 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation
Jun 12, 2024
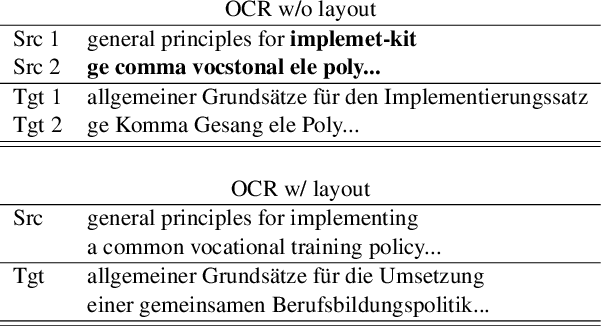

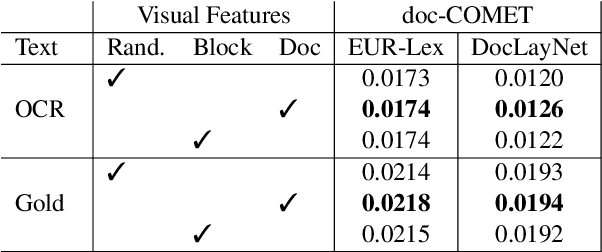
Document translation poses a challenge for Neural Machine Translation (NMT) systems. Most document-level NMT systems rely on meticulously curated sentence-level parallel data, assuming flawless extraction of text from documents along with their precise reading order. These systems also tend to disregard additional visual cues such as the document layout, deeming it irrelevant. However, real-world documents often possess intricate text layouts that defy these assumptions. Extracting information from Optical Character Recognition (OCR) or heuristic rules can result in errors, and the layout (e.g., paragraphs, headers) may convey relationships between distant sections of text. This complexity is particularly evident in widely used PDF documents, which represent information visually. This paper addresses this gap by introducing M3T, a novel benchmark dataset tailored to evaluate NMT systems on the comprehensive task of translating semi-structured documents. This dataset aims to bridge the evaluation gap in document-level NMT systems, acknowledging the challenges posed by rich text layouts in real-world applications.
MT-GenEval: A Counterfactual and Contextual Dataset for Evaluating Gender Accuracy in Machine Translation
Nov 02, 2022



As generic machine translation (MT) quality has improved, the need for targeted benchmarks that explore fine-grained aspects of quality has increased. In particular, gender accuracy in translation can have implications in terms of output fluency, translation accuracy, and ethics. In this paper, we introduce MT-GenEval, a benchmark for evaluating gender accuracy in translation from English into eight widely-spoken languages. MT-GenEval complements existing benchmarks by providing realistic, gender-balanced, counterfactual data in eight language pairs where the gender of individuals is unambiguous in the input segment, including multi-sentence segments requiring inter-sentential gender agreement. Our data and code is publicly available under a CC BY SA 3.0 license.
Non-Contrastive Self-Supervised Learning of Utterance-Level Speech Representations
Aug 10, 2022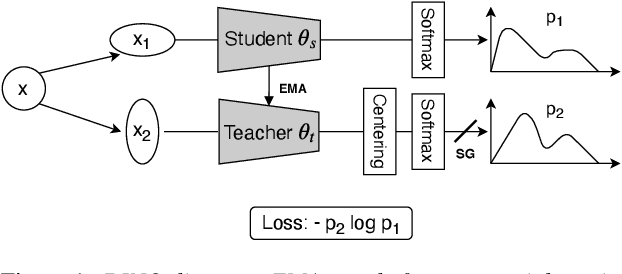
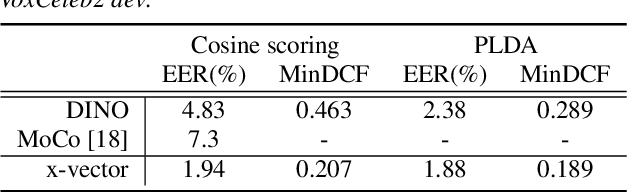
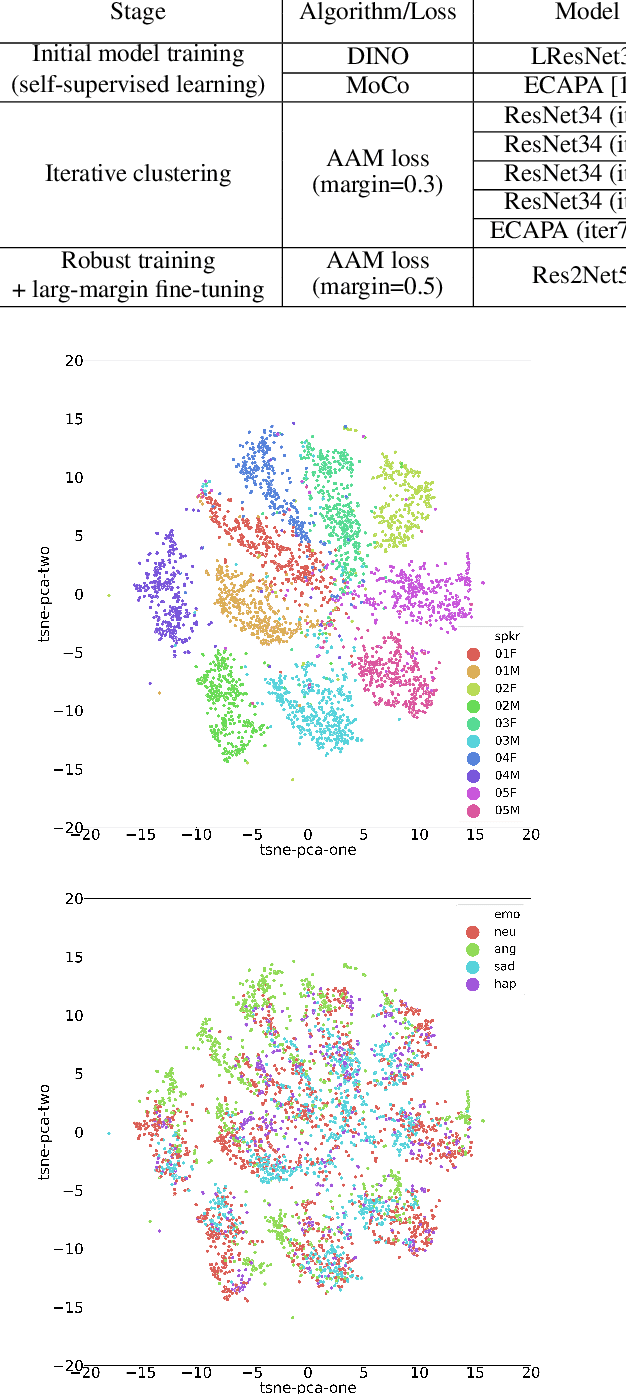
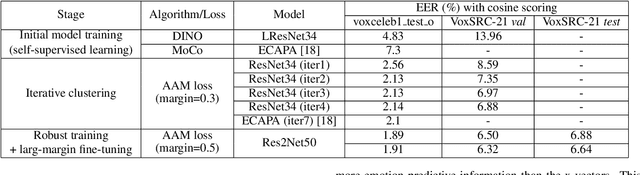
Considering the abundance of unlabeled speech data and the high labeling costs, unsupervised learning methods can be essential for better system development. One of the most successful methods is contrastive self-supervised methods, which require negative sampling: sampling alternative samples to contrast with the current sample (anchor). However, it is hard to ensure if all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised learning method on an unlabeled speech corpus to learn utterance-level embeddings. We used DIstillation with NO labels (DINO), proposed in computer vision, and adapted it to the speech domain. Unlike the contrastive methods, DINO does not require negative sampling. These embeddings were evaluated on speaker verification and emotion recognition. In speaker verification, the unsupervised DINO embedding with cosine scoring provided 4.38% EER on the VoxCeleb1 test trial. This outperforms the best contrastive self-supervised method by 40% relative in EER. An iterative pseudo-labeling training pipeline, not requiring speaker labels, further improved the EER to 1.89%. In emotion recognition, the DINO embedding performed 60.87, 79.21, and 56.98% in micro-f1 score on IEMOCAP, Crema-D, and MSP-Podcast, respectively. The results imply the generality of the DINO embedding to different speech applications.
Beyond Isolated Utterances: Conversational Emotion Recognition
Sep 13, 2021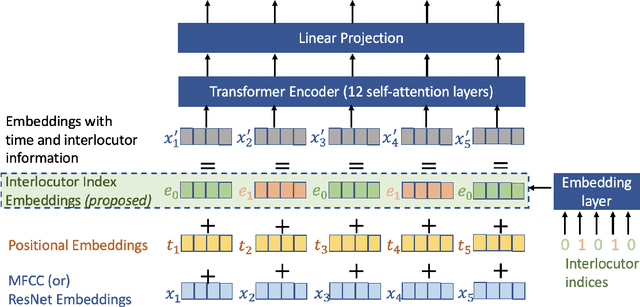

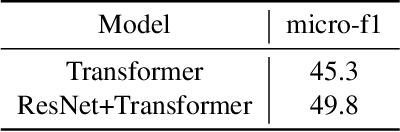
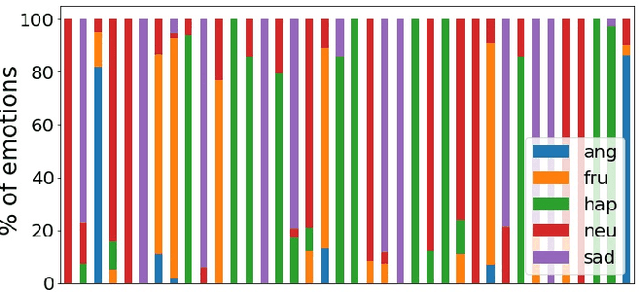
Speech emotion recognition is the task of recognizing the speaker's emotional state given a recording of their utterance. While most of the current approaches focus on inferring emotion from isolated utterances, we argue that this is not sufficient to achieve conversational emotion recognition (CER) which deals with recognizing emotions in conversations. In this work, we propose several approaches for CER by treating it as a sequence labeling task. We investigated transformer architecture for CER and, compared it with ResNet-34 and BiLSTM architectures in both contextual and context-less scenarios using IEMOCAP corpus. Based on the inner workings of the self-attention mechanism, we proposed DiverseCatAugment (DCA), an augmentation scheme, which improved the transformer model performance by an absolute 3.3% micro-f1 on conversations and 3.6% on isolated utterances. We further enhanced the performance by introducing an interlocutor-aware transformer model where we learn a dictionary of interlocutor index embeddings to exploit diarized conversations.
Joint prediction of truecasing and punctuation for conversational speech in low-resource scenarios
Sep 13, 2021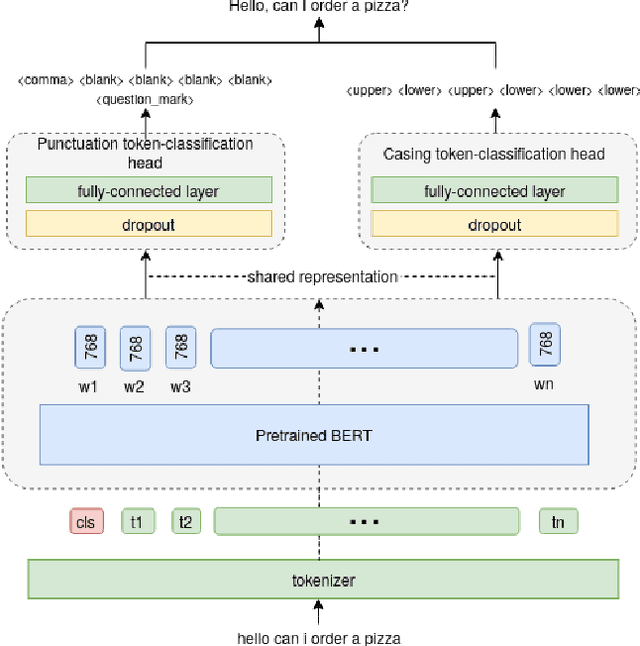
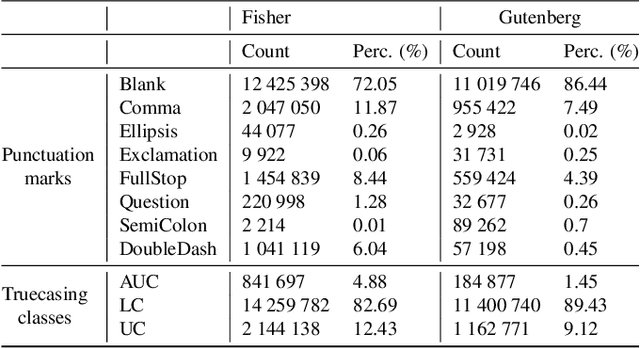
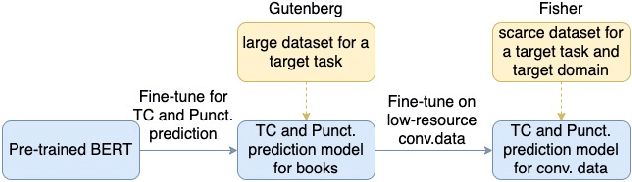
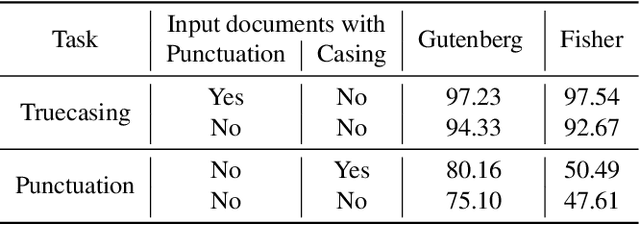
Capitalization and punctuation are important cues for comprehending written texts and conversational transcripts. Yet, many ASR systems do not produce punctuated and case-formatted speech transcripts. We propose to use a multi-task system that can exploit the relations between casing and punctuation to improve their prediction performance. Whereas text data for predicting punctuation and truecasing is seemingly abundant, we argue that written text resources are inadequate as training data for conversational models. We quantify the mismatch between written and conversational text domains by comparing the joint distributions of punctuation and word cases, and by testing our model cross-domain. Further, we show that by training the model in the written text domain and then transfer learning to conversations, we can achieve reasonable performance with less data.
What Helps Transformers Recognize Conversational Structure? Importance of Context, Punctuation, and Labels in Dialog Act Recognition
Jul 05, 2021
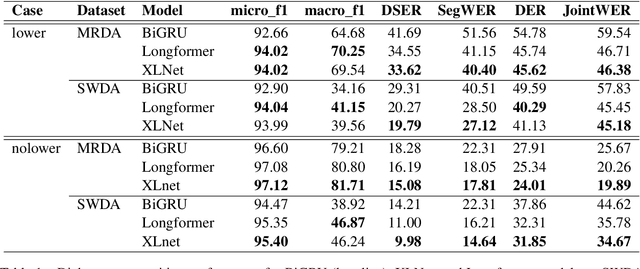
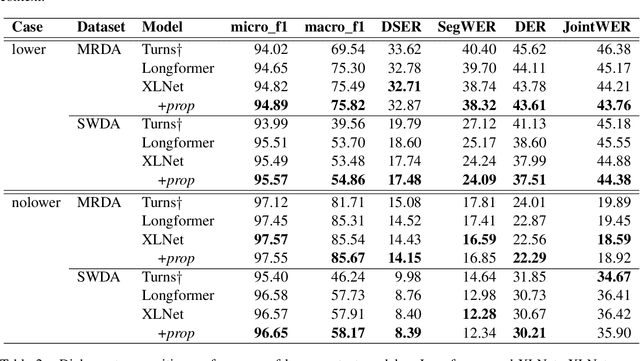
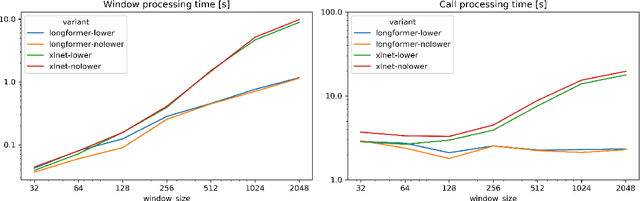
Dialog acts can be interpreted as the atomic units of a conversation, more fine-grained than utterances, characterized by a specific communicative function. The ability to structure a conversational transcript as a sequence of dialog acts -- dialog act recognition, including the segmentation -- is critical for understanding dialog. We apply two pre-trained transformer models, XLNet and Longformer, to this task in English and achieve strong results on Switchboard Dialog Act and Meeting Recorder Dialog Act corpora with dialog act segmentation error rates (DSER) of 8.4% and 14.2%. To understand the key factors affecting dialog act recognition, we perform a comparative analysis of models trained under different conditions. We find that the inclusion of a broader conversational context helps disambiguate many dialog act classes, especially those infrequent in the training data. The presence of punctuation in the transcripts has a massive effect on the models' performance, and a detailed analysis reveals specific segmentation patterns observed in its absence. Finally, we find that the label set specificity does not affect dialog act segmentation performance. These findings have significant practical implications for spoken language understanding applications that depend heavily on a good-quality segmentation being available.
CopyPaste: An Augmentation Method for Speech Emotion Recognition
Oct 27, 2020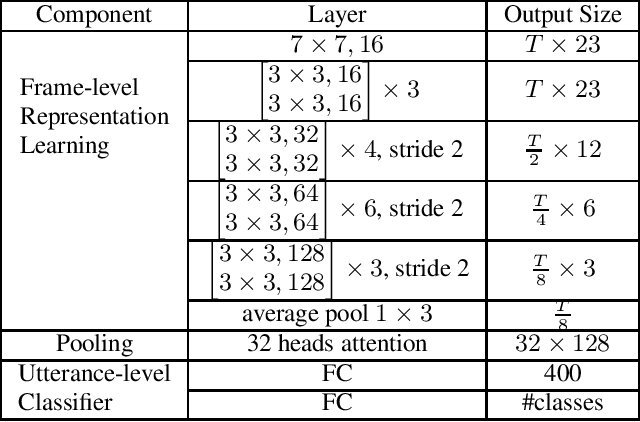
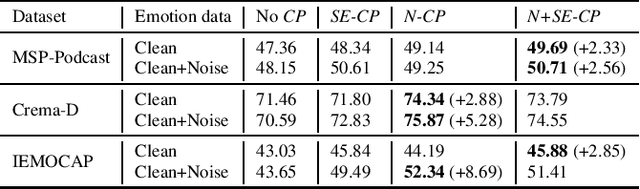

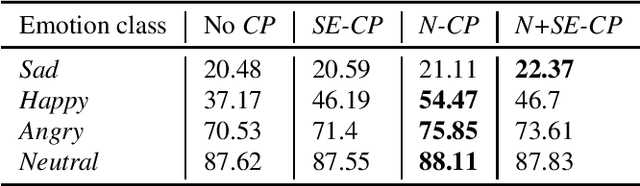
Data augmentation is a widely used strategy for training robust machine learning models. It partially alleviates the problem of limited data for tasks like speech emotion recognition (SER), where collecting data is expensive and challenging. This study proposes CopyPaste, a perceptually motivated novel augmentation procedure for SER. Assuming that the presence of emotions other than neutral dictates a speaker's overall perceived emotion in a recording, concatenation of an emotional (emotion E) and a neutral utterance can still be labeled with emotion E. We hypothesize that SER performance can be improved using these concatenated utterances in model training. To verify this, three CopyPaste schemes are tested on two deep learning models: one trained independently and another using transfer learning from an x-vector model, a speaker recognition model. We observed that all three CopyPaste schemes improve SER performance on all the three datasets considered: MSP-Podcast, Crema-D, and IEMOCAP. Additionally, CopyPaste performs better than noise augmentation and, using them together improves the SER performance further. Our experiments on noisy test sets suggested that CopyPaste is effective even in noisy test conditions.
x-vectors meet emotions: A study on dependencies between emotion and speaker recognition
Feb 12, 2020


In this work, we explore the dependencies between speaker recognition and emotion recognition. We first show that knowledge learned for speaker recognition can be reused for emotion recognition through transfer learning. Then, we show the effect of emotion on speaker recognition. For emotion recognition, we show that using a simple linear model is enough to obtain good performance on the features extracted from pre-trained models such as the x-vector model. Then, we improve emotion recognition performance by fine-tuning for emotion classification. We evaluated our experiments on three different types of datasets: IEMOCAP, MSP-Podcast, and Crema-D. By fine-tuning, we obtained 30.40%, 7.99%, and 8.61% absolute improvement on IEMOCAP, MSP-Podcast, and Crema-D respectively over baseline model with no pre-training. Finally, we present results on the effect of emotion on speaker verification. We observed that speaker verification performance is prone to changes in test speaker emotions. We found that trials with angry utterances performed worst in all three datasets. We hope our analysis will initiate a new line of research in the speaker recognition community.
Hierarchical Transformers for Long Document Classification
Oct 23, 2019



BERT, which stands for Bidirectional Encoder Representations from Transformers, is a recently introduced language representation model based upon the transfer learning paradigm. We extend its fine-tuning procedure to address one of its major limitations - applicability to inputs longer than a few hundred words, such as transcripts of human call conversations. Our method is conceptually simple. We segment the input into smaller chunks and feed each of them into the base model. Then, we propagate each output through a single recurrent layer, or another transformer, followed by a softmax activation. We obtain the final classification decision after the last segment has been consumed. We show that both BERT extensions are quick to fine-tune and converge after as little as 1 epoch of training on a small, domain-specific data set. We successfully apply them in three different tasks involving customer call satisfaction prediction and topic classification, and obtain a significant improvement over the baseline models in two of them.
* 4 figures, 7 pages
Looking for ELMo's friends: Sentence-Level Pretraining Beyond Language Modeling
Dec 28, 2018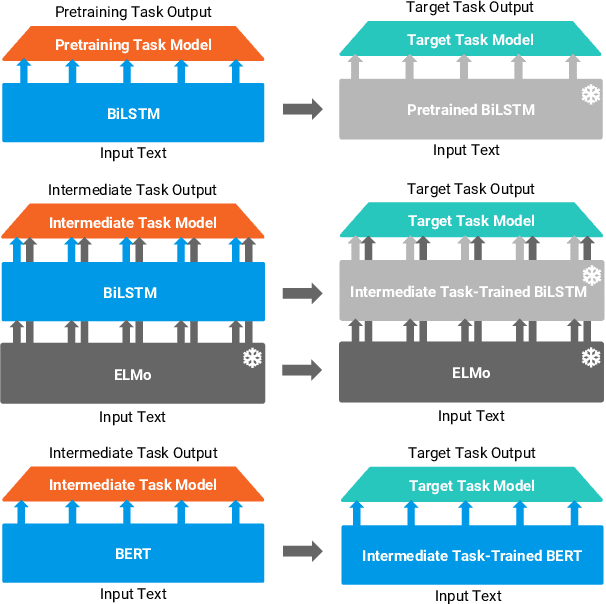
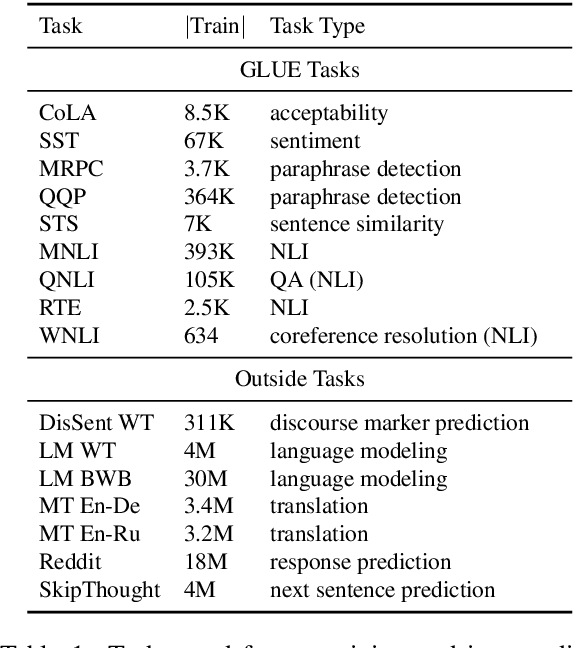
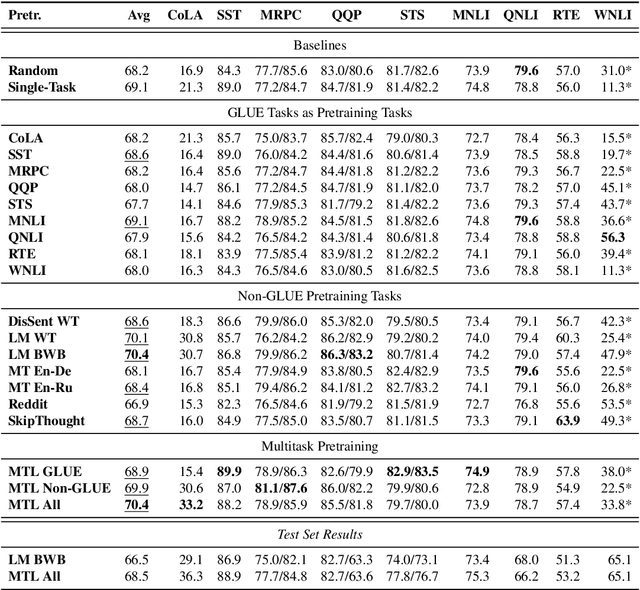
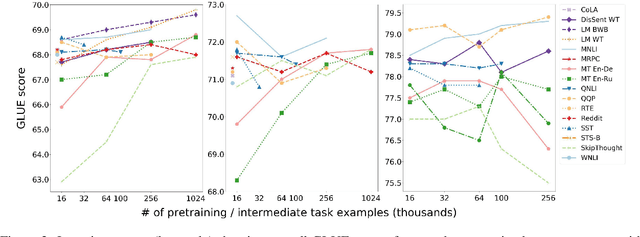
Work on the problem of contextualized word representation -- the development of reusable neural network components for sentence understanding -- has recently seen a surge of progress centered on the unsupervised pretraining task of language modeling with methods like ELMo. This paper contributes the first large-scale systematic study comparing different pretraining tasks in this context, both as complements to language modeling and as potential alternatives. The primary results of the study support the use of language modeling as a pretraining task and set a new state of the art among comparable models using multitask learning with language models. However, a closer look at these results reveals worryingly strong baselines and strikingly varied results across target tasks, suggesting that the widely-used paradigm of pretraining and freezing sentence encoders may not be an ideal platform for further work.