 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLonger is (Not Necessarily) Stronger: Punctuated Long-Sequence Training for Enhanced Speech Recognition and Translation
Sep 09, 2024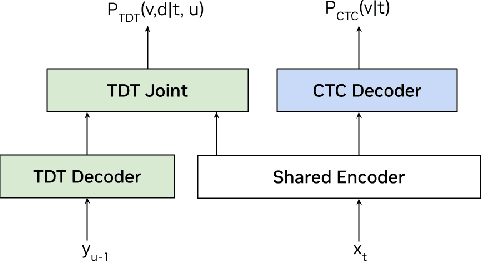
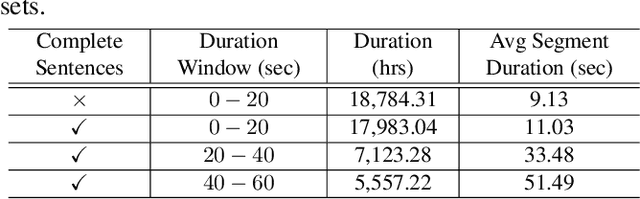

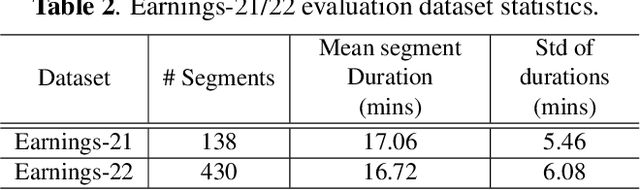
This paper presents a new method for training sequence-to-sequence models for speech recognition and translation tasks. Instead of the traditional approach of training models on short segments containing only lowercase or partial punctuation and capitalization (PnC) sentences, we propose training on longer utterances that include complete sentences with proper punctuation and capitalization. We achieve this by using the FastConformer architecture which allows training 1 Billion parameter models with sequences up to 60 seconds long with full attention. However, while training with PnC enhances the overall performance, we observed that accuracy plateaus when training on sequences longer than 40 seconds across various evaluation settings. Our proposed method significantly improves punctuation and capitalization accuracy, showing a 25% relative word error rate (WER) improvement on the Earnings-21 and Earnings-22 benchmarks. Additionally, training on longer audio segments increases the overall model accuracy across speech recognition and translation benchmarks. The model weights and training code are open-sourced though NVIDIA NeMo.
SPGISpeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition
Apr 06, 2021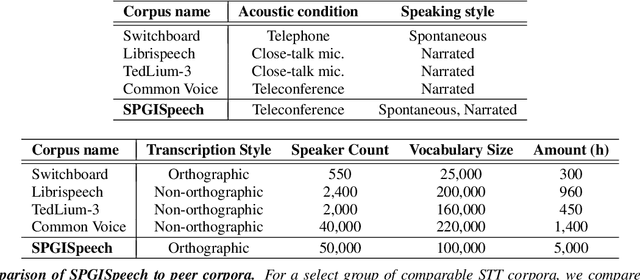
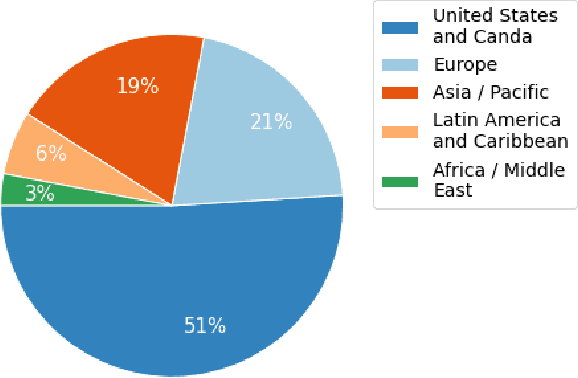

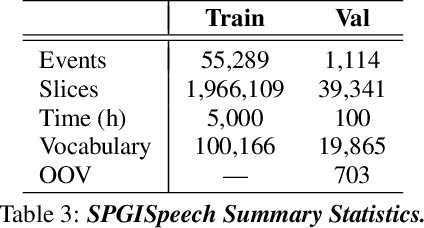
In the English speech-to-text (STT) machine learning task, acoustic models are conventionally trained on uncased Latin characters, and any necessary orthography (such as capitalization, punctuation, and denormalization of non-standard words) is imputed by separate post-processing models. This adds complexity and limits performance, as many formatting tasks benefit from semantic information present in the acoustic signal but absent in transcription. Here we propose a new STT task: end-to-end neural transcription with fully formatted text for target labels. We present baseline Conformer-based models trained on a corpus of 5,000 hours of professionally transcribed earnings calls, achieving a CER of 1.7. As a contribution to the STT research community, we release the corpus free for non-commercial use at https://datasets.kensho.com/datasets/scribe.