 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMLagBench: Identifying Temporal Training Boundaries in Large Language Models
Nov 15, 2025Large Language Models (LLMs) are pretrained on textual data up to a specific temporal cutoff. This creates a strict knowledge boundary beyond which models cannot provide accurate information without querying external sources. More subtly, when this limitation is unknown or ignored, LLMs may inadvertently blend outdated time-sensitive information with general knowledge during reasoning tasks, potentially compromising response accuracy. We introduce LLMLagBench, an LLM freshness benchmark, as a systematic approach for identifying the earliest probable temporal boundaries of an LLM's training data by evaluating its knowledge of recent events. We then apply this benchmark to evaluate a large set of LLMs, including models with both explicitly declared and undeclared training cutoffs. The reliability of the benchmark is assessed by manual validation and comparison with publicly released information about LLM pretraining.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025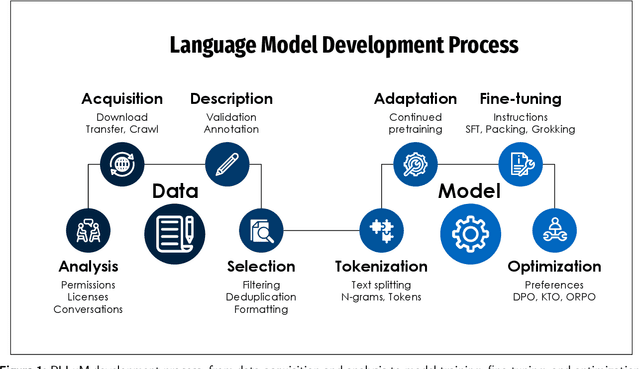
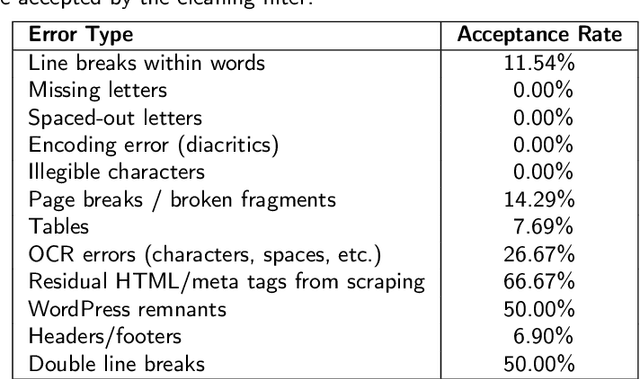
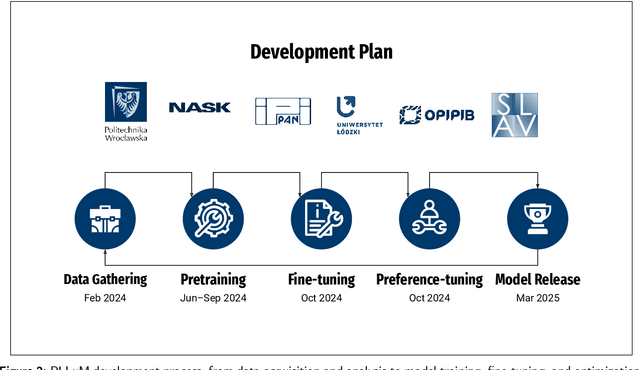

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
SpokesBiz -- an Open Corpus of Conversational Polish
Dec 19, 2023This paper announces the early release of SpokesBiz, a freely available corpus of conversational Polish developed within the CLARIN-BIZ project and comprising over 650 hours of recordings. The transcribed recordings have been diarized and manually annotated for punctuation and casing. We outline the general structure and content of the corpus, showcasing selected applications in linguistic research, evaluation and improvement of automatic speech recognition (ASR) systems
Keyword Extraction from Short Texts with~a~Text-To-Text Transfer Transformer
Sep 28, 2022

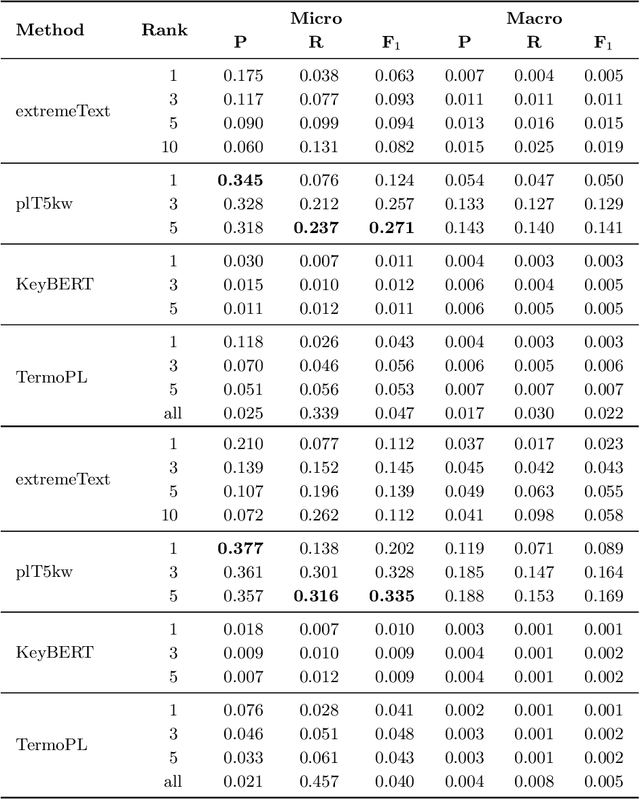
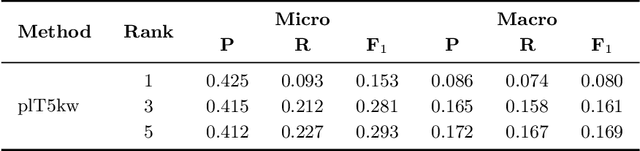
The paper explores the relevance of the Text-To-Text Transfer Transformer language model (T5) for Polish (plT5) to the task of intrinsic and extrinsic keyword extraction from short text passages. The evaluation is carried out on the new Polish Open Science Metadata Corpus (POSMAC), which is released with this paper: a collection of 216,214 abstracts of scientific publications compiled in the CURLICAT project. We compare the results obtained by four different methods, i.e. plT5kw, extremeText, TermoPL, KeyBERT and conclude that the plT5kw model yields particularly promising results for both frequent and sparsely represented keywords. Furthermore, a plT5kw keyword generation model trained on the POSMAC also seems to produce highly useful results in cross-domain text labelling scenarios. We discuss the performance of the model on news stories and phone-based dialog transcripts which represent text genres and domains extrinsic to the dataset of scientific abstracts. Finally, we also attempt to characterize the challenges of evaluating a text-to-text model on both intrinsic and extrinsic keyword extraction.
Joint prediction of truecasing and punctuation for conversational speech in low-resource scenarios
Sep 13, 2021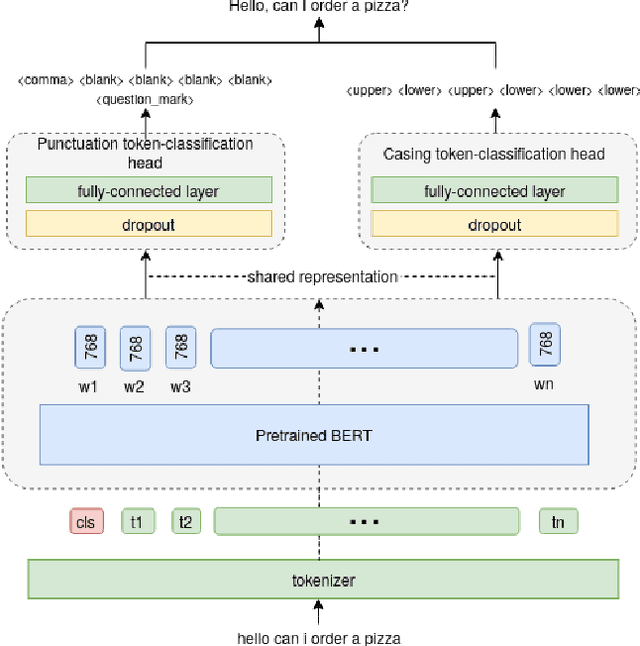
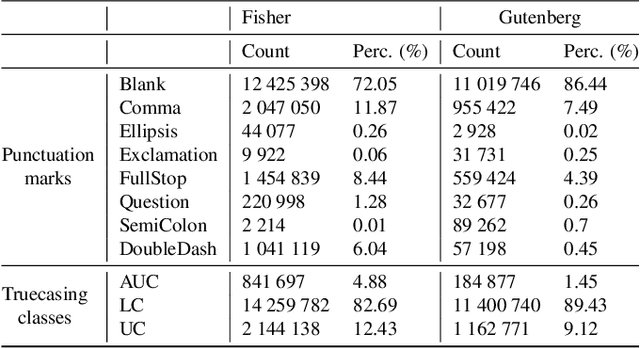
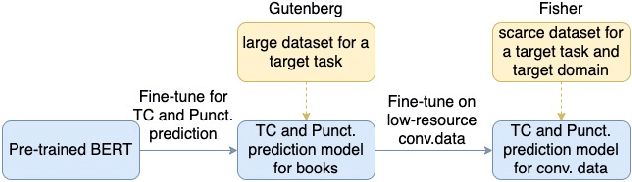
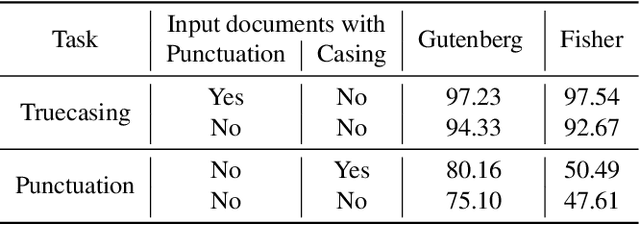
Capitalization and punctuation are important cues for comprehending written texts and conversational transcripts. Yet, many ASR systems do not produce punctuated and case-formatted speech transcripts. We propose to use a multi-task system that can exploit the relations between casing and punctuation to improve their prediction performance. Whereas text data for predicting punctuation and truecasing is seemingly abundant, we argue that written text resources are inadequate as training data for conversational models. We quantify the mismatch between written and conversational text domains by comparing the joint distributions of punctuation and word cases, and by testing our model cross-domain. Further, we show that by training the model in the written text domain and then transfer learning to conversations, we can achieve reasonable performance with less data.