 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe biasing effect of GAN-based augmentation methods on skin lesion images
Jun 30, 2022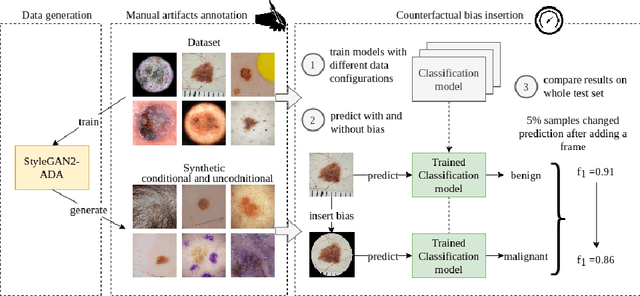
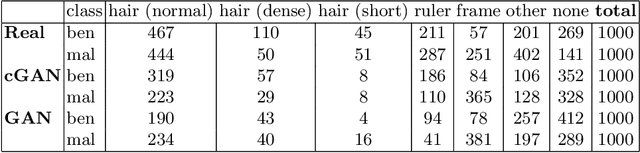
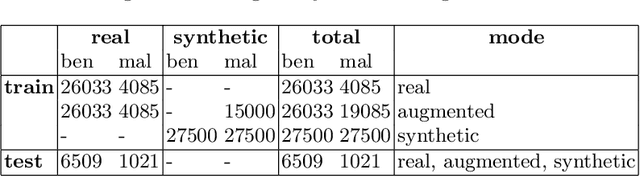

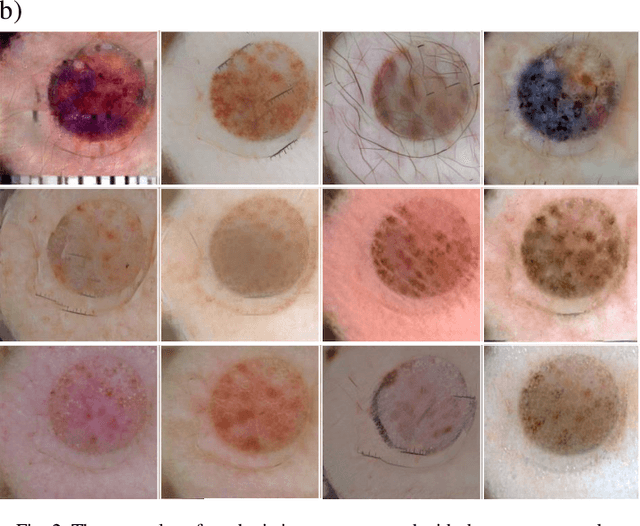
New medical datasets are now more open to the public, allowing for better and more extensive research. Although prepared with the utmost care, new datasets might still be a source of spurious correlations that affect the learning process. Moreover, data collections are usually not large enough and are often unbalanced. One approach to alleviate the data imbalance is using data augmentation with Generative Adversarial Networks (GANs) to extend the dataset with high-quality images. GANs are usually trained on the same biased datasets as the target data, resulting in more biased instances. This work explored unconditional and conditional GANs to compare their bias inheritance and how the synthetic data influenced the models. We provided extensive manual data annotation of possibly biasing artifacts on the well-known ISIC dataset with skin lesions. In addition, we examined classification models trained on both real and synthetic data with counterfactual bias explanations. Our experiments showed that GANs inherited biases and sometimes even amplified them, leading to even stronger spurious correlations. Manual data annotation and synthetic images are publicly available for reproducible scientific research.
Joint prediction of truecasing and punctuation for conversational speech in low-resource scenarios
Sep 13, 2021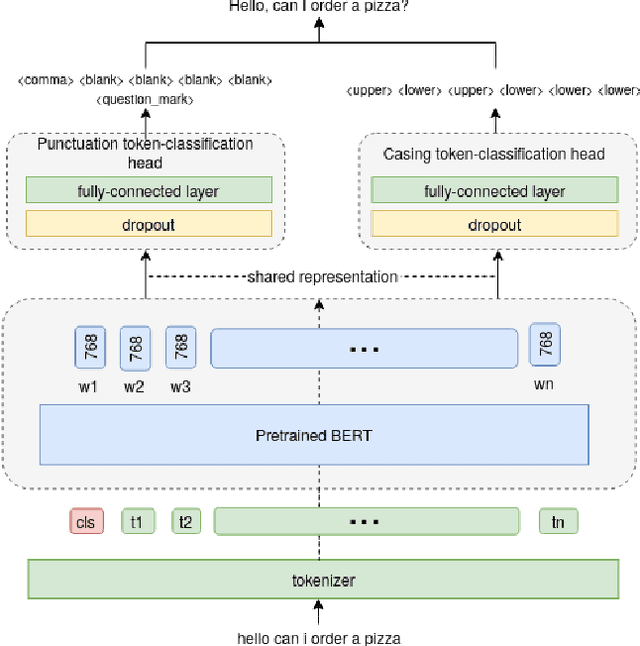
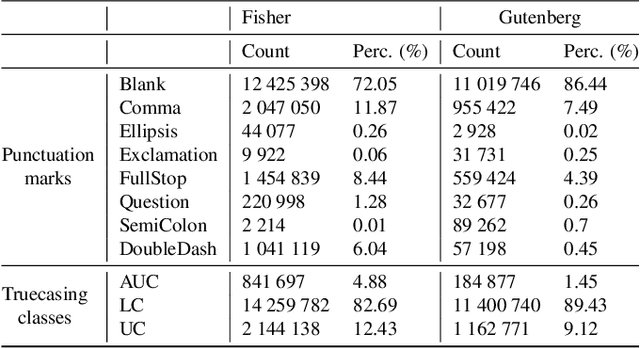
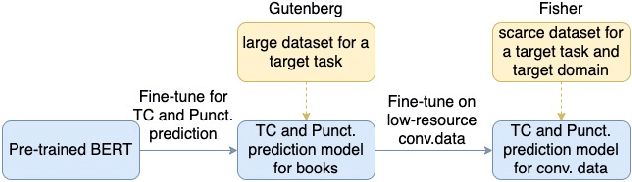
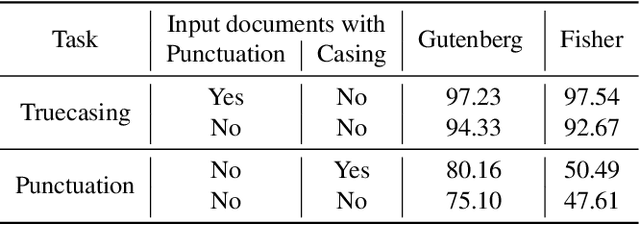
Capitalization and punctuation are important cues for comprehending written texts and conversational transcripts. Yet, many ASR systems do not produce punctuated and case-formatted speech transcripts. We propose to use a multi-task system that can exploit the relations between casing and punctuation to improve their prediction performance. Whereas text data for predicting punctuation and truecasing is seemingly abundant, we argue that written text resources are inadequate as training data for conversational models. We quantify the mismatch between written and conversational text domains by comparing the joint distributions of punctuation and word cases, and by testing our model cross-domain. Further, we show that by training the model in the written text domain and then transfer learning to conversations, we can achieve reasonable performance with less data.
Waste detection in Pomerania: non-profit project for detecting waste in environment
May 12, 2021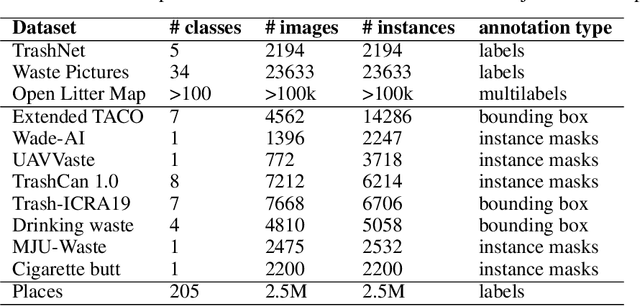

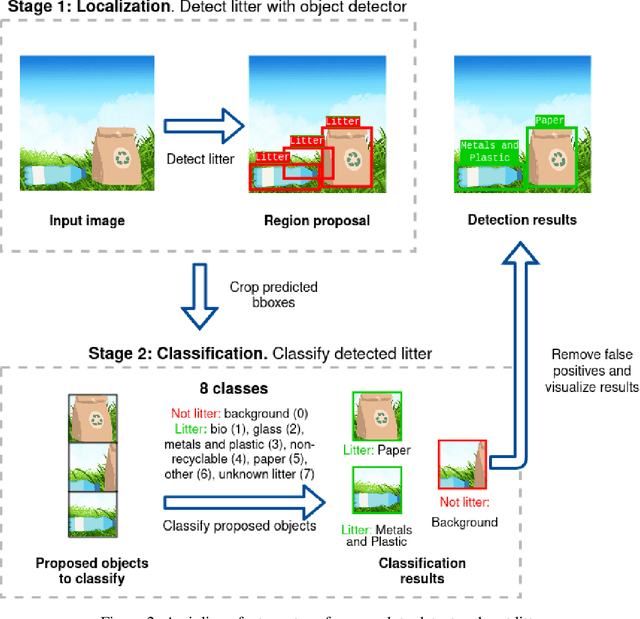

Waste pollution is one of the most significant environmental issues in the modern world. The importance of recycling is well known, either for economic or ecological reasons, and the industry demands high efficiency. Our team conducted comprehensive research on Artificial Intelligence usage in waste detection and classification to fight the world's waste pollution problem. As a result an open-source framework that enables the detection and classification of litter was developed. The final pipeline consists of two neural networks: one that detects litter and a second responsible for litter classification. Waste is classified into seven categories: bio, glass, metal and plastic, non-recyclable, other, paper and unknown. Our approach achieves up to 70% of average precision in waste detection and around 75% of classification accuracy on the test dataset. The code used in the studies is publicly available online.
Global explanations for discovering bias in data
May 05, 2020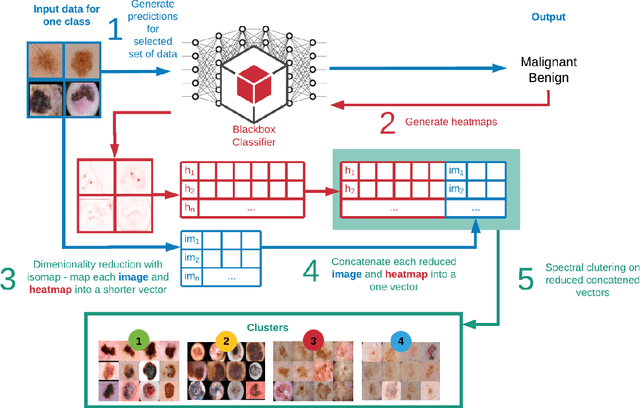
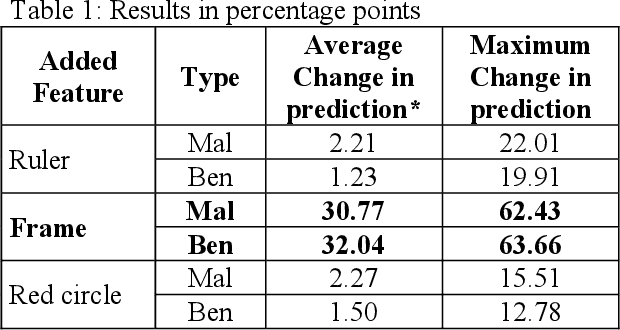
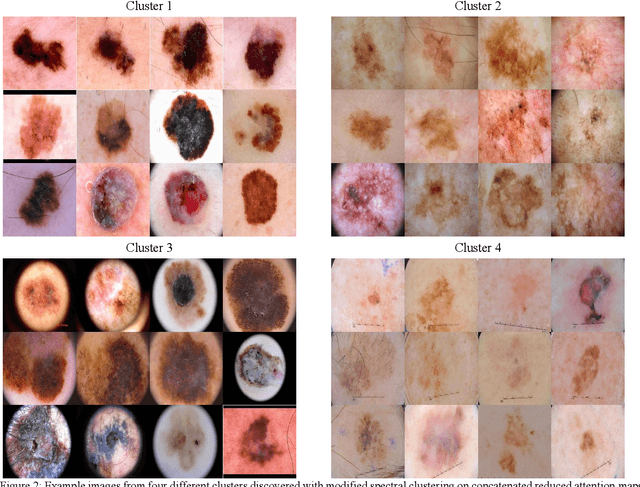
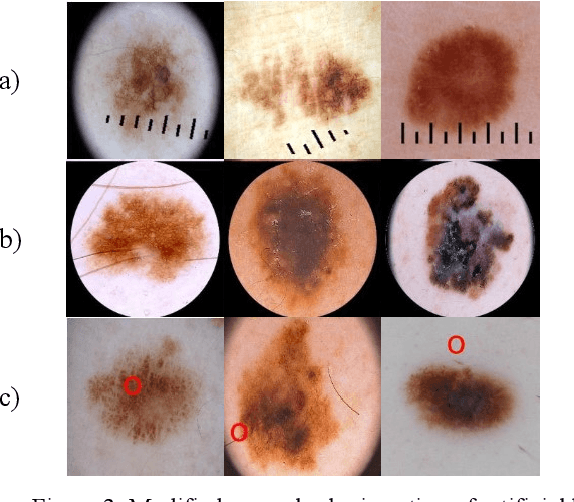
In the paper, we propose attention-based summarized post-hoc explanations for detection and identification of bias in data. We propose a global explanation and introduce a step-by-step framework on how to detect and test bias. Then, the bias is evaluated with a proposed counterfactual approach to bias insertion. Because removing the unwanted bias is often a complicated and tremendous task, we automatically insert it, instead. We validate our results on the example of the skin lesion dataset. Using the method, we successfully identified and confirmed part of the possible bias-causing artifacts in dermoscopy images. We confirmed that the commonplace black frames in the training dataset images have a strong influence on the Convolutional Neural Network's prediction. After artificially adding a black frame to all images, around 22% of them changed the prediction from benign to malignant. We have shown that bias detection is an important step of making more robust models, and we discuss how to improve them
Style transfer-based image synthesis as an efficient regularization technique in deep learning
May 27, 2019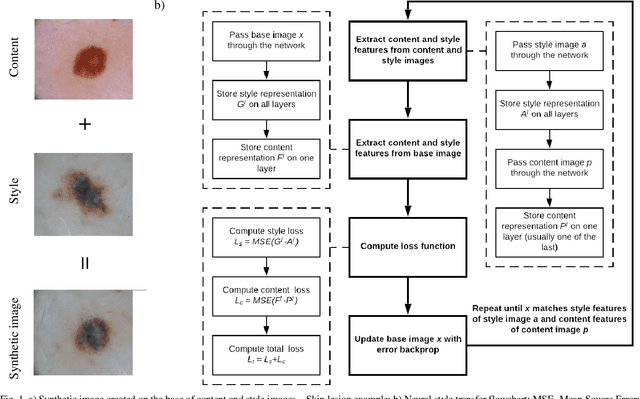
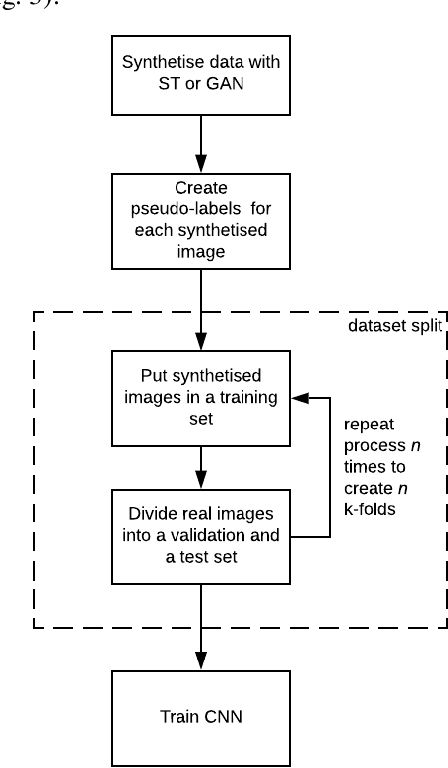
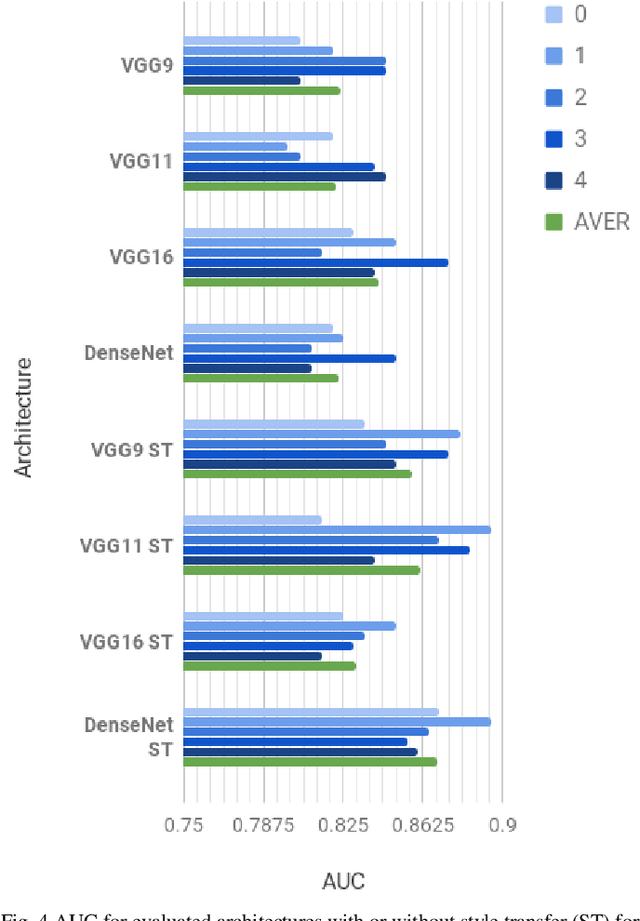
These days deep learning is the fastest-growing area in the field of Machine Learning. Convolutional Neural Networks are currently the main tool used for image analysis and classification purposes. Although great achievements and perspectives, deep neural networks and accompanying learning algorithms have some relevant challenges to tackle. In this paper, we have focused on the most frequently mentioned problem in the field of machine learning, that is relatively poor generalization abilities. Partial remedies for this are regularization techniques e.g. dropout, batch normalization, weight decay, transfer learning, early stopping and data augmentation. In this paper, we have focused on data augmentation. We propose to use a method based on a neural style transfer, which allows generating new unlabeled images of a high perceptual quality that combine the content of a base image with the appearance of another one. In a proposed approach, the newly created images are described with pseudo-labels, and then used as a training dataset. Real, labeled images are divided into the validation and test set. We validated the proposed method on a challenging skin lesion classification case study. Four representative neural architectures are examined. Obtained results show the strong potential of the proposed approach.