 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEND-SS: Joint End-to-End Neural Speaker Diarization and Speech Separation for Flexible Number of Speakers
Paper and Code
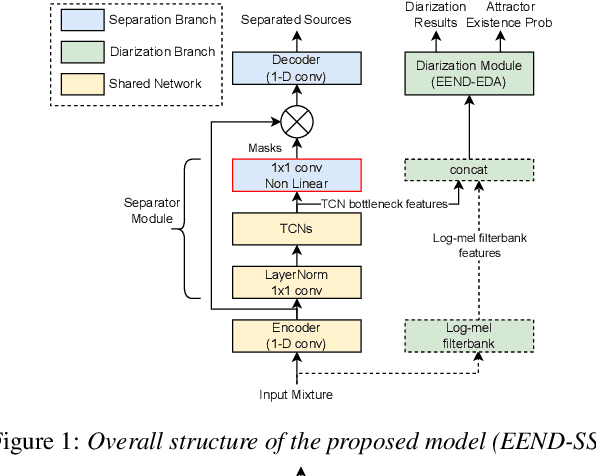
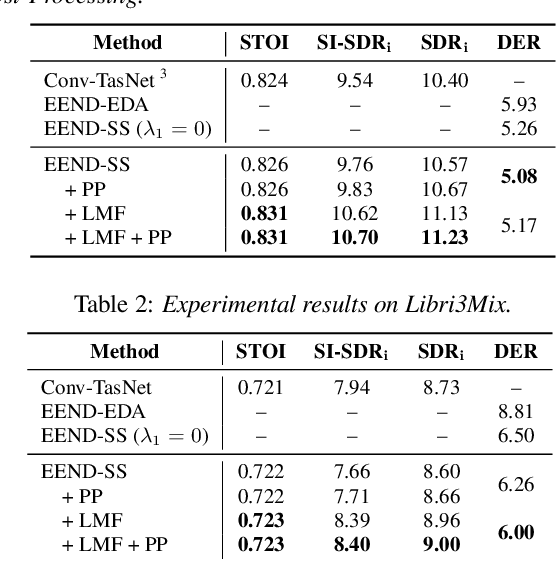

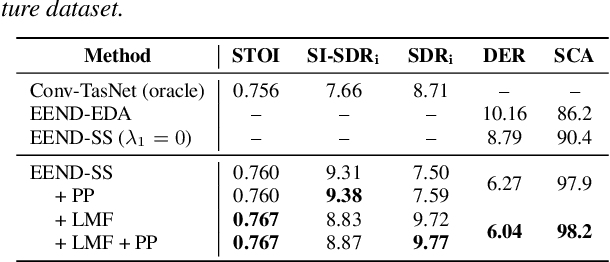
In this paper, we present a novel framework that jointly performs speaker diarization, speech separation, and speaker counting. Our proposed method combines end-to-end speaker diarization and speech separation methods, namely, End-to-End Neural Speaker Diarization with Encoder-Decoder-based Attractor calculation (EEND-EDA) and the Convolutional Time-domain Audio Separation Network (ConvTasNet) as multi-tasking joint model. We also propose the multiple 1x1 convolutional layer architecture for estimating the separation masks corresponding to the number of speakers, and a post-processing technique for refining the separated speech signal with speech activity. Experiments using LibriMix dataset show that our proposed method outperforms the baselines in terms of diarization and separation performance for both fixed and flexible numbers of speakers, as well as speaker counting performance for flexible numbers of speakers. All materials will be open-sourced and reproducible in ESPnet toolkit.