 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Anticipating Future with Large Language Model for Simultaneous Machine Translation
Oct 29, 2024



Simultaneous machine translation (SMT) takes streaming input utterances and incrementally produces target text. Existing SMT methods only use the partial utterance that has already arrived at the input and the generated hypothesis. Motivated by human interpreters' technique to forecast future words before hearing them, we propose $\textbf{T}$ranslation by $\textbf{A}$nticipating $\textbf{F}$uture (TAF), a method to improve translation quality while retraining low latency. Its core idea is to use a large language model (LLM) to predict future source words and opportunistically translate without introducing too much risk. We evaluate our TAF and multiple baselines of SMT on four language directions. Experiments show that TAF achieves the best translation quality-latency trade-off and outperforms the baselines by up to 5 BLEU points at the same latency (three words).
Chain-of-Thought Prompting for Speech Translation
Sep 17, 2024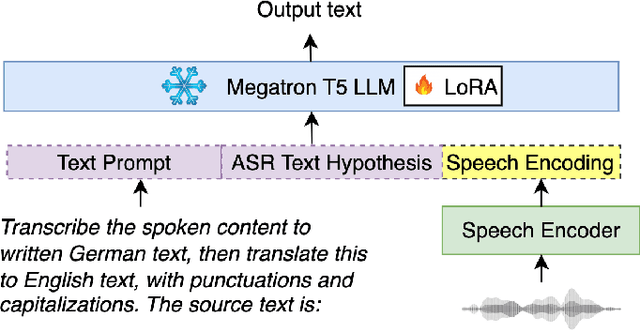
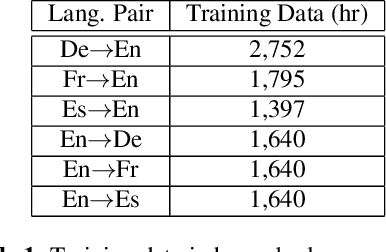
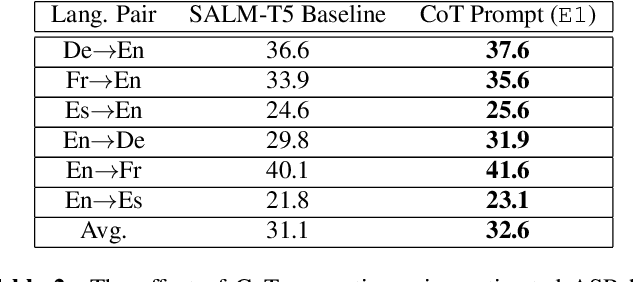
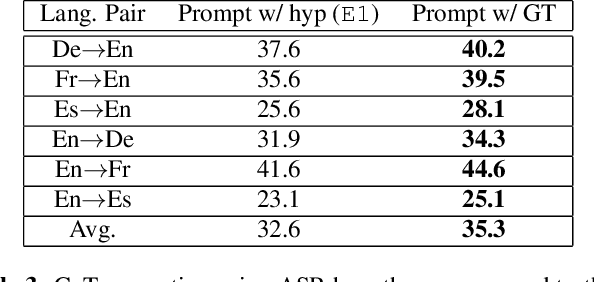
Large language models (LLMs) have demonstrated remarkable advancements in language understanding and generation. Building on the success of text-based LLMs, recent research has adapted these models to use speech embeddings for prompting, resulting in Speech-LLM models that exhibit strong performance in automatic speech recognition (ASR) and automatic speech translation (AST). In this work, we propose a novel approach to leverage ASR transcripts as prompts for AST in a Speech-LLM built on an encoder-decoder text LLM. The Speech-LLM model consists of a speech encoder and an encoder-decoder structure Megatron-T5. By first decoding speech to generate ASR transcripts and subsequently using these transcripts along with encoded speech for prompting, we guide the speech translation in a two-step process like chain-of-thought (CoT) prompting. Low-rank adaptation (LoRA) is used for the T5 LLM for model adaptation and shows superior performance to full model fine-tuning. Experimental results show that the proposed CoT prompting significantly improves AST performance, achieving an average increase of 2.4 BLEU points across 6 En->X or X->En AST tasks compared to speech prompting alone. Additionally, compared to a related CoT prediction method that predicts a concatenated sequence of ASR and AST transcripts, our method performs better by an average of 2 BLEU points.
Longer is (Not Necessarily) Stronger: Punctuated Long-Sequence Training for Enhanced Speech Recognition and Translation
Sep 09, 2024
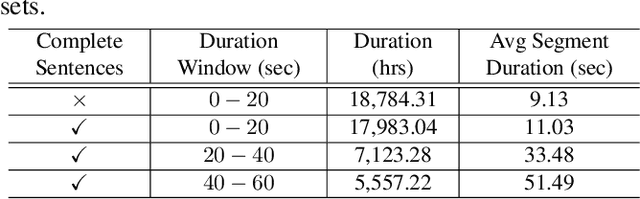

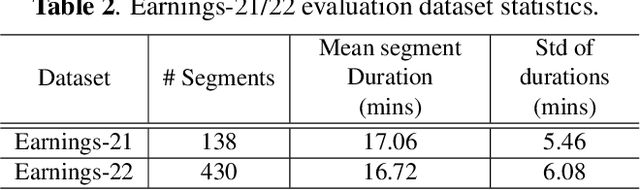
This paper presents a new method for training sequence-to-sequence models for speech recognition and translation tasks. Instead of the traditional approach of training models on short segments containing only lowercase or partial punctuation and capitalization (PnC) sentences, we propose training on longer utterances that include complete sentences with proper punctuation and capitalization. We achieve this by using the FastConformer architecture which allows training 1 Billion parameter models with sequences up to 60 seconds long with full attention. However, while training with PnC enhances the overall performance, we observed that accuracy plateaus when training on sequences longer than 40 seconds across various evaluation settings. Our proposed method significantly improves punctuation and capitalization accuracy, showing a 25% relative word error rate (WER) improvement on the Earnings-21 and Earnings-22 benchmarks. Additionally, training on longer audio segments increases the overall model accuracy across speech recognition and translation benchmarks. The model weights and training code are open-sourced though NVIDIA NeMo.
BESTOW: Efficient and Streamable Speech Language Model with the Best of Two Worlds in GPT and T5
Jun 28, 2024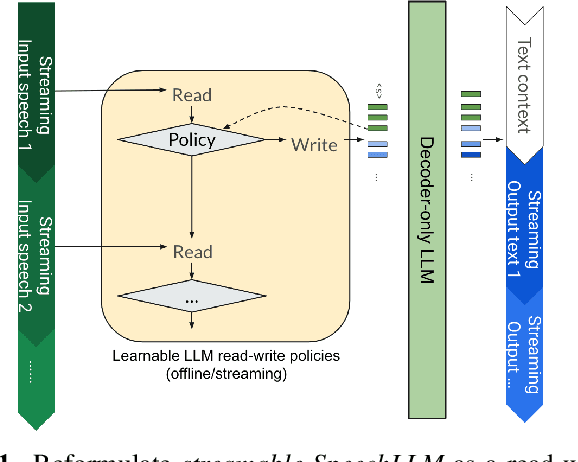
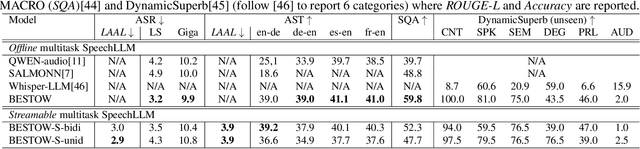
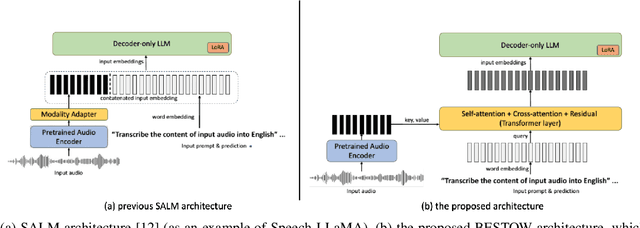

Incorporating speech understanding capabilities into pretrained large-language models has become a vital research direction (SpeechLLM). The previous architectures can be categorized as: i) GPT-style, prepend speech prompts to the text prompts as a sequence of LLM inputs like a decoder-only model; ii) T5-style, introduce speech cross-attention to each layer of the pretrained LLMs. We propose BESTOW architecture to bring the BESt features from TwO Worlds into a single model that is highly efficient and has strong multitask capabilities. Moreover, there is no clear streaming solution for either style, especially considering the solution should generalize to speech multitask. We reformulate streamable SpeechLLM as a read-write policy problem and unifies the offline and streaming research with BESTOW architecture. Hence we demonstrate the first open-source SpeechLLM solution that enables Streaming and Multitask at scale (beyond ASR) at the same time. This streamable solution achieves very strong performance on a wide range of speech tasks (ASR, AST, SQA, unseen DynamicSuperb). It is end-to-end optimizable, with lower training/inference cost, and demonstrates LLM knowledge transferability to speech.
Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Jun 28, 2024Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
SALM: Speech-augmented Language Model with In-context Learning for Speech Recognition and Translation
Oct 13, 2023
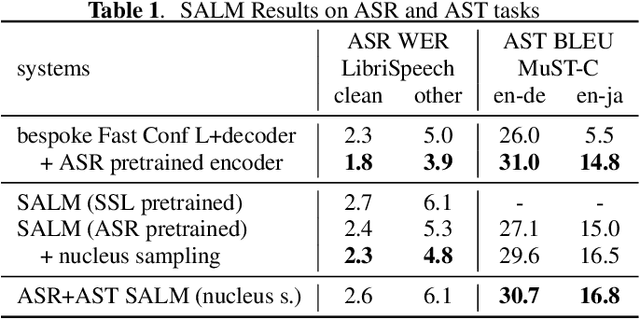


We present a novel Speech Augmented Language Model (SALM) with {\em multitask} and {\em in-context} learning capabilities. SALM comprises a frozen text LLM, a audio encoder, a modality adapter module, and LoRA layers to accommodate speech input and associated task instructions. The unified SALM not only achieves performance on par with task-specific Conformer baselines for Automatic Speech Recognition (ASR) and Speech Translation (AST), but also exhibits zero-shot in-context learning capabilities, demonstrated through keyword-boosting task for ASR and AST. Moreover, {\em speech supervised in-context training} is proposed to bridge the gap between LLM training and downstream speech tasks, which further boosts the in-context learning ability of speech-to-text models. Proposed model is open-sourced via NeMo toolkit.
Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
May 19, 2023



Conformer-based models have become the most dominant end-to-end architecture for speech processing tasks. In this work, we propose a carefully redesigned Conformer with a new down-sampling schema. The proposed model, named Fast Conformer, is 2.8x faster than original Conformer, while preserving state-of-the-art accuracy on Automatic Speech Recognition benchmarks. Also we replace the original Conformer global attention with limited context attention post-training to enable transcription of an hour-long audio. We further improve long-form speech transcription by adding a global token. Fast Conformer combined with a Transformer decoder also outperforms the original Conformer in accuracy and in speed for Speech Translation and Spoken Language Understanding.