 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetBatch: Distributed Multi-Object Retrieval for ML Data Loading
Feb 25, 2026Machine learning training pipelines consume data in batches. A single training step may require thousands of samples drawn from shards distributed across a storage cluster. Issuing thousands of individual GET requests incurs per-request overhead that often dominates data transfer time. To solve this problem, we introduce GetBatch - a new object store API that elevates batch retrieval to a first-class storage operation, replacing independent GET operations with a single deterministic, fault-tolerant streaming execution. GetBatch achieves up to 15x throughput improvement for small objects and, in a production training workload, reduces P95 batch retrieval latency by 2x and P99 per-object tail latency by 3.7x compared to individual GET requests.
Open ASR Leaderboard: Towards Reproducible and Transparent Multilingual and Long-Form Speech Recognition Evaluation
Oct 08, 2025Despite rapid progress, ASR evaluation remains saturated with short-form English, and efficiency is rarely reported. We present the Open ASR Leaderboard, a fully reproducible benchmark and interactive leaderboard comparing 60+ open-source and proprietary systems across 11 datasets, including dedicated multilingual and long-form tracks. We standardize text normalization and report both word error rate (WER) and inverse real-time factor (RTFx), enabling fair accuracy-efficiency comparisons. For English transcription, Conformer encoders paired with LLM decoders achieve the best average WER but are slower, while CTC and TDT decoders deliver much better RTFx, making them attractive for long-form and offline use. Whisper-derived encoders fine-tuned for English improve accuracy but often trade off multilingual coverage. All code and dataset loaders are open-sourced to support transparent, extensible evaluation.
Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model
May 21, 2025
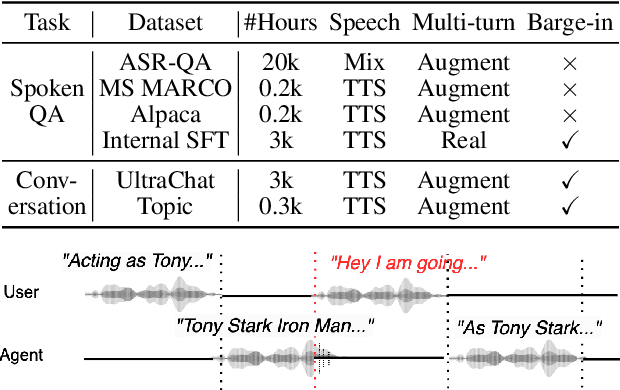
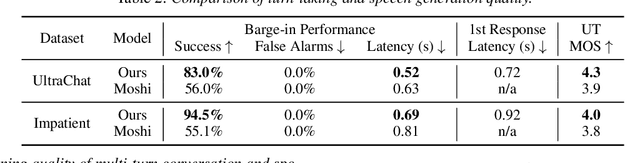

Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.
Training and Inference Efficiency of Encoder-Decoder Speech Models
Mar 07, 2025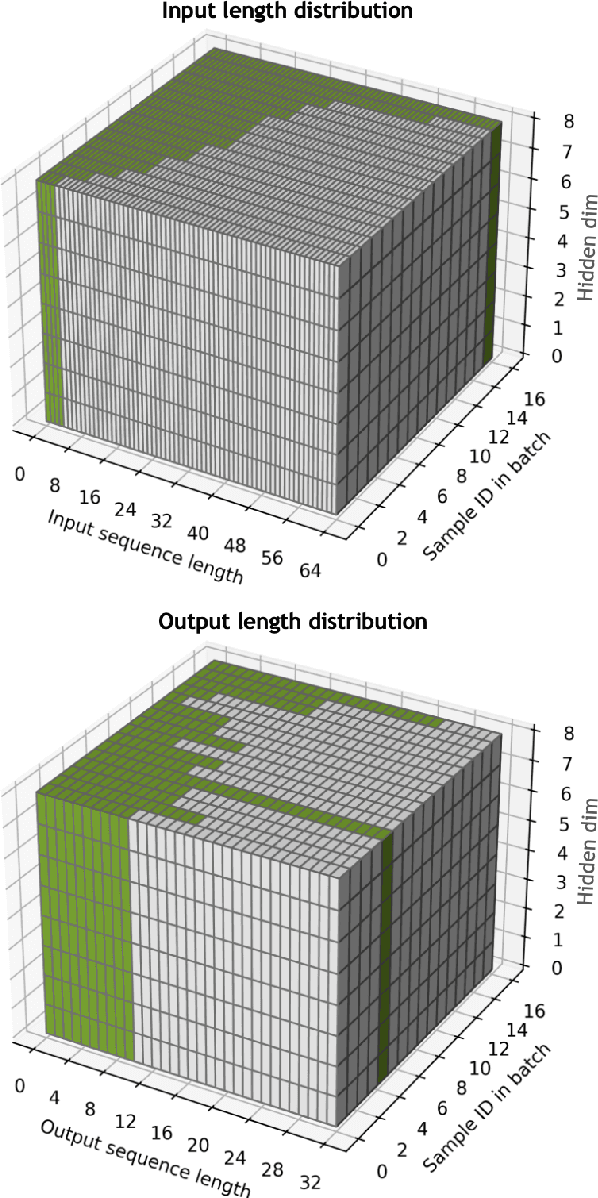

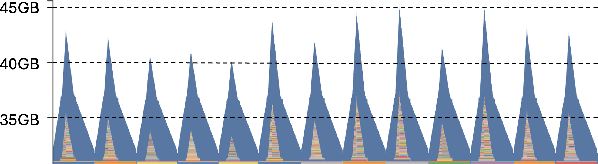
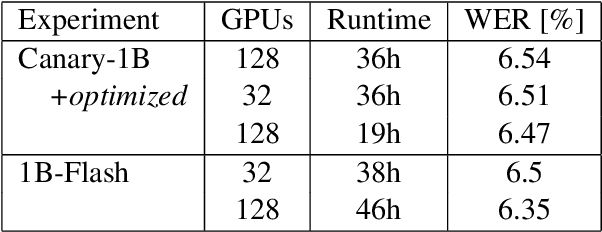
Attention encoder-decoder model architecture is the backbone of several recent top performing foundation speech models: Whisper, Seamless, OWSM, and Canary-1B. However, the reported data and compute requirements for their training are prohibitive for many in the research community. In this work, we focus on the efficiency angle and ask the questions of whether we are training these speech models efficiently, and what can we do to improve? We argue that a major, if not the most severe, detrimental factor for training efficiency is related to the sampling strategy of sequential data. We show that negligence in mini-batch sampling leads to more than 50% computation being spent on padding. To that end, we study, profile, and optimize Canary-1B training to show gradual improvement in GPU utilization leading up to 5x increase in average batch sizes versus its original training settings. This in turn allows us to train an equivalent model using 4x less GPUs in the same wall time, or leverage the original resources and train it in 2x shorter wall time. Finally, we observe that the major inference bottleneck lies in the autoregressive decoder steps. We find that adjusting the model architecture to transfer model parameters from the decoder to the encoder results in a 3x inference speedup as measured by inverse real-time factor (RTFx) while preserving the accuracy and compute requirements for convergence. The training code and models will be available as open-source.
Chain-of-Thought Prompting for Speech Translation
Sep 17, 2024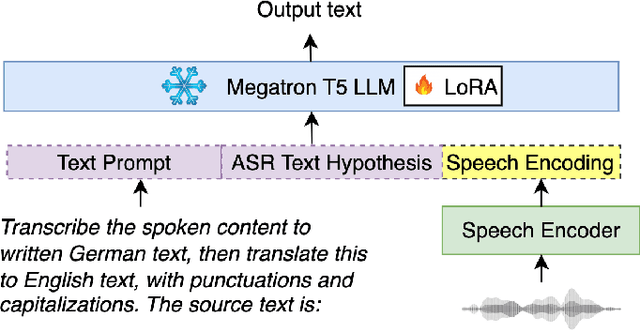
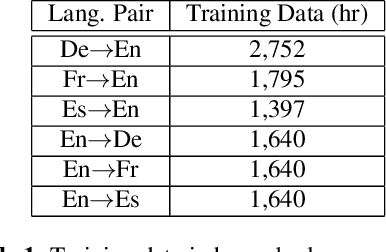
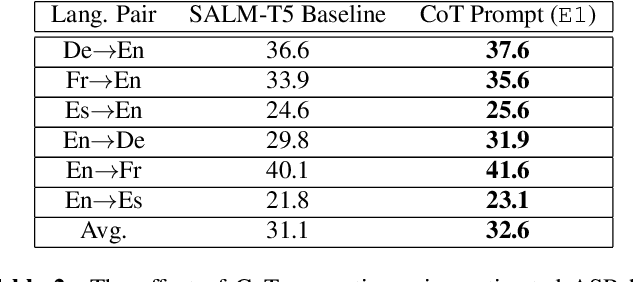
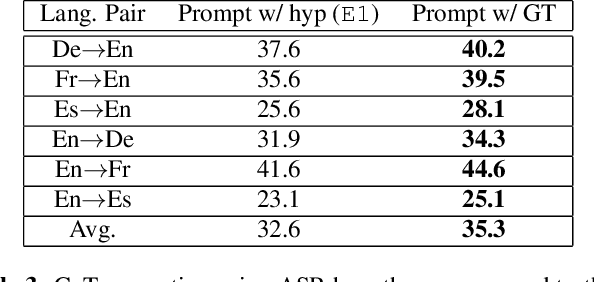
Large language models (LLMs) have demonstrated remarkable advancements in language understanding and generation. Building on the success of text-based LLMs, recent research has adapted these models to use speech embeddings for prompting, resulting in Speech-LLM models that exhibit strong performance in automatic speech recognition (ASR) and automatic speech translation (AST). In this work, we propose a novel approach to leverage ASR transcripts as prompts for AST in a Speech-LLM built on an encoder-decoder text LLM. The Speech-LLM model consists of a speech encoder and an encoder-decoder structure Megatron-T5. By first decoding speech to generate ASR transcripts and subsequently using these transcripts along with encoded speech for prompting, we guide the speech translation in a two-step process like chain-of-thought (CoT) prompting. Low-rank adaptation (LoRA) is used for the T5 LLM for model adaptation and shows superior performance to full model fine-tuning. Experimental results show that the proposed CoT prompting significantly improves AST performance, achieving an average increase of 2.4 BLEU points across 6 En->X or X->En AST tasks compared to speech prompting alone. Additionally, compared to a related CoT prediction method that predicts a concatenated sequence of ASR and AST transcripts, our method performs better by an average of 2 BLEU points.
Large Language Model Based Generative Error Correction: A Challenge and Baselines for Speech Recognition, Speaker Tagging, and Emotion Recognition
Sep 17, 2024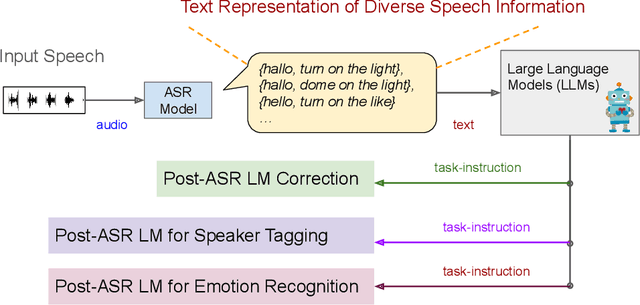
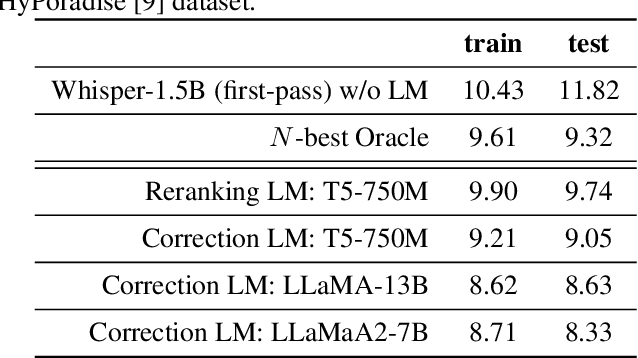
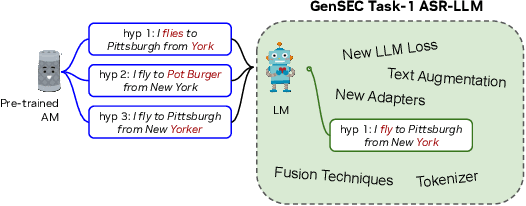
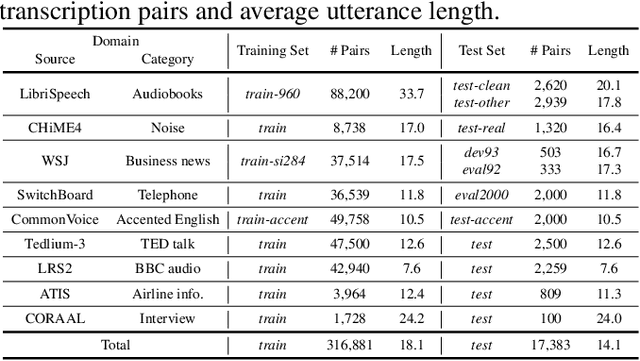
Given recent advances in generative AI technology, a key question is how large language models (LLMs) can enhance acoustic modeling tasks using text decoding results from a frozen, pretrained automatic speech recognition (ASR) model. To explore new capabilities in language modeling for speech processing, we introduce the generative speech transcription error correction (GenSEC) challenge. This challenge comprises three post-ASR language modeling tasks: (i) post-ASR transcription correction, (ii) speaker tagging, and (iii) emotion recognition. These tasks aim to emulate future LLM-based agents handling voice-based interfaces while remaining accessible to a broad audience by utilizing open pretrained language models or agent-based APIs. We also discuss insights from baseline evaluations, as well as lessons learned for designing future evaluations.
BESTOW: Efficient and Streamable Speech Language Model with the Best of Two Worlds in GPT and T5
Jun 28, 2024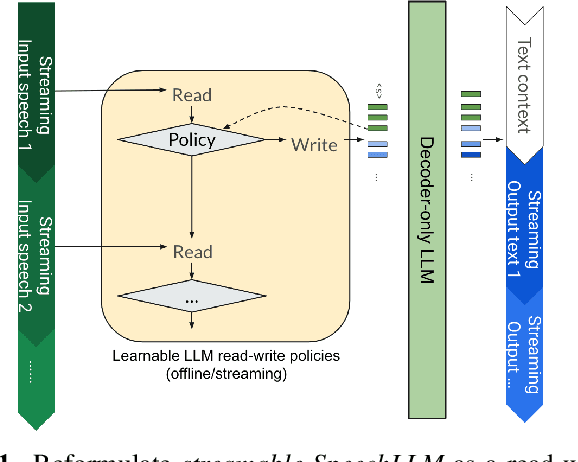
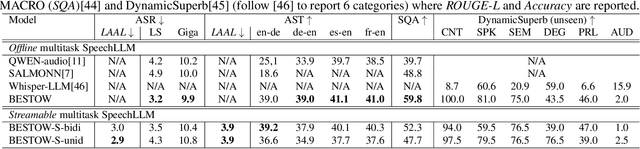
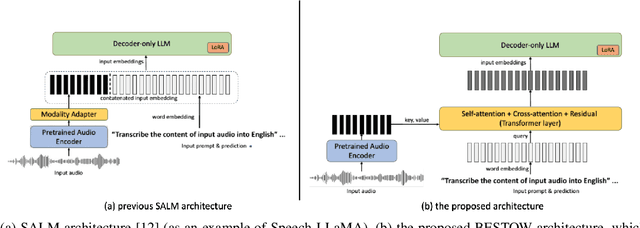

Incorporating speech understanding capabilities into pretrained large-language models has become a vital research direction (SpeechLLM). The previous architectures can be categorized as: i) GPT-style, prepend speech prompts to the text prompts as a sequence of LLM inputs like a decoder-only model; ii) T5-style, introduce speech cross-attention to each layer of the pretrained LLMs. We propose BESTOW architecture to bring the BESt features from TwO Worlds into a single model that is highly efficient and has strong multitask capabilities. Moreover, there is no clear streaming solution for either style, especially considering the solution should generalize to speech multitask. We reformulate streamable SpeechLLM as a read-write policy problem and unifies the offline and streaming research with BESTOW architecture. Hence we demonstrate the first open-source SpeechLLM solution that enables Streaming and Multitask at scale (beyond ASR) at the same time. This streamable solution achieves very strong performance on a wide range of speech tasks (ASR, AST, SQA, unseen DynamicSuperb). It is end-to-end optimizable, with lower training/inference cost, and demonstrates LLM knowledge transferability to speech.
Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Jun 28, 2024Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 26, 2023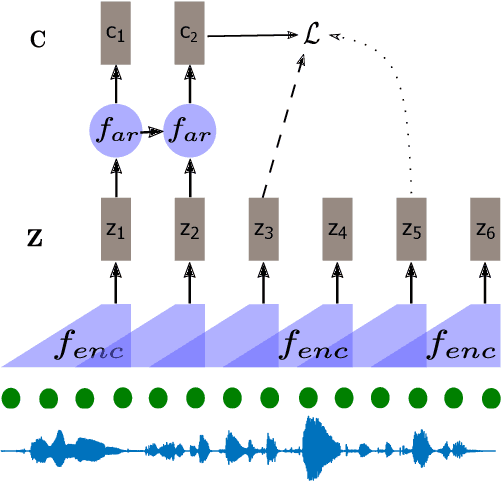
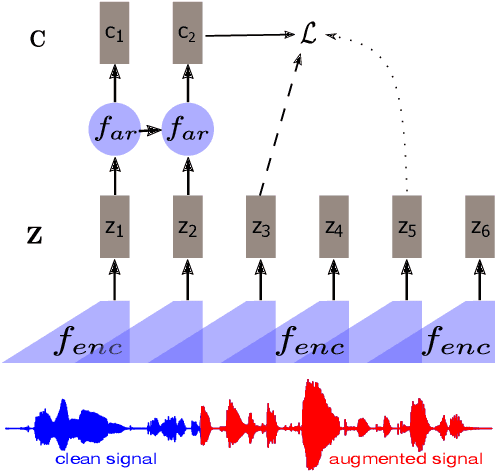
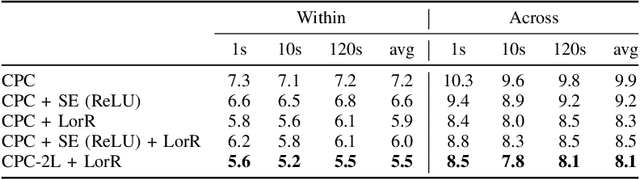
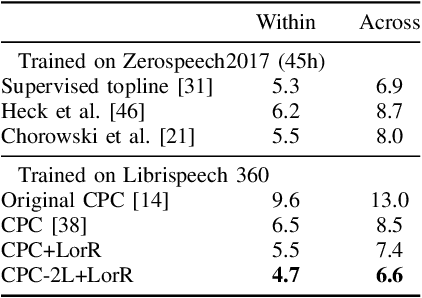
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-Right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models on the ABX task.
Fast and parallel decoding for transducer
Oct 31, 2022The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.