 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Data Augmentation for bias mitigation
Aug 22, 2023The development of fair and ethical AI systems requires careful consideration of bias mitigation, an area often overlooked or ignored. In this study, we introduce a novel and efficient approach for addressing biases called Targeted Data Augmentation (TDA), which leverages classical data augmentation techniques to tackle the pressing issue of bias in data and models. Unlike the laborious task of removing biases, our method proposes to insert biases instead, resulting in improved performance. To identify biases, we annotated two diverse datasets: a dataset of clinical skin lesions and a dataset of male and female faces. These bias annotations are published for the first time in this study, providing a valuable resource for future research. Through Counterfactual Bias Insertion, we discovered that biases associated with the frame, ruler, and glasses had a significant impact on models. By randomly introducing biases during training, we mitigated these biases and achieved a substantial decrease in bias measures, ranging from two-fold to more than 50-fold, while maintaining a negligible increase in the error rate.
A survey on bias in machine learning research
Aug 22, 2023Current research on bias in machine learning often focuses on fairness, while overlooking the roots or causes of bias. However, bias was originally defined as a "systematic error," often caused by humans at different stages of the research process. This article aims to bridge the gap between past literature on bias in research by providing taxonomy for potential sources of bias and errors in data and models. The paper focus on bias in machine learning pipelines. Survey analyses over forty potential sources of bias in the machine learning (ML) pipeline, providing clear examples for each. By understanding the sources and consequences of bias in machine learning, better methods can be developed for its detecting and mitigating, leading to fairer, more transparent, and more accurate ML models.
Data augmentation and explainability for bias discovery and mitigation in deep learning
Aug 18, 2023This dissertation explores the impact of bias in deep neural networks and presents methods for reducing its influence on model performance. The first part begins by categorizing and describing potential sources of bias and errors in data and models, with a particular focus on bias in machine learning pipelines. The next chapter outlines a taxonomy and methods of Explainable AI as a way to justify predictions and control and improve the model. Then, as an example of a laborious manual data inspection and bias discovery process, a skin lesion dataset is manually examined. A Global Explanation for the Bias Identification method is proposed as an alternative semi-automatic approach to manual data exploration for discovering potential biases in data. Relevant numerical methods and metrics are discussed for assessing the effects of the identified biases on the model. Whereas identifying errors and bias is critical, improving the model and reducing the number of flaws in the future is an absolute priority. Hence, the second part of the thesis focuses on mitigating the influence of bias on ML models. Three approaches are proposed and discussed: Style Transfer Data Augmentation, Targeted Data Augmentations, and Attribution Feedback. Style Transfer Data Augmentation aims to address shape and texture bias by merging a style of a malignant lesion with a conflicting shape of a benign one. Targeted Data Augmentations randomly insert possible biases into all images in the dataset during the training, as a way to make the process random and, thus, destroy spurious correlations. Lastly, Attribution Feedback is used to fine-tune the model to improve its accuracy by eliminating obvious mistakes and teaching it to ignore insignificant input parts via an attribution loss. The goal of these approaches is to reduce the influence of bias on machine learning models, rather than eliminate it entirely.
Keyword Extraction from Short Texts with~a~Text-To-Text Transfer Transformer
Sep 28, 2022

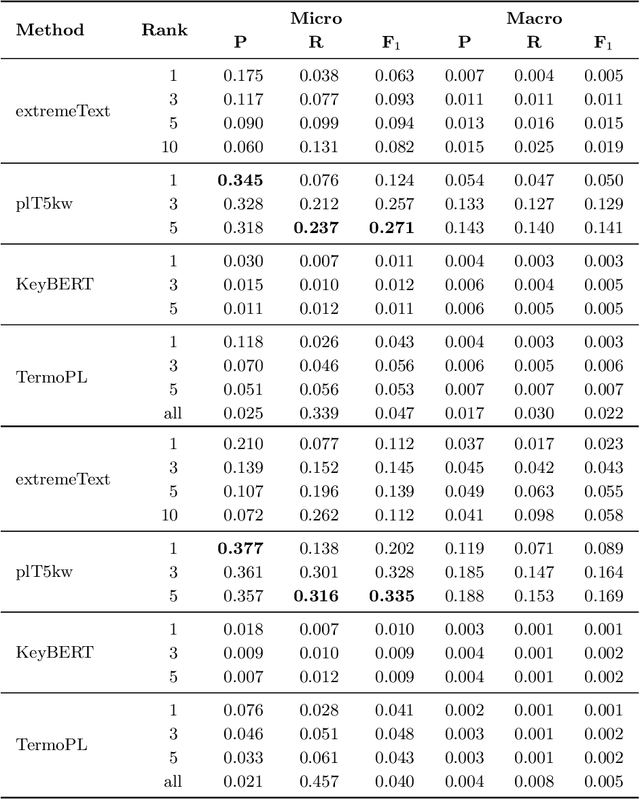
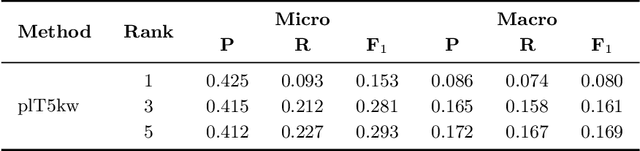
The paper explores the relevance of the Text-To-Text Transfer Transformer language model (T5) for Polish (plT5) to the task of intrinsic and extrinsic keyword extraction from short text passages. The evaluation is carried out on the new Polish Open Science Metadata Corpus (POSMAC), which is released with this paper: a collection of 216,214 abstracts of scientific publications compiled in the CURLICAT project. We compare the results obtained by four different methods, i.e. plT5kw, extremeText, TermoPL, KeyBERT and conclude that the plT5kw model yields particularly promising results for both frequent and sparsely represented keywords. Furthermore, a plT5kw keyword generation model trained on the POSMAC also seems to produce highly useful results in cross-domain text labelling scenarios. We discuss the performance of the model on news stories and phone-based dialog transcripts which represent text genres and domains extrinsic to the dataset of scientific abstracts. Finally, we also attempt to characterize the challenges of evaluating a text-to-text model on both intrinsic and extrinsic keyword extraction.