 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
SWAN-GPT: An Efficient and Scalable Approach for Long-Context Language Modeling
Apr 11, 2025We present a decoder-only Transformer architecture that robustly generalizes to sequence lengths substantially longer than those seen during training. Our model, SWAN-GPT, interleaves layers without positional encodings (NoPE) and sliding-window attention layers equipped with rotary positional encodings (SWA-RoPE). Experiments demonstrate strong performance on sequence lengths significantly longer than the training length without the need for additional long-context training. This robust length extrapolation is achieved through our novel architecture, enhanced by a straightforward dynamic scaling of attention scores during inference. In addition, SWAN-GPT is more computationally efficient than standard GPT architectures, resulting in cheaper training and higher throughput. Further, we demonstrate that existing pre-trained decoder-only models can be efficiently converted to the SWAN architecture with minimal continued training, enabling longer contexts. Overall, our work presents an effective approach for scaling language models to longer contexts in a robust and efficient manner.
Training and Inference Efficiency of Encoder-Decoder Speech Models
Mar 07, 2025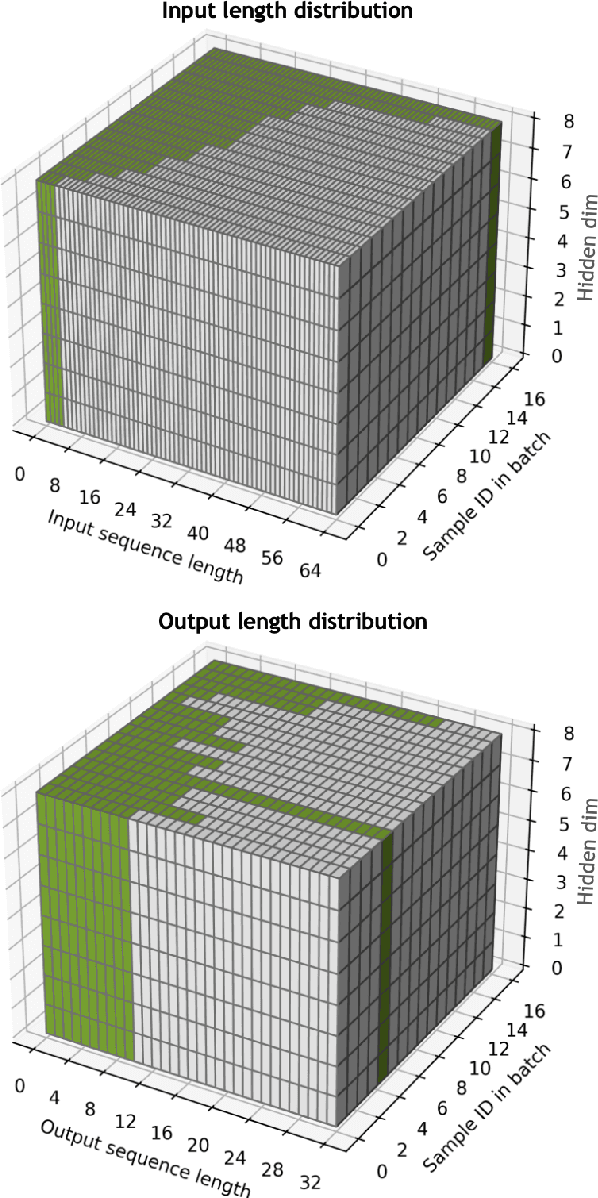

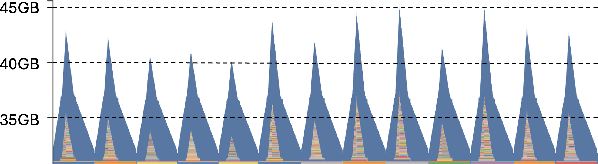
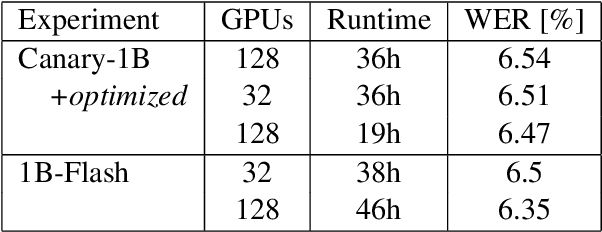
Attention encoder-decoder model architecture is the backbone of several recent top performing foundation speech models: Whisper, Seamless, OWSM, and Canary-1B. However, the reported data and compute requirements for their training are prohibitive for many in the research community. In this work, we focus on the efficiency angle and ask the questions of whether we are training these speech models efficiently, and what can we do to improve? We argue that a major, if not the most severe, detrimental factor for training efficiency is related to the sampling strategy of sequential data. We show that negligence in mini-batch sampling leads to more than 50% computation being spent on padding. To that end, we study, profile, and optimize Canary-1B training to show gradual improvement in GPU utilization leading up to 5x increase in average batch sizes versus its original training settings. This in turn allows us to train an equivalent model using 4x less GPUs in the same wall time, or leverage the original resources and train it in 2x shorter wall time. Finally, we observe that the major inference bottleneck lies in the autoregressive decoder steps. We find that adjusting the model architecture to transfer model parameters from the decoder to the encoder results in a 3x inference speedup as measured by inverse real-time factor (RTFx) while preserving the accuracy and compute requirements for convergence. The training code and models will be available as open-source.
VoiceTextBlender: Augmenting Large Language Models with Speech Capabilities via Single-Stage Joint Speech-Text Supervised Fine-Tuning
Oct 23, 2024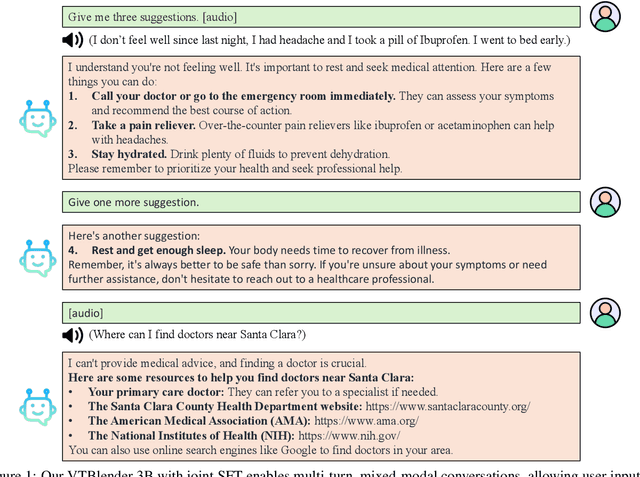
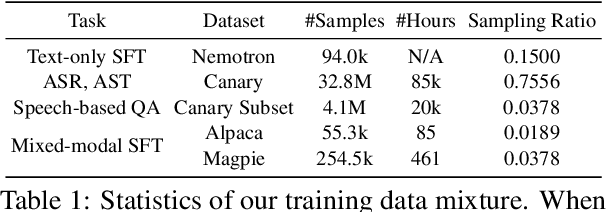
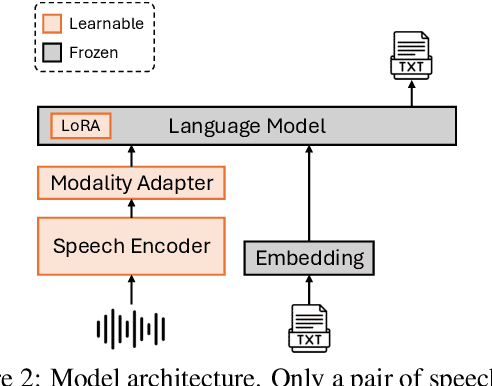
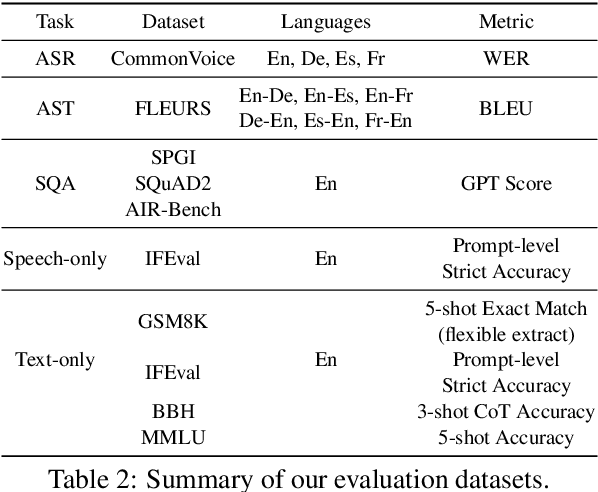
Recent studies have augmented large language models (LLMs) with speech capabilities, leading to the development of speech language models (SpeechLMs). Earlier SpeechLMs focused on single-turn speech-based question answering (QA), where user input comprised a speech context and a text question. More recent studies have extended this to multi-turn conversations, though they often require complex, multi-stage supervised fine-tuning (SFT) with diverse data. Another critical challenge with SpeechLMs is catastrophic forgetting-where models optimized for speech tasks suffer significant degradation in text-only performance. To mitigate these issues, we propose a novel single-stage joint speech-text SFT approach on the low-rank adaptation (LoRA) of the LLM backbone. Our joint SFT combines text-only SFT data with three types of speech-related data: speech recognition and translation, speech-based QA, and mixed-modal SFT. Compared to previous SpeechLMs with 7B or 13B parameters, our 3B model demonstrates superior performance across various speech benchmarks while preserving the original capabilities on text-only tasks. Furthermore, our model shows emergent abilities of effectively handling previously unseen prompts and tasks, including multi-turn, mixed-modal inputs.
Sortformer: Seamless Integration of Speaker Diarization and ASR by Bridging Timestamps and Tokens
Sep 10, 2024



We propose Sortformer, a novel neural model for speaker diarization, trained with unconventional objectives compared to existing end-to-end diarization models. The permutation problem in speaker diarization has long been regarded as a critical challenge. Most prior end-to-end diarization systems employ permutation invariant loss (PIL), which optimizes for the permutation that yields the lowest error. In contrast, we introduce Sort Loss, which enables a diarization model to autonomously resolve permutation, with or without PIL. We demonstrate that combining Sort Loss and PIL achieves performance competitive with state-of-the-art end-to-end diarization models trained exclusively with PIL. Crucially, we present a streamlined multispeaker ASR architecture that leverages Sortformer as a speaker supervision model, embedding speaker label estimation within the ASR encoder state using a sinusoidal kernel function. This approach resolves the speaker permutation problem through sorted objectives, effectively bridging speaker-label timestamps and speaker tokens. In our experiments, we show that the proposed multispeaker ASR architecture, enhanced with speaker supervision, improves performance via adapter techniques. Code and trained models will be made publicly available via the NVIDIA NeMo framework
Resource-Efficient Adaptation of Speech Foundation Models for Multi-Speaker ASR
Sep 02, 2024
Speech foundation models have achieved state-of-the-art (SoTA) performance across various tasks, such as automatic speech recognition (ASR) in hundreds of languages. However, multi-speaker ASR remains a challenging task for these models due to data scarcity and sparsity. In this paper, we present approaches to enable speech foundation models to process and understand multi-speaker speech with limited training data. Specifically, we adapt a speech foundation model for the multi-speaker ASR task using only telephonic data. Remarkably, the adapted model also performs well on meeting data without any fine-tuning, demonstrating the generalization ability of our approach. We conduct several ablation studies to analyze the impact of different parameters and strategies on model performance. Our findings highlight the effectiveness of our methods. Results show that less parameters give better overall cpWER, which, although counter-intuitive, provides insights into adapting speech foundation models for multi-speaker ASR tasks with minimal annotated data.
NEST: Self-supervised Fast Conformer as All-purpose Seasoning to Speech Processing Tasks
Aug 23, 2024



Self-supervised learning has been proved to benefit a wide range of speech processing tasks, such as speech recognition/translation, speaker verification and diarization, etc. However, most of these approaches are computationally intensive due to using transformer encoder and lack of sub-sampling. In this paper, we propose a new self-supervised learning model termed as Neural Encoder for Self-supervised Training (NEST). Specifically, we adopt the FastConformer architecture, which has an 8x sub-sampling rate and is faster than Transformer or Conformer architectures. Instead of clustering-based token generation, we resort to fixed random projection for its simplicity and effectiveness. We also propose a generalized noisy speech augmentation that teaches the model to disentangle the main speaker from noise or other speakers. Experiments show that the proposed NEST model improves over existing self-supervised models on a variety of speech processing tasks. Code and checkpoints will be publicly available via NVIDIA NeMo toolkit.
Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Jun 28, 2024Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
BESTOW: Efficient and Streamable Speech Language Model with the Best of Two Worlds in GPT and T5
Jun 28, 2024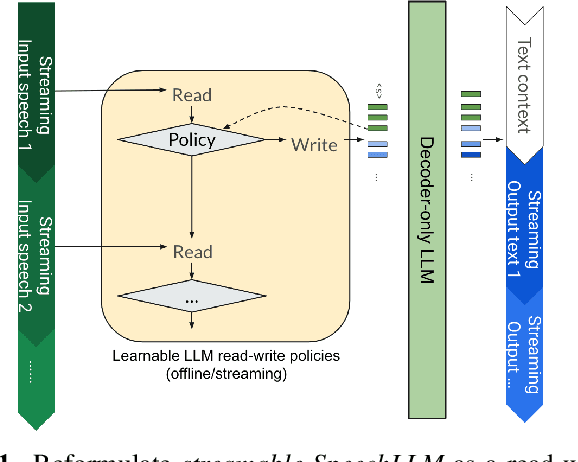
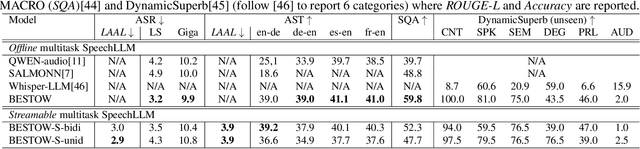
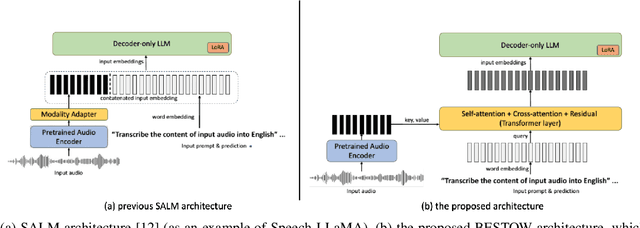

Incorporating speech understanding capabilities into pretrained large-language models has become a vital research direction (SpeechLLM). The previous architectures can be categorized as: i) GPT-style, prepend speech prompts to the text prompts as a sequence of LLM inputs like a decoder-only model; ii) T5-style, introduce speech cross-attention to each layer of the pretrained LLMs. We propose BESTOW architecture to bring the BESt features from TwO Worlds into a single model that is highly efficient and has strong multitask capabilities. Moreover, there is no clear streaming solution for either style, especially considering the solution should generalize to speech multitask. We reformulate streamable SpeechLLM as a read-write policy problem and unifies the offline and streaming research with BESTOW architecture. Hence we demonstrate the first open-source SpeechLLM solution that enables Streaming and Multitask at scale (beyond ASR) at the same time. This streamable solution achieves very strong performance on a wide range of speech tasks (ASR, AST, SQA, unseen DynamicSuperb). It is end-to-end optimizable, with lower training/inference cost, and demonstrates LLM knowledge transferability to speech.