 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Integration of Pre-trained SSL, ASR, LM and SLU Models for Spoken Language Understanding
Nov 10, 2022



Collecting sufficient labeled data for spoken language understanding (SLU) is expensive and time-consuming. Recent studies achieved promising results by using pre-trained models in low-resource scenarios. Inspired by this, we aim to ask: which (if any) pre-training strategies can improve performance across SLU benchmarks? To answer this question, we employ four types of pre-trained models and their combinations for SLU. We leverage self-supervised speech and language models (LM) pre-trained on large quantities of unpaired data to extract strong speech and text representations. We also explore using supervised models pre-trained on larger external automatic speech recognition (ASR) or SLU corpora. We conduct extensive experiments on the SLU Evaluation (SLUE) benchmark and observe self-supervised pre-trained models to be more powerful, with pre-trained LM and speech models being most beneficial for the Sentiment Analysis and Named Entity Recognition task, respectively.
EEND-SS: Joint End-to-End Neural Speaker Diarization and Speech Separation for Flexible Number of Speakers
Mar 31, 2022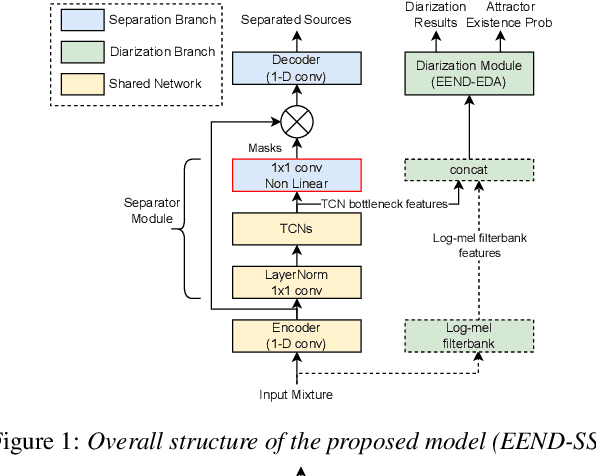
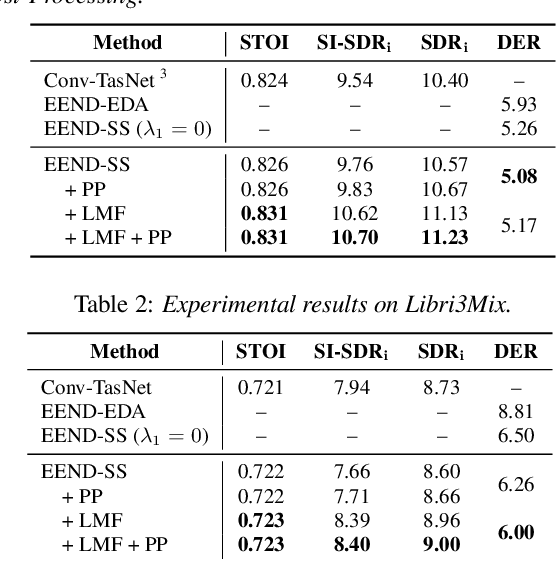

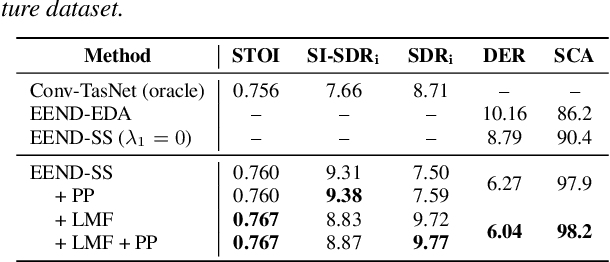
In this paper, we present a novel framework that jointly performs speaker diarization, speech separation, and speaker counting. Our proposed method combines end-to-end speaker diarization and speech separation methods, namely, End-to-End Neural Speaker Diarization with Encoder-Decoder-based Attractor calculation (EEND-EDA) and the Convolutional Time-domain Audio Separation Network (ConvTasNet) as multi-tasking joint model. We also propose the multiple 1x1 convolutional layer architecture for estimating the separation masks corresponding to the number of speakers, and a post-processing technique for refining the separated speech signal with speech activity. Experiments using LibriMix dataset show that our proposed method outperforms the baselines in terms of diarization and separation performance for both fixed and flexible numbers of speakers, as well as speaker counting performance for flexible numbers of speakers. All materials will be open-sourced and reproducible in ESPnet toolkit.
ESPnet-SLU: Advancing Spoken Language Understanding through ESPnet
Nov 29, 2021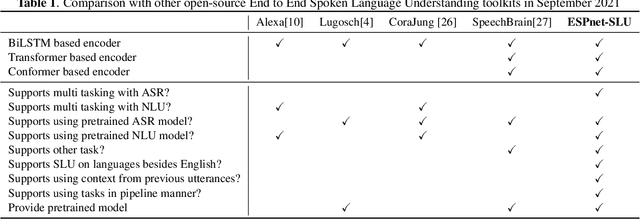
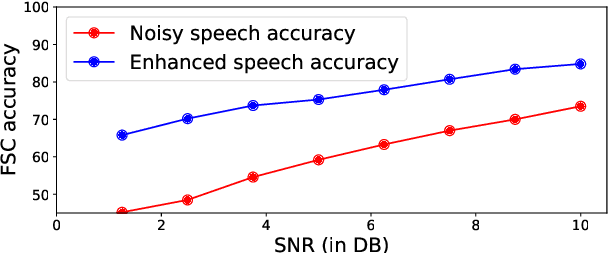
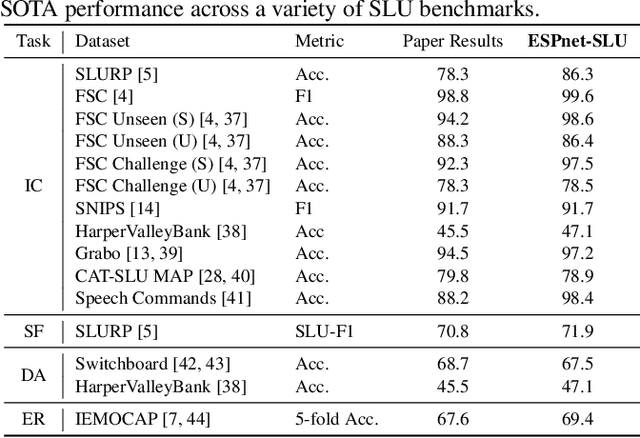

As Automatic Speech Processing (ASR) systems are getting better, there is an increasing interest of using the ASR output to do downstream Natural Language Processing (NLP) tasks. However, there are few open source toolkits that can be used to generate reproducible results on different Spoken Language Understanding (SLU) benchmarks. Hence, there is a need to build an open source standard that can be used to have a faster start into SLU research. We present ESPnet-SLU, which is designed for quick development of spoken language understanding in a single framework. ESPnet-SLU is a project inside end-to-end speech processing toolkit, ESPnet, which is a widely used open-source standard for various speech processing tasks like ASR, Text to Speech (TTS) and Speech Translation (ST). We enhance the toolkit to provide implementations for various SLU benchmarks that enable researchers to seamlessly mix-and-match different ASR and NLU models. We also provide pretrained models with intensively tuned hyper-parameters that can match or even outperform the current state-of-the-art performances. The toolkit is publicly available at https://github.com/espnet/espnet.