 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Dec 12, 2024It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30\% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50\%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023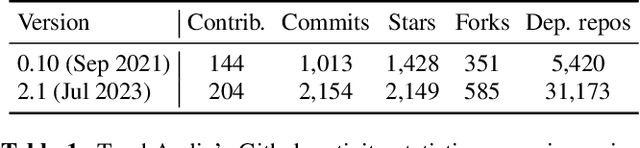


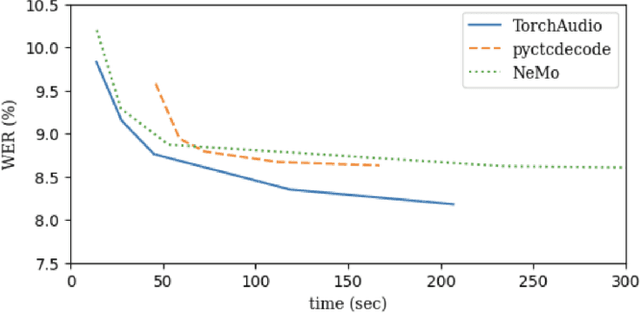
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
LightVessel: Exploring Lightweight Coronary Artery Vessel Segmentation via Similarity Knowledge Distillation
Nov 02, 2022In recent years, deep convolution neural networks (DCNNs) have achieved great prospects in coronary artery vessel segmentation. However, it is difficult to deploy complicated models in clinical scenarios since high-performance approaches have excessive parameters and high computation costs. To tackle this problem, we propose \textbf{LightVessel}, a Similarity Knowledge Distillation Framework, for lightweight coronary artery vessel segmentation. Primarily, we propose a Feature-wise Similarity Distillation (FSD) module for semantic-shift modeling. Specifically, we calculate the feature similarity between the symmetric layers from the encoder and decoder. Then the similarity is transferred as knowledge from a cumbersome teacher network to a non-trained lightweight student network. Meanwhile, for encouraging the student model to learn more pixel-wise semantic information, we introduce the Adversarial Similarity Distillation (ASD) module. Concretely, the ASD module aims to construct the spatial adversarial correlation between the annotation and prediction from the teacher and student models, respectively. Through the ASD module, the student model obtains fined-grained subtle edge segmented results of the coronary artery vessel. Extensive experiments conducted on Clinical Coronary Artery Vessel Dataset demonstrate that LightVessel outperforms various knowledge distillation counterparts.
TrimTail: Low-Latency Streaming ASR with Simple but Effective Spectrogram-Level Length Penalty
Nov 01, 2022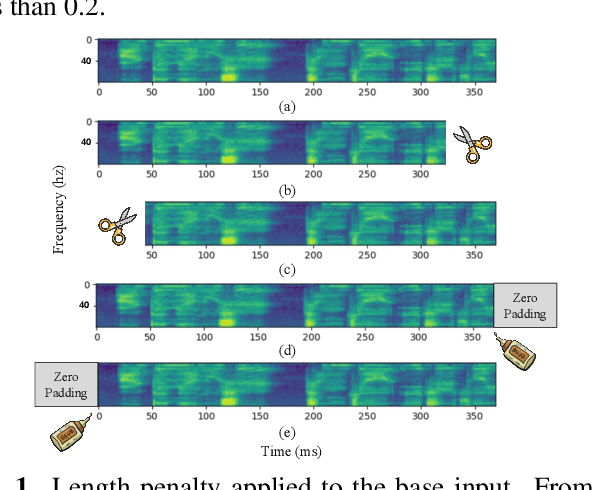



In this paper, we present TrimTail, a simple but effective emission regularization method to improve the latency of streaming ASR models. The core idea of TrimTail is to apply length penalty (i.e., by trimming trailing frames, see Fig. 1-(b)) directly on the spectrogram of input utterances, which does not require any alignment. We demonstrate that TrimTail is computationally cheap and can be applied online and optimized with any training loss or any model architecture on any dataset without any extra effort by applying it on various end-to-end streaming ASR networks either trained with CTC loss [1] or Transducer loss [2]. We achieve 100 $\sim$ 200ms latency reduction with equal or even better accuracy on both Aishell-1 and Librispeech. Moreover, by using TrimTail, we can achieve a 400ms algorithmic improvement of User Sensitive Delay (USD) with an accuracy loss of less than 0.2.
ESPnet-SLU: Advancing Spoken Language Understanding through ESPnet
Nov 29, 2021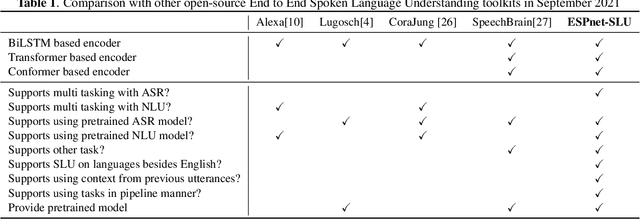
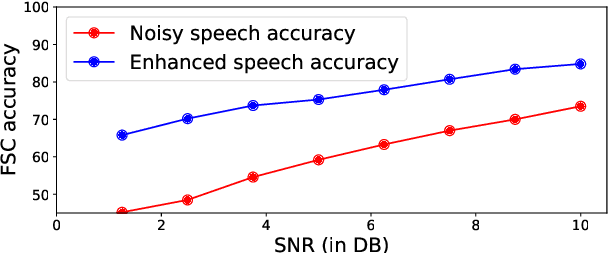
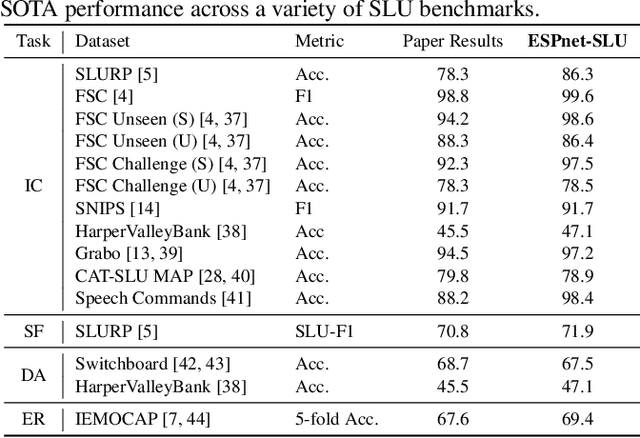

As Automatic Speech Processing (ASR) systems are getting better, there is an increasing interest of using the ASR output to do downstream Natural Language Processing (NLP) tasks. However, there are few open source toolkits that can be used to generate reproducible results on different Spoken Language Understanding (SLU) benchmarks. Hence, there is a need to build an open source standard that can be used to have a faster start into SLU research. We present ESPnet-SLU, which is designed for quick development of spoken language understanding in a single framework. ESPnet-SLU is a project inside end-to-end speech processing toolkit, ESPnet, which is a widely used open-source standard for various speech processing tasks like ASR, Text to Speech (TTS) and Speech Translation (ST). We enhance the toolkit to provide implementations for various SLU benchmarks that enable researchers to seamlessly mix-and-match different ASR and NLU models. We also provide pretrained models with intensively tuned hyper-parameters that can match or even outperform the current state-of-the-art performances. The toolkit is publicly available at https://github.com/espnet/espnet.
SPGISpeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition
Apr 06, 2021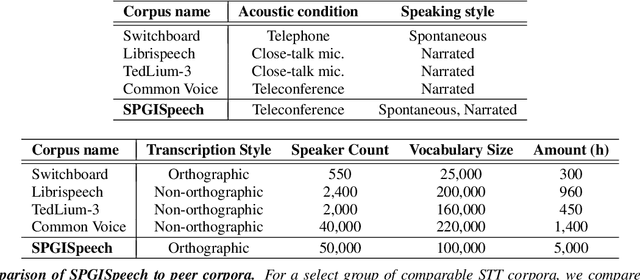

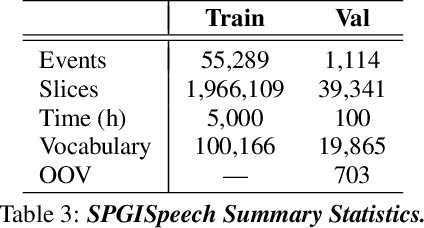
In the English speech-to-text (STT) machine learning task, acoustic models are conventionally trained on uncased Latin characters, and any necessary orthography (such as capitalization, punctuation, and denormalization of non-standard words) is imputed by separate post-processing models. This adds complexity and limits performance, as many formatting tasks benefit from semantic information present in the acoustic signal but absent in transcription. Here we propose a new STT task: end-to-end neural transcription with fully formatted text for target labels. We present baseline Conformer-based models trained on a corpus of 5,000 hours of professionally transcribed earnings calls, achieving a CER of 1.7. As a contribution to the STT research community, we release the corpus free for non-commercial use at https://datasets.kensho.com/datasets/scribe.
Tiny Transducer: A Highly-efficient Speech Recognition Model on Edge Devices
Feb 07, 2021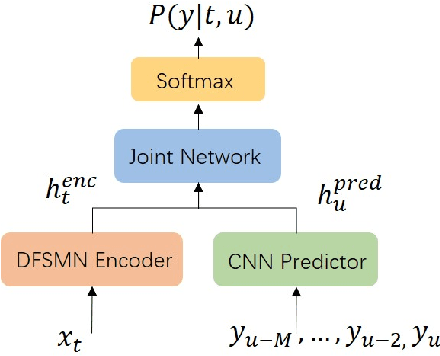
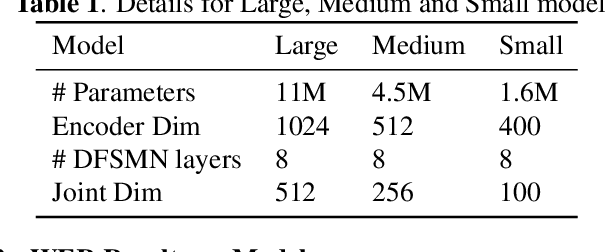
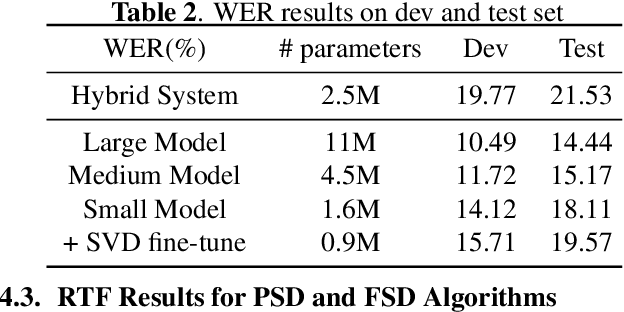
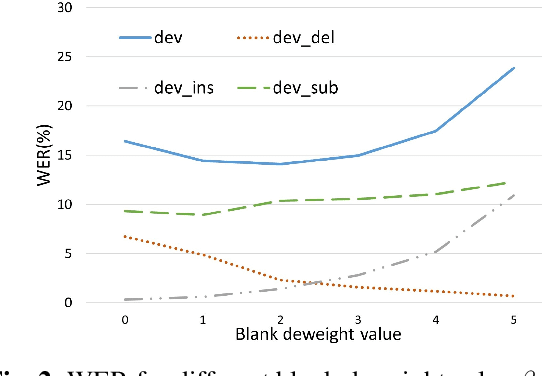
This paper proposes an extremely lightweight phone-based transducer model with a tiny decoding graph on edge devices. First, a phone synchronous decoding (PSD) algorithm based on blank label skipping is first used to speed up the transducer decoding process. Then, to decrease the deletion errors introduced by the high blank score, a blank label deweighting approach is proposed. To reduce parameters and computation, deep feedforward sequential memory network (DFSMN) layers are used in the transducer encoder, and a CNN-based stateless predictor is adopted. SVD technology compresses the model further. WFST-based decoding graph takes the context-independent (CI) phone posteriors as input and allows us to flexibly bias user-specific information. Finally, with only 0.9M parameters after SVD, our system could give a relative 9.1% - 20.5% improvement compared with a bigger conventional hybrid system on edge devices.
Sequence-to-sequence Singing Voice Synthesis with Perceptual Entropy Loss
Oct 22, 2020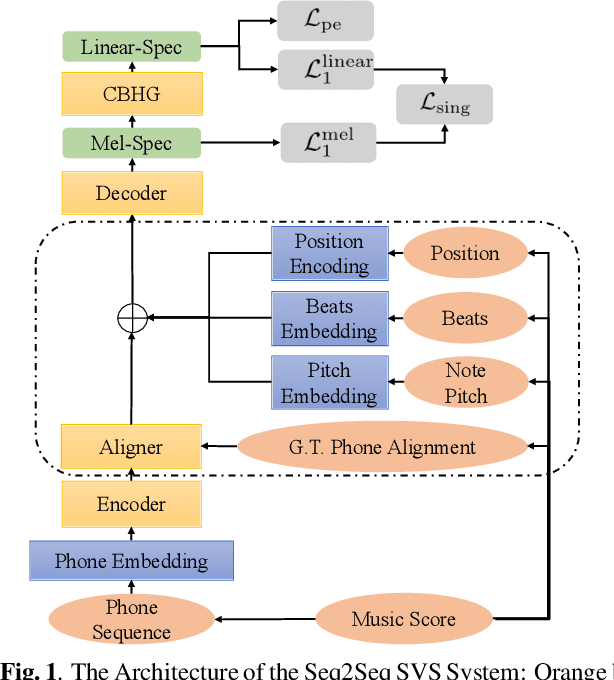
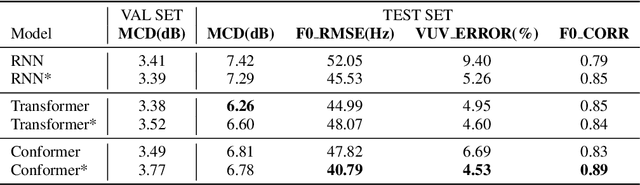
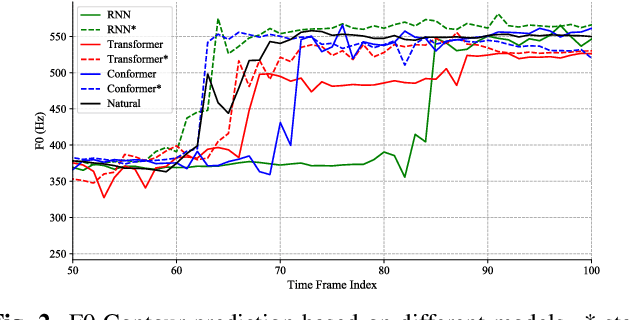
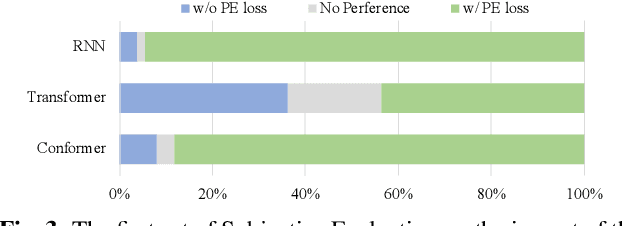
The neural network (NN) based singing voice synthesis (SVS) systems require sufficient data to train well. However, due to high data acquisition and annotation cost, we often encounter data limitation problem in building SVS systems. The NN based models are prone to over-fitting due to data scarcity. In this work, we propose a Perceptual Entropy (PE) loss derived from a psycho-acoustic hearing model to regularize the network. With a one-hour open-source singing voice database, we explore the impact of the PE loss on various mainstream sequence-to-sequence models, including the RNN-based model, transformer-based model, and conformer-based model. Our experiments show that the PE loss can mitigate the over-fitting problem and significantly improve the synthesized singing quality reflected in objective and subjective evaluations. Furthermore, incorporating the PE loss in model training is shown to help the F0-contour and high-frequency-band spectrum prediction.