 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLonger is (Not Necessarily) Stronger: Punctuated Long-Sequence Training for Enhanced Speech Recognition and Translation
Paper and Code
Sep 09, 2024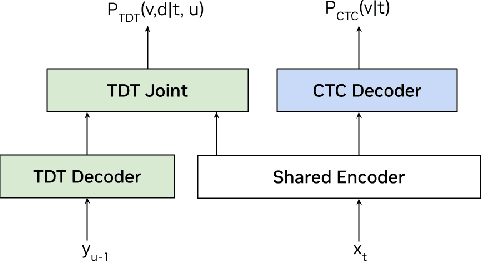
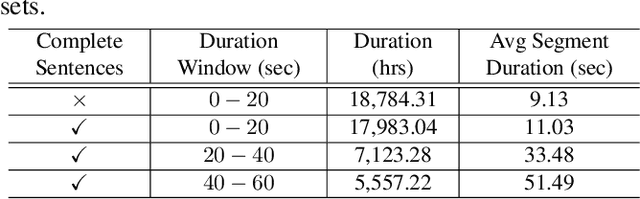

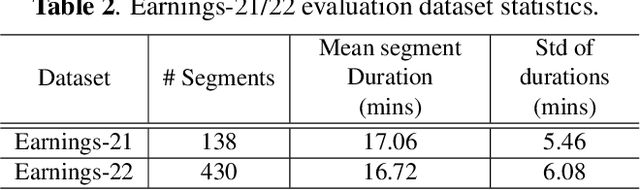
This paper presents a new method for training sequence-to-sequence models for speech recognition and translation tasks. Instead of the traditional approach of training models on short segments containing only lowercase or partial punctuation and capitalization (PnC) sentences, we propose training on longer utterances that include complete sentences with proper punctuation and capitalization. We achieve this by using the FastConformer architecture which allows training 1 Billion parameter models with sequences up to 60 seconds long with full attention. However, while training with PnC enhances the overall performance, we observed that accuracy plateaus when training on sequences longer than 40 seconds across various evaluation settings. Our proposed method significantly improves punctuation and capitalization accuracy, showing a 25% relative word error rate (WER) improvement on the Earnings-21 and Earnings-22 benchmarks. Additionally, training on longer audio segments increases the overall model accuracy across speech recognition and translation benchmarks. The model weights and training code are open-sourced though NVIDIA NeMo.