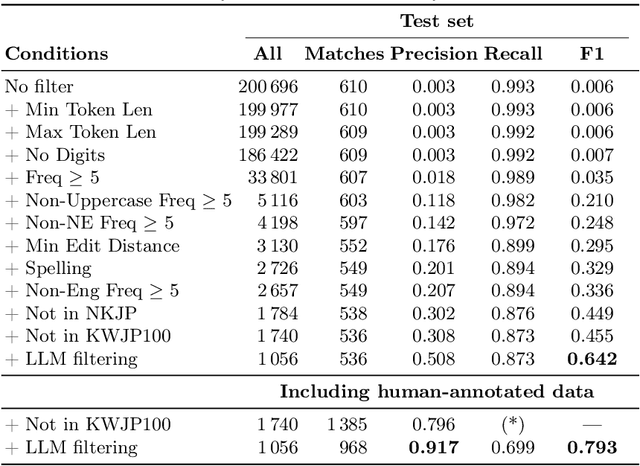
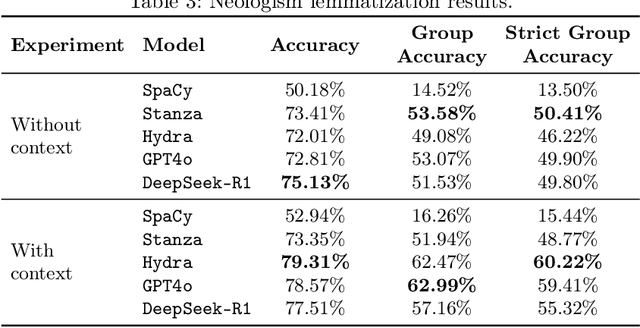
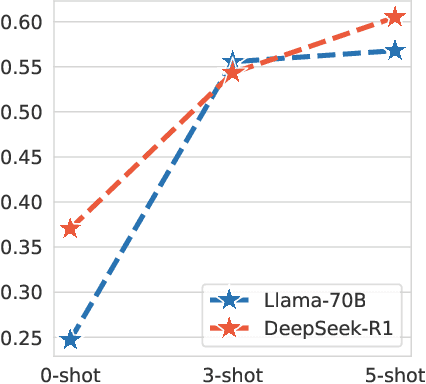
NeoN, a tool for detecting and analyzing Polish neologisms. Unlike traditional dictionary-based methods requiring extensive manual review, NeoN combines reference corpora, Polish-specific linguistic filters, an LLM-driven precision-boosting filter, and daily RSS monitoring in a multi-layered pipeline. The system uses context-aware lemmatization, frequency analysis, and orthographic normalization to extract candidate neologisms while consolidating inflectional variants. Researchers can verify candidates through an intuitive interface with visualizations and filtering controls. An integrated LLM module automatically generates definitions and categorizes neologisms by domain and sentiment. Evaluations show NeoN maintains high accuracy while significantly reducing manual effort, providing an accessible solution for tracking lexical innovation in Polish.
SilverRetriever: Advancing Neural Passage Retrieval for Polish Question Answering
Sep 15, 2023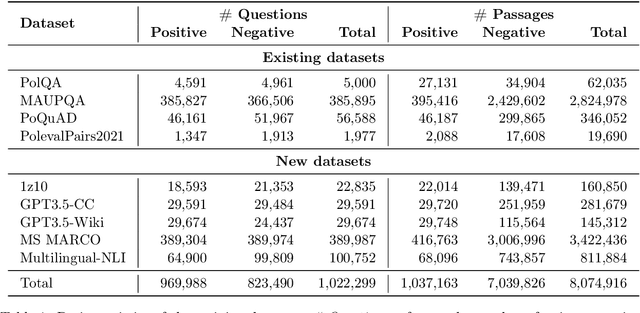
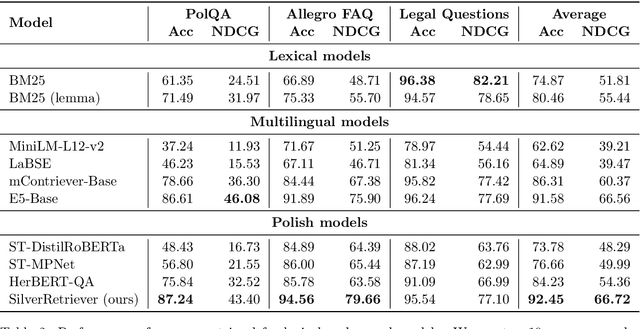
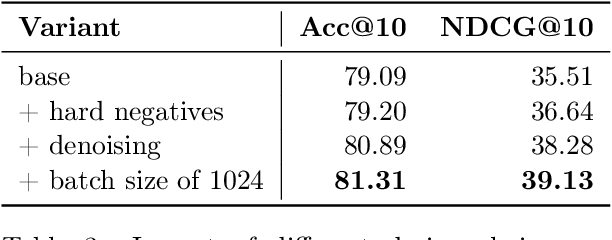
Modern open-domain question answering systems often rely on accurate and efficient retrieval components to find passages containing the facts necessary to answer the question. Recently, neural retrievers have gained popularity over lexical alternatives due to their superior performance. However, most of the work concerns popular languages such as English or Chinese. For others, such as Polish, few models are available. In this work, we present SilverRetriever, a neural retriever for Polish trained on a diverse collection of manually or weakly labeled datasets. SilverRetriever achieves much better results than other Polish models and is competitive with larger multilingual models. Together with the model, we open-source five new passage retrieval datasets.
Improving Question Answering Performance through Manual Annotation: Costs, Benefits and Strategies
Dec 17, 2022



Recently proposed systems for open-domain question answering (OpenQA) require large amounts of training data to achieve state-of-the-art performance. However, data annotation is known to be time-consuming and therefore expensive to acquire. As a result, the appropriate datasets are available only for a handful of languages (mainly English and Chinese). In this work, we introduce and publicly release PolQA, the first Polish dataset for OpenQA. It consists of 7,000 questions, 87,525 manually labeled evidence passages, and a corpus of over 7,097,322 candidate passages. Each question is classified according to its formulation, type, as well as entity type of the answer. This resource allows us to evaluate the impact of different annotation choices on the performance of the QA system and propose an efficient annotation strategy that increases the passage retrieval performance by 10.55 p.p. while reducing the annotation cost by 82%.
Keyword Extraction from Short Texts with~a~Text-To-Text Transfer Transformer
Sep 28, 2022

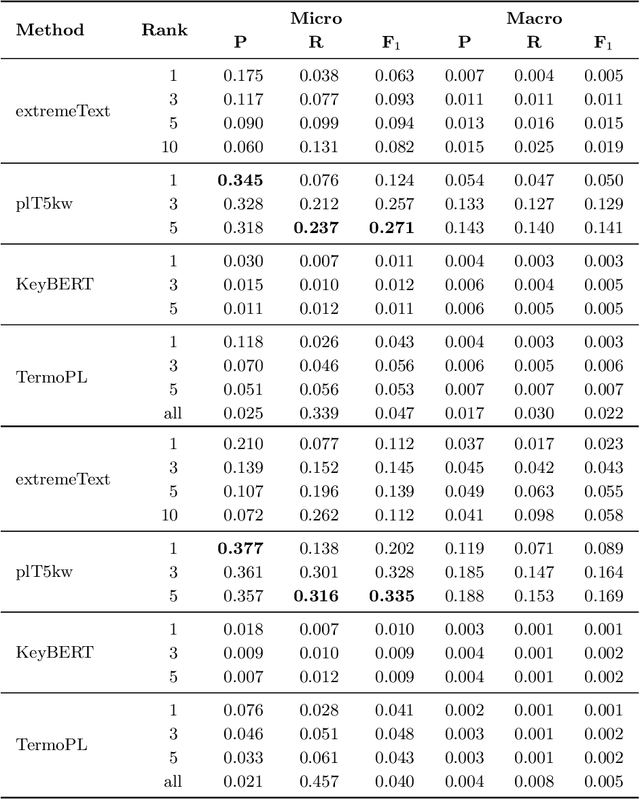
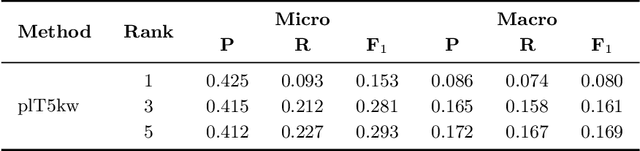
The paper explores the relevance of the Text-To-Text Transfer Transformer language model (T5) for Polish (plT5) to the task of intrinsic and extrinsic keyword extraction from short text passages. The evaluation is carried out on the new Polish Open Science Metadata Corpus (POSMAC), which is released with this paper: a collection of 216,214 abstracts of scientific publications compiled in the CURLICAT project. We compare the results obtained by four different methods, i.e. plT5kw, extremeText, TermoPL, KeyBERT and conclude that the plT5kw model yields particularly promising results for both frequent and sparsely represented keywords. Furthermore, a plT5kw keyword generation model trained on the POSMAC also seems to produce highly useful results in cross-domain text labelling scenarios. We discuss the performance of the model on news stories and phone-based dialog transcripts which represent text genres and domains extrinsic to the dataset of scientific abstracts. Finally, we also attempt to characterize the challenges of evaluating a text-to-text model on both intrinsic and extrinsic keyword extraction.
Findings of the Shared Task on Multilingual Coreference Resolution
Sep 16, 2022
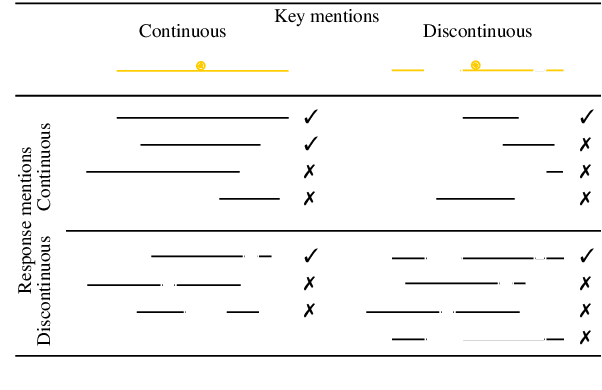

This paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020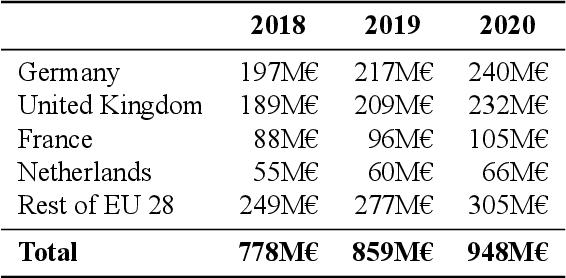
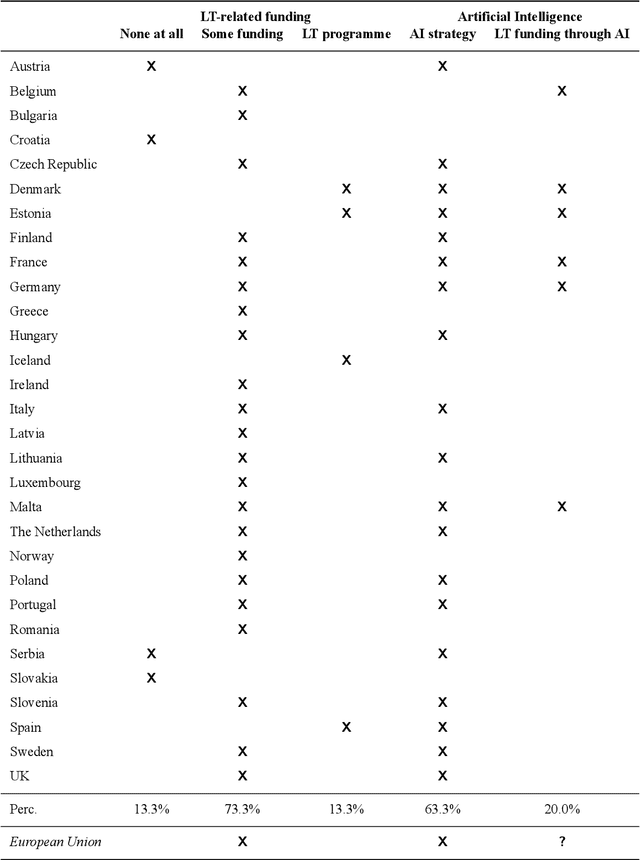
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.