 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on bias in machine learning research
Aug 22, 2023Current research on bias in machine learning often focuses on fairness, while overlooking the roots or causes of bias. However, bias was originally defined as a "systematic error," often caused by humans at different stages of the research process. This article aims to bridge the gap between past literature on bias in research by providing taxonomy for potential sources of bias and errors in data and models. The paper focus on bias in machine learning pipelines. Survey analyses over forty potential sources of bias in the machine learning (ML) pipeline, providing clear examples for each. By understanding the sources and consequences of bias in machine learning, better methods can be developed for its detecting and mitigating, leading to fairer, more transparent, and more accurate ML models.
Targeted Data Augmentation for bias mitigation
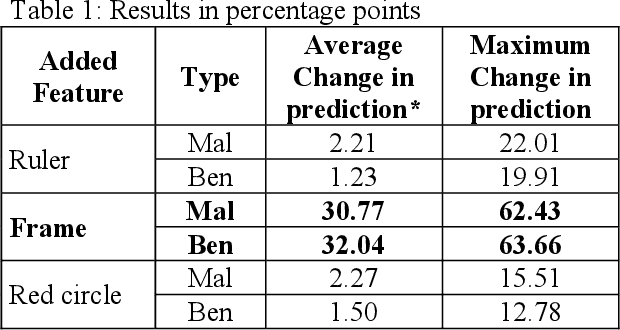
Aug 22, 2023The development of fair and ethical AI systems requires careful consideration of bias mitigation, an area often overlooked or ignored. In this study, we introduce a novel and efficient approach for addressing biases called Targeted Data Augmentation (TDA), which leverages classical data augmentation techniques to tackle the pressing issue of bias in data and models. Unlike the laborious task of removing biases, our method proposes to insert biases instead, resulting in improved performance. To identify biases, we annotated two diverse datasets: a dataset of clinical skin lesions and a dataset of male and female faces. These bias annotations are published for the first time in this study, providing a valuable resource for future research. Through Counterfactual Bias Insertion, we discovered that biases associated with the frame, ruler, and glasses had a significant impact on models. By randomly introducing biases during training, we mitigated these biases and achieved a substantial decrease in bias measures, ranging from two-fold to more than 50-fold, while maintaining a negligible increase in the error rate.
Review of methods for automatic cerebral microbleeds detection
Jan 31, 2023

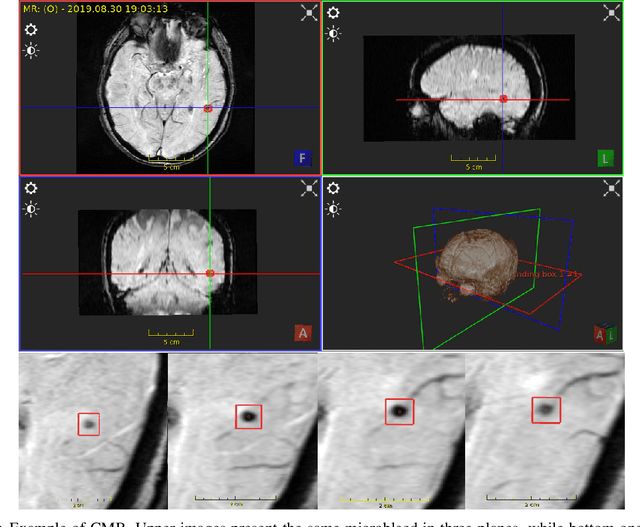
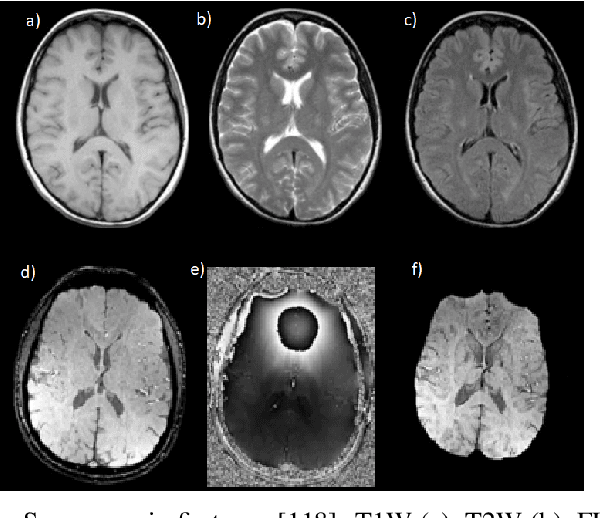
Cerebral microbleeds detection is an important and challenging task. With the gaining popularity of the MRI, the ability to detect cerebral microbleeds also raises. Unfortunately, for radiologists, it is a time-consuming and laborious procedure. For this reason, various solutions to automate this process have been proposed for several years, but none of them is currently used in medical practice. In this context, the need to systematize the existing knowledge and best practices has been recognized as a factor facilitating the imminent synthesis of a real CMBs detection system practically applicable in medicine. To the best of our knowledge, all available publications regarding automatic cerebral microbleeds detection have been gathered, described, and assessed in this paper in order to distinguish the current research state and provide a starting point for future studies.
Global explanations for discovering bias in data
May 05, 2020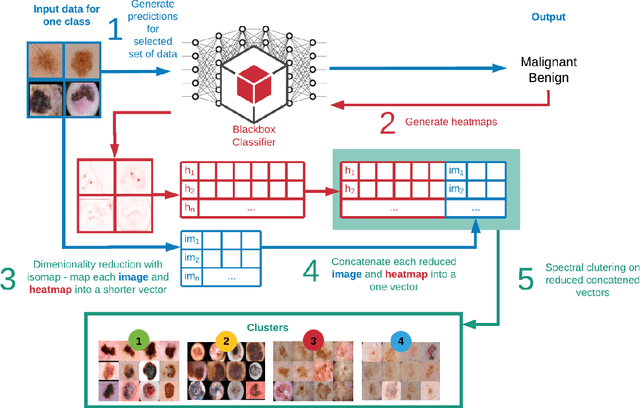
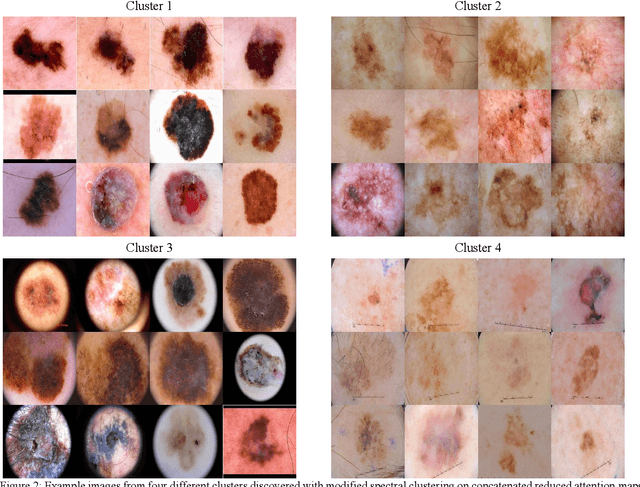
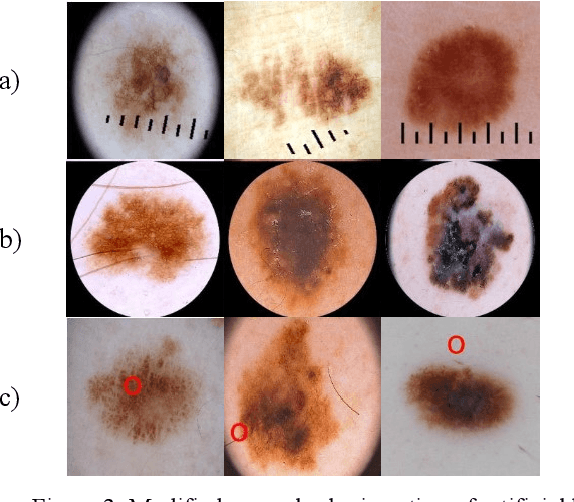
In the paper, we propose attention-based summarized post-hoc explanations for detection and identification of bias in data. We propose a global explanation and introduce a step-by-step framework on how to detect and test bias. Then, the bias is evaluated with a proposed counterfactual approach to bias insertion. Because removing the unwanted bias is often a complicated and tremendous task, we automatically insert it, instead. We validate our results on the example of the skin lesion dataset. Using the method, we successfully identified and confirmed part of the possible bias-causing artifacts in dermoscopy images. We confirmed that the commonplace black frames in the training dataset images have a strong influence on the Convolutional Neural Network's prediction. After artificially adding a black frame to all images, around 22% of them changed the prediction from benign to malignant. We have shown that bias detection is an important step of making more robust models, and we discuss how to improve them
Style transfer-based image synthesis as an efficient regularization technique in deep learning
May 27, 2019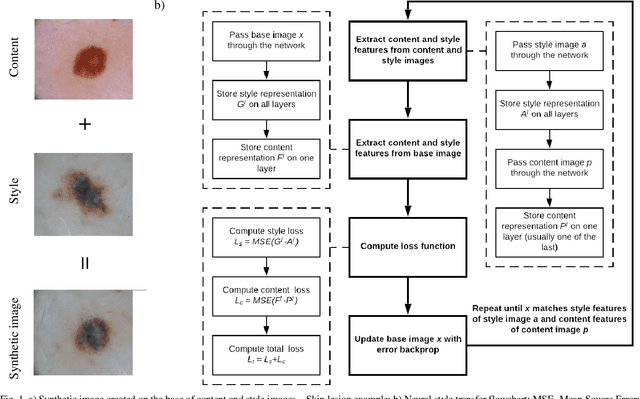
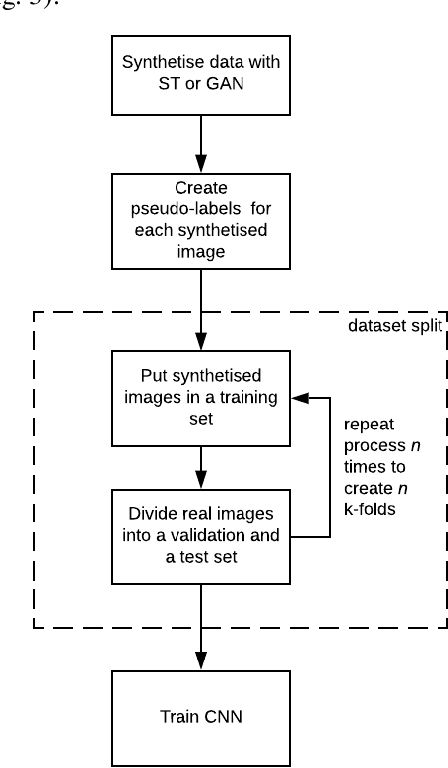
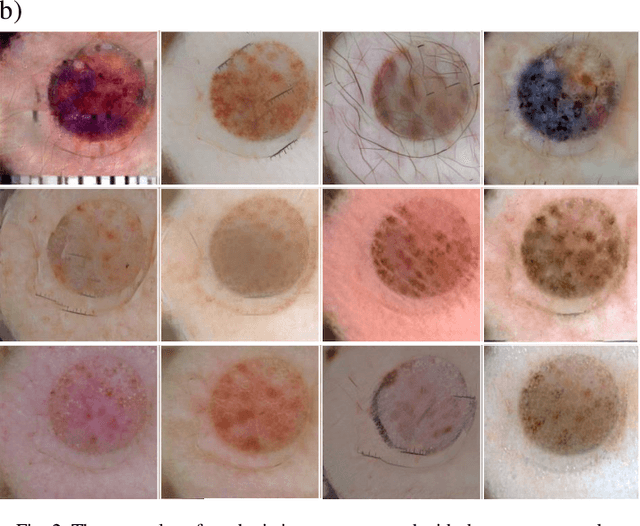
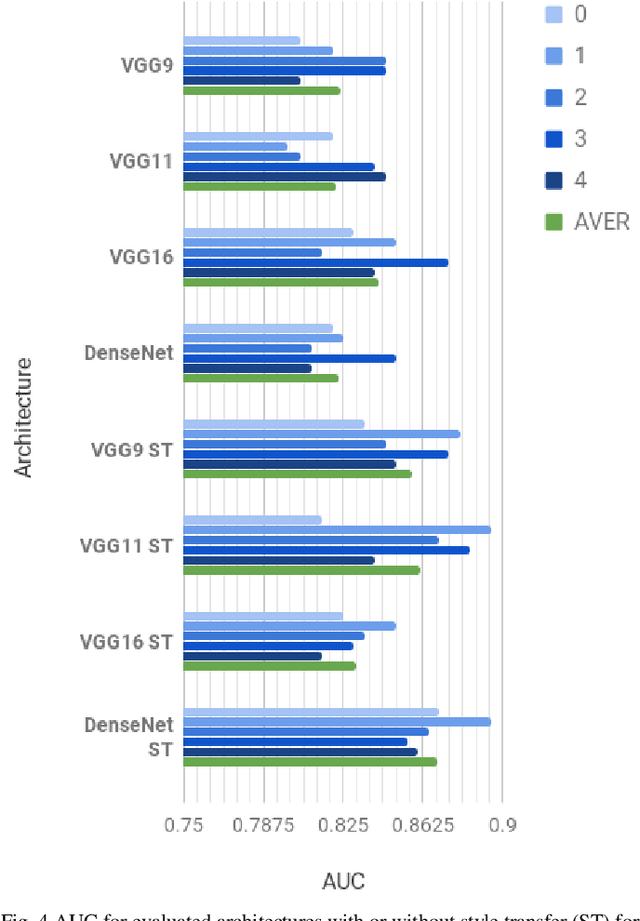
These days deep learning is the fastest-growing area in the field of Machine Learning. Convolutional Neural Networks are currently the main tool used for image analysis and classification purposes. Although great achievements and perspectives, deep neural networks and accompanying learning algorithms have some relevant challenges to tackle. In this paper, we have focused on the most frequently mentioned problem in the field of machine learning, that is relatively poor generalization abilities. Partial remedies for this are regularization techniques e.g. dropout, batch normalization, weight decay, transfer learning, early stopping and data augmentation. In this paper, we have focused on data augmentation. We propose to use a method based on a neural style transfer, which allows generating new unlabeled images of a high perceptual quality that combine the content of a base image with the appearance of another one. In a proposed approach, the newly created images are described with pseudo-labels, and then used as a training dataset. Real, labeled images are divided into the validation and test set. We validated the proposed method on a challenging skin lesion classification case study. Four representative neural architectures are examined. Obtained results show the strong potential of the proposed approach.