 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBESTOW: Efficient and Streamable Speech Language Model with the Best of Two Worlds in GPT and T5
Paper and Code
Jun 28, 2024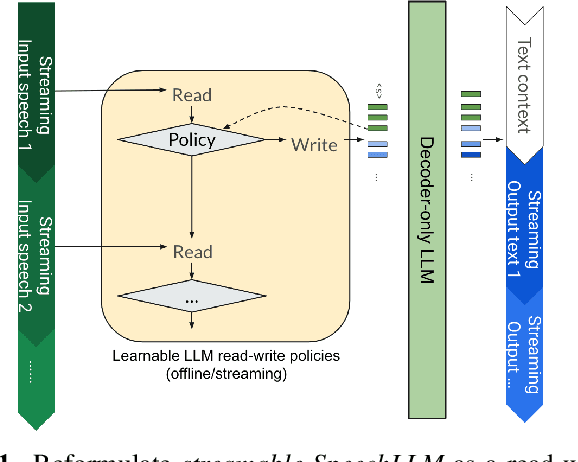
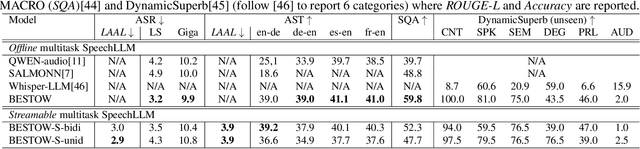
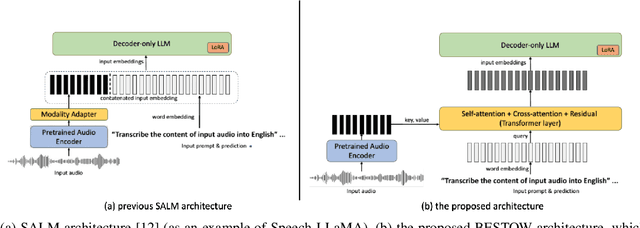

Incorporating speech understanding capabilities into pretrained large-language models has become a vital research direction (SpeechLLM). The previous architectures can be categorized as: i) GPT-style, prepend speech prompts to the text prompts as a sequence of LLM inputs like a decoder-only model; ii) T5-style, introduce speech cross-attention to each layer of the pretrained LLMs. We propose BESTOW architecture to bring the BESt features from TwO Worlds into a single model that is highly efficient and has strong multitask capabilities. Moreover, there is no clear streaming solution for either style, especially considering the solution should generalize to speech multitask. We reformulate streamable SpeechLLM as a read-write policy problem and unifies the offline and streaming research with BESTOW architecture. Hence we demonstrate the first open-source SpeechLLM solution that enables Streaming and Multitask at scale (beyond ASR) at the same time. This streamable solution achieves very strong performance on a wide range of speech tasks (ASR, AST, SQA, unseen DynamicSuperb). It is end-to-end optimizable, with lower training/inference cost, and demonstrates LLM knowledge transferability to speech.