 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSANN-PSZ: Spatially Adaptive Neural Network for Head-Tracked Personal Sound Zones
Nov 01, 2024A deep learning framework for dynamically rendering personal sound zones (PSZs) with head tracking is presented, utilizing a spatially adaptive neural network (SANN) that inputs listeners' head coordinates and outputs PSZ filter coefficients. The SANN model is trained using either simulated acoustic transfer functions (ATFs) with data augmentation for robustness in uncertain environments or a mix of simulated and measured ATFs for customization under known conditions. It is found that augmenting room reflections in the training data can more effectively improve the model robustness than augmenting the system imperfections, and that adding constraints such as filter compactness to the loss function does not significantly affect the model's performance. Comparisons of the best-performing model with traditional filter design methods show that, when no measured ATFs are available, the model yields equal or higher isolation in an actual room environment with fewer filter artifacts. Furthermore, the model achieves significant data compression (100x) and computational efficiency (10x) compared to the traditional methods, making it suitable for real-time rendering of PSZs that adapt to the listeners' head movements.
Neural Ambisonic Encoding For Multi-Speaker Scenarios Using A Circular Microphone Array
Sep 11, 2024



Spatial audio formats like Ambisonics are playback device layout-agnostic and well-suited for applications such as teleconferencing and virtual reality. Conventional Ambisonic encoding methods often rely on spherical microphone arrays for efficient sound field capture, which limits their flexibility in practical scenarios. We propose a deep learning (DL)-based approach, leveraging a two-stage network architecture for encoding circular microphone array signals into second-order Ambisonics (SOA) in multi-speaker environments. In addition, we introduce: (i) a novel loss function based on spatial power maps to regularize inter-channel correlations of the Ambisonic signals, and (ii) a channel permutation technique to resolve the ambiguity of encoding vertical information using a horizontal circular array. Evaluation on simulated speech and noise datasets shows that our approach consistently outperforms traditional signal processing (SP) and DL-based methods, providing significantly better timbral and spatial quality and higher source localization accuracy. Binaural audio demos with visualizations are available at https://bridgoon97.github.io/NeuralAmbisonicEncoding/.
A Multi-loudspeaker Binaural Room Impulse Response Dataset with High-Resolution Translational and Rotational Head Coordinates in a Listening Room
Mar 18, 2024

Data report for the 3D3A Lab Binaural Room Impulse Response (BRIR) Dataset (https://doi.org/10.34770/6gc9-5787).
Isolation performance metrics for personal sound zone reproduction systems
Sep 22, 2022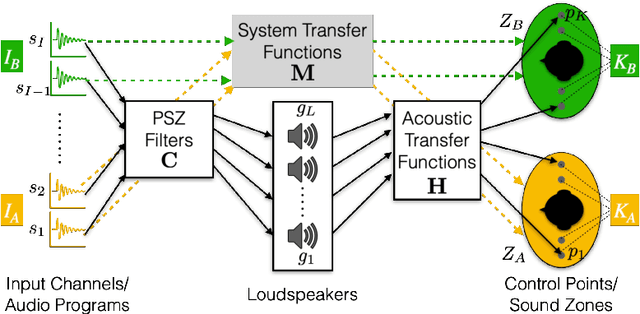
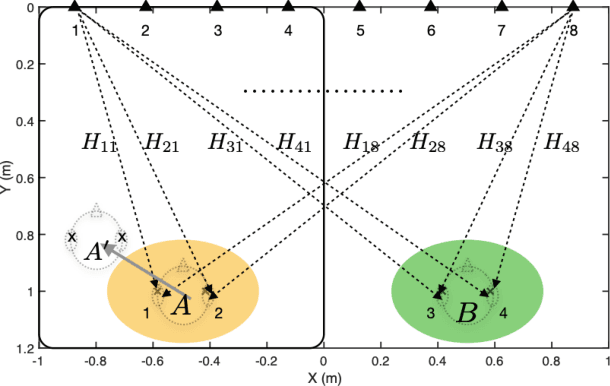
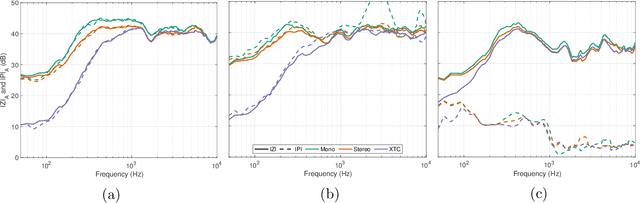
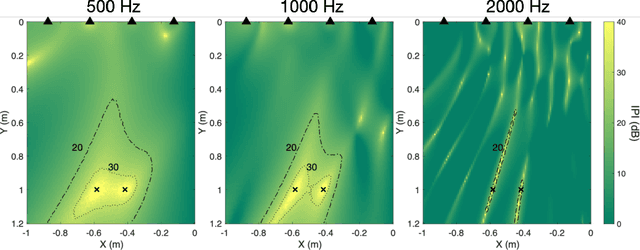
Two isolation performance metrics, Inter-Zone Isolation (IZI) and Inter-Program Isolation (IPI), are introduced for evaluating Personal Sound Zone (PSZ) systems. Compared to the commonly-used Acoustic Contrast metric, IZI and IPI are generalized for multichannel audio, and quantify the isolation of sound zones and of audio programs, respectively. The two metrics are shown to be generally non-interchangeable and suitable for different scenarios, such as generating dark zones (IZI) or minimizing audio-on-audio interference (IPI). Furthermore, two examples with free-field simulations are presented and demonstrate the applications of IZI and IPI in evaluating PSZ performance in different rendering modes and PSZ robustness.