 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models
Dec 18, 2025While current multimodal models can answer questions based on 2D images, they lack intrinsic 3D object perception, limiting their ability to comprehend spatial relationships and depth cues in 3D scenes. In this work, we propose N3D-VLM, a novel unified framework that seamlessly integrates native 3D object perception with 3D-aware visual reasoning, enabling both precise 3D grounding and interpretable spatial understanding. Unlike conventional end-to-end models that directly predict answers from RGB/RGB-D inputs, our approach equips the model with native 3D object perception capabilities, enabling it to directly localize objects in 3D space based on textual descriptions. Building upon accurate 3D object localization, the model further performs explicit reasoning in 3D, achieving more interpretable and structured spatial understanding. To support robust training for these capabilities, we develop a scalable data construction pipeline that leverages depth estimation to lift large-scale 2D annotations into 3D space, significantly increasing the diversity and coverage for 3D object grounding data, yielding over six times larger than the largest existing single-image 3D detection dataset. Moreover, the pipeline generates spatial question-answering datasets that target chain-of-thought (CoT) reasoning in 3D, facilitating joint training for both 3D object localization and 3D spatial reasoning. Experimental results demonstrate that our unified framework not only achieves state-of-the-art performance on 3D grounding tasks, but also consistently surpasses existing methods in 3D spatial reasoning in vision-language model.
Audio-Thinker: Guiding Audio Language Model When and How to Think via Reinforcement Learning
Aug 12, 2025Recent advancements in large language models, multimodal large language models, and large audio language models (LALMs) have significantly improved their reasoning capabilities through reinforcement learning with rule-based rewards. However, the explicit reasoning process has yet to show significant benefits for audio question answering, and effectively leveraging deep reasoning remains an open challenge, with LALMs still falling short of human-level auditory-language reasoning. To address these limitations, we propose Audio-Thinker, a reinforcement learning framework designed to enhance the reasoning capabilities of LALMs, with a focus on improving adaptability, consistency, and effectiveness. Our approach introduces an adaptive think accuracy reward, enabling the model to adjust its reasoning strategies based on task complexity dynamically. Furthermore, we incorporate an external reward model to evaluate the overall consistency and quality of the reasoning process, complemented by think-based rewards that help the model distinguish between valid and flawed reasoning paths during training. Experimental results demonstrate that our Audio-Thinker model outperforms existing reasoning-oriented LALMs across various benchmark tasks, exhibiting superior reasoning and generalization capabilities.
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Mar 17, 2025The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
LLM-Enhanced Dialogue Management for Full-Duplex Spoken Dialogue Systems
Feb 19, 2025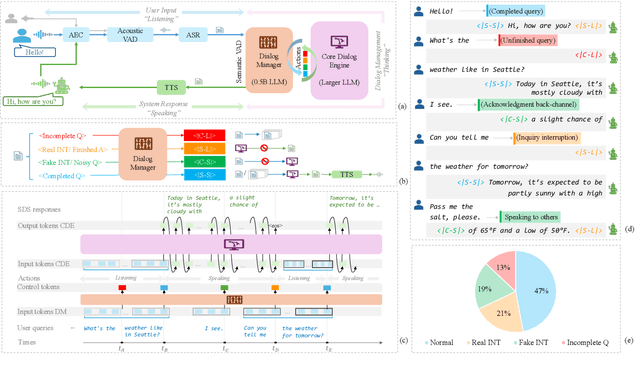
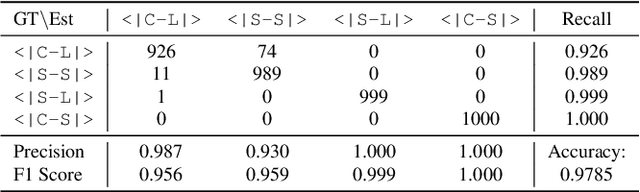
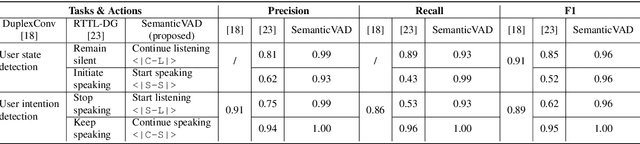

Achieving full-duplex communication in spoken dialogue systems (SDS) requires real-time coordination between listening, speaking, and thinking. This paper proposes a semantic voice activity detection (VAD) module as a dialogue manager (DM) to efficiently manage turn-taking in full-duplex SDS. Implemented as a lightweight (0.5B) LLM fine-tuned on full-duplex conversation data, the semantic VAD predicts four control tokens to regulate turn-switching and turn-keeping, distinguishing between intentional and unintentional barge-ins while detecting query completion for handling user pauses and hesitations. By processing input speech in short intervals, the semantic VAD enables real-time decision-making, while the core dialogue engine (CDE) is only activated for response generation, reducing computational overhead. This design allows independent DM optimization without retraining the CDE, balancing interaction accuracy and inference efficiency for scalable, next-generation full-duplex SDS.
Open-RGBT: Open-vocabulary RGB-T Zero-shot Semantic Segmentation in Open-world Environments
Oct 09, 2024Semantic segmentation is a critical technique for effective scene understanding. Traditional RGB-T semantic segmentation models often struggle to generalize across diverse scenarios due to their reliance on pretrained models and predefined categories. Recent advancements in Visual Language Models (VLMs) have facilitated a shift from closed-set to open-vocabulary semantic segmentation methods. However, these models face challenges in dealing with intricate scenes, primarily due to the heterogeneity between RGB and thermal modalities. To address this gap, we present Open-RGBT, a novel open-vocabulary RGB-T semantic segmentation model. Specifically, we obtain instance-level detection proposals by incorporating visual prompts to enhance category understanding. Additionally, we employ the CLIP model to assess image-text similarity, which helps correct semantic consistency and mitigates ambiguities in category identification. Empirical evaluations demonstrate that Open-RGBT achieves superior performance in diverse and challenging real-world scenarios, even in the wild, significantly advancing the field of RGB-T semantic segmentation.
Restorative Speech Enhancement: A Progressive Approach Using SE and Codec Modules
Oct 02, 2024



In challenging environments with significant noise and reverberation, traditional speech enhancement (SE) methods often lead to over-suppressed speech, creating artifacts during listening and harming downstream tasks performance. To overcome these limitations, we propose a novel approach called Restorative SE (RestSE), which combines a lightweight SE module with a generative codec module to progressively enhance and restore speech quality. The SE module initially reduces noise, while the codec module subsequently performs dereverberation and restores speech using generative capabilities. We systematically explore various quantization techniques within the codec module to optimize performance. Additionally, we introduce a weighted loss function and feature fusion that merges the SE output with the original mixture, particularly at segments where the SE output is heavily distorted. Experimental results demonstrate the effectiveness of our proposed method in enhancing speech quality under adverse conditions. Audio demos are available at: https://sophie091524.github.io/RestorativeSE/.
SSR-Speech: Towards Stable, Safe and Robust Zero-shot Text-based Speech Editing and Synthesis
Sep 11, 2024



In this paper, we introduce SSR-Speech, a neural codec autoregressive model designed for stable, safe, and robust zero-shot text-based speech editing and text-to-speech synthesis. SSR-Speech is built on a Transformer decoder and incorporates classifier-free guidance to enhance the stability of the generation process. A watermark Encodec is proposed to embed frame-level watermarks into the edited regions of the speech so that which parts were edited can be detected. In addition, the waveform reconstruction leverages the original unedited speech segments, providing superior recovery compared to the Encodec model. Our approach achieves the state-of-the-art performance in the RealEdit speech editing task and the LibriTTS text-to-speech task, surpassing previous methods. Furthermore, SSR-Speech excels in multi-span speech editing and also demonstrates remarkable robustness to background sounds. Source code and demos are released.
Neural Ambisonic Encoding For Multi-Speaker Scenarios Using A Circular Microphone Array
Sep 11, 2024Spatial audio formats like Ambisonics are playback device layout-agnostic and well-suited for applications such as teleconferencing and virtual reality. Conventional Ambisonic encoding methods often rely on spherical microphone arrays for efficient sound field capture, which limits their flexibility in practical scenarios. We propose a deep learning (DL)-based approach, leveraging a two-stage network architecture for encoding circular microphone array signals into second-order Ambisonics (SOA) in multi-speaker environments. In addition, we introduce: (i) a novel loss function based on spatial power maps to regularize inter-channel correlations of the Ambisonic signals, and (ii) a channel permutation technique to resolve the ambiguity of encoding vertical information using a horizontal circular array. Evaluation on simulated speech and noise datasets shows that our approach consistently outperforms traditional signal processing (SP) and DL-based methods, providing significantly better timbral and spatial quality and higher source localization accuracy. Binaural audio demos with visualizations are available at https://bridgoon97.github.io/NeuralAmbisonicEncoding/.
SMRU: Split-and-Merge Recurrent-based UNet for Acoustic Echo Cancellation and Noise Suppression
Jun 17, 2024The proliferation of deep neural networks has spawned the rapid development of acoustic echo cancellation and noise suppression, and plenty of prior arts have been proposed, which yield promising performance. Nevertheless, they rarely consider the deployment generality in different processing scenarios, such as edge devices, and cloud processing. To this end, this paper proposes a general model, termed SMRU, to cover different application scenarios. The novelty lies in two-fold. First, a multi-scale band split layer and band merge layer are proposed to effectively fuse local frequency bands for lower complexity modeling. Besides, by simulating the multi-resolution feature modeling characteristic of the classical UNet structure, a novel recurrent-dominated UNet is devised. It consists of multiple variable frame rate blocks, each of which involves the causal time down-/up-sampling layer with varying compression ratios and the dual-path structure for inter- and intra-band modeling. The model is configured from 50 M/s to 6.8 G/s in terms of MACs, and the experimental results show that the proposed approach yields competitive or even better performance over existing baselines, and has the full potential to adapt to more general scenarios with varying complexity requirements.