 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Enhanced Dialogue Management for Full-Duplex Spoken Dialogue Systems
Feb 19, 2025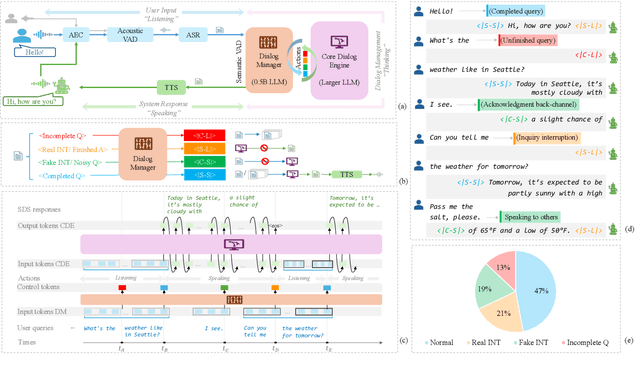
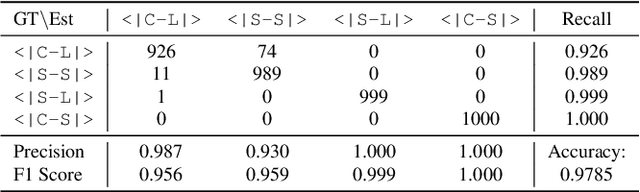
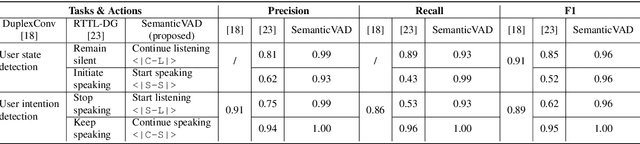

Achieving full-duplex communication in spoken dialogue systems (SDS) requires real-time coordination between listening, speaking, and thinking. This paper proposes a semantic voice activity detection (VAD) module as a dialogue manager (DM) to efficiently manage turn-taking in full-duplex SDS. Implemented as a lightweight (0.5B) LLM fine-tuned on full-duplex conversation data, the semantic VAD predicts four control tokens to regulate turn-switching and turn-keeping, distinguishing between intentional and unintentional barge-ins while detecting query completion for handling user pauses and hesitations. By processing input speech in short intervals, the semantic VAD enables real-time decision-making, while the core dialogue engine (CDE) is only activated for response generation, reducing computational overhead. This design allows independent DM optimization without retraining the CDE, balancing interaction accuracy and inference efficiency for scalable, next-generation full-duplex SDS.
Neural Ambisonic Encoding For Multi-Speaker Scenarios Using A Circular Microphone Array
Sep 11, 2024



Spatial audio formats like Ambisonics are playback device layout-agnostic and well-suited for applications such as teleconferencing and virtual reality. Conventional Ambisonic encoding methods often rely on spherical microphone arrays for efficient sound field capture, which limits their flexibility in practical scenarios. We propose a deep learning (DL)-based approach, leveraging a two-stage network architecture for encoding circular microphone array signals into second-order Ambisonics (SOA) in multi-speaker environments. In addition, we introduce: (i) a novel loss function based on spatial power maps to regularize inter-channel correlations of the Ambisonic signals, and (ii) a channel permutation technique to resolve the ambiguity of encoding vertical information using a horizontal circular array. Evaluation on simulated speech and noise datasets shows that our approach consistently outperforms traditional signal processing (SP) and DL-based methods, providing significantly better timbral and spatial quality and higher source localization accuracy. Binaural audio demos with visualizations are available at https://bridgoon97.github.io/NeuralAmbisonicEncoding/.
SpatialCodec: Neural Spatial Speech Coding
Sep 14, 2023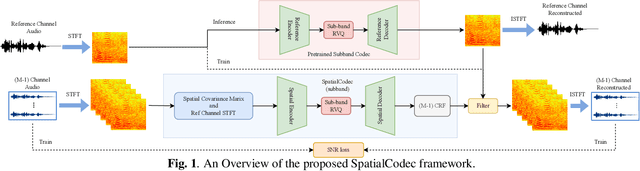
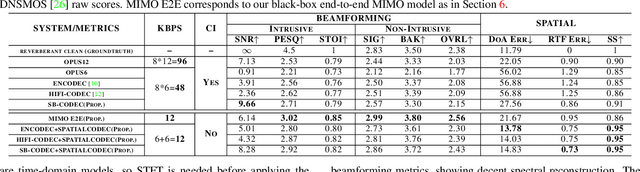

In this work, we address the challenge of encoding speech captured by a microphone array using deep learning techniques with the aim of preserving and accurately reconstructing crucial spatial cues embedded in multi-channel recordings. We propose a neural spatial audio coding framework that achieves a high compression ratio, leveraging single-channel neural sub-band codec and SpatialCodec. Our approach encompasses two phases: (i) a neural sub-band codec is designed to encode the reference channel with low bit rates, and (ii), a SpatialCodec captures relative spatial information for accurate multi-channel reconstruction at the decoder end. In addition, we also propose novel evaluation metrics to assess the spatial cue preservation: (i) spatial similarity, which calculates cosine similarity on a spatially intuitive beamspace, and (ii), beamformed audio quality. Our system shows superior spatial performance compared with high bitrate baselines and black-box neural architecture. Demos are available at https://xzwy.github.io/SpatialCodecDemo. Codes and models are available at https://github.com/XZWY/SpatialCodec.
Complex-Valued Time-Frequency Self-Attention for Speech Dereverberation
Nov 22, 2022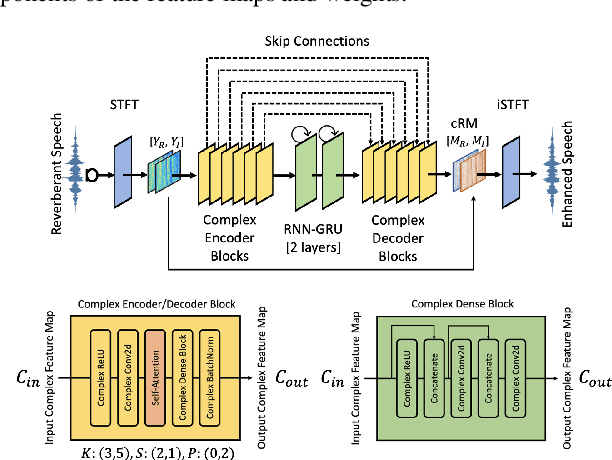
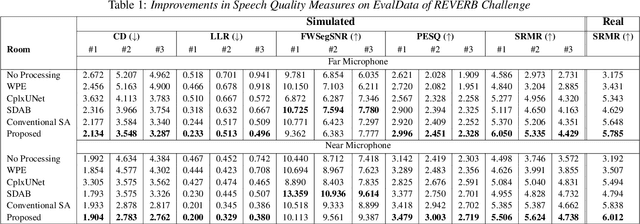
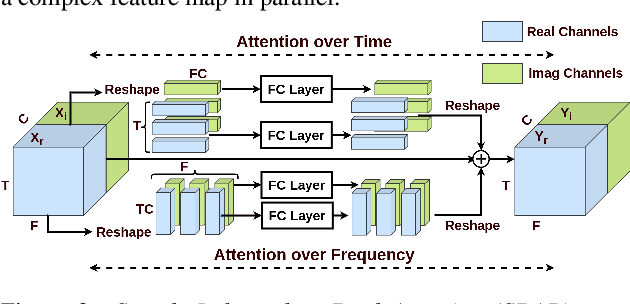
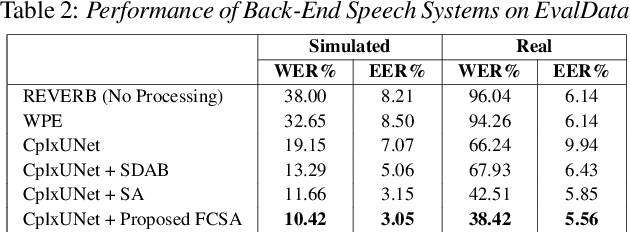
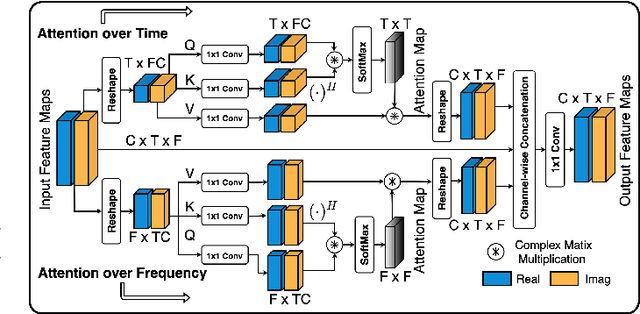
Several speech processing systems have demonstrated considerable performance improvements when deep complex neural networks (DCNN) are coupled with self-attention (SA) networks. However, the majority of DCNN-based studies on speech dereverberation that employ self-attention do not explicitly account for the inter-dependencies between real and imaginary features when computing attention. In this study, we propose a complex-valued T-F attention (TFA) module that models spectral and temporal dependencies by computing two-dimensional attention maps across time and frequency dimensions. We validate the effectiveness of our proposed complex-valued TFA module with the deep complex convolutional recurrent network (DCCRN) using the REVERB challenge corpus. Experimental findings indicate that integrating our complex-TFA module with DCCRN improves overall speech quality and performance of back-end speech applications, such as automatic speech recognition, compared to earlier approaches for self-attention.
SkipConvGAN: Monaural Speech Dereverberation using Generative Adversarial Networks via Complex Time-Frequency Masking
Nov 22, 2022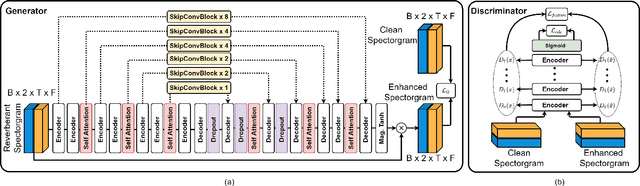
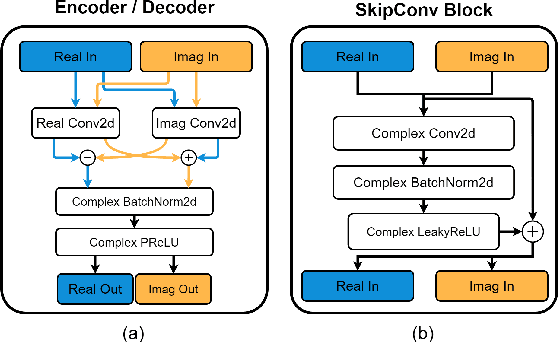
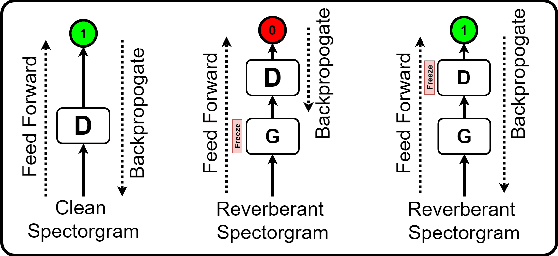
With the advancements in deep learning approaches, the performance of speech enhancing systems in the presence of background noise have shown significant improvements. However, improving the system's robustness against reverberation is still a work in progress, as reverberation tends to cause loss of formant structure due to smearing effects in time and frequency. A wide range of deep learning-based systems either enhance the magnitude response and reuse the distorted phase or enhance complex spectrogram using a complex time-frequency mask. Though these approaches have demonstrated satisfactory performance, they do not directly address the lost formant structure caused by reverberation. We believe that retrieving the formant structure can help improve the efficiency of existing systems. In this study, we propose SkipConvGAN - an extension of our prior work SkipConvNet. The proposed system's generator network tries to estimate an efficient complex time-frequency mask, while the discriminator network aids in driving the generator to restore the lost formant structure. We evaluate the performance of our proposed system on simulated and real recordings of reverberant speech from the single-channel task of the REVERB challenge corpus. The proposed system shows a consistent improvement across multiple room configurations over other deep learning-based generative adversarial frameworks.
Deep Neural Mel-Subband Beamformer for In-car Speech Separation
Nov 22, 2022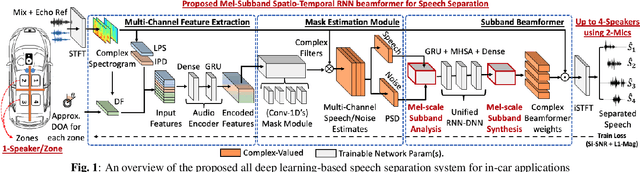
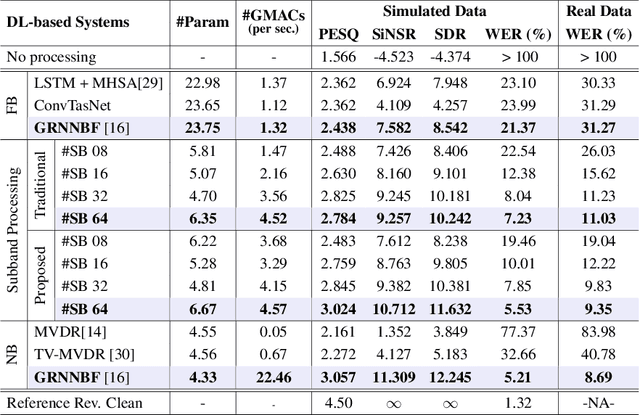
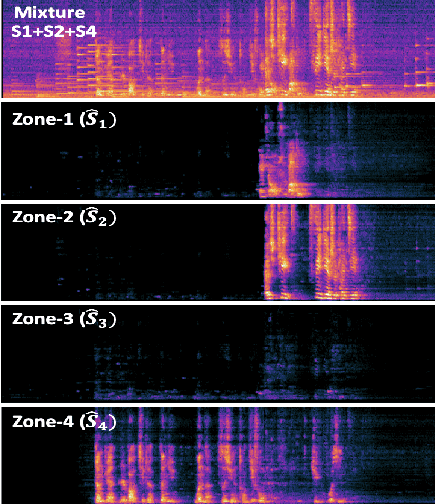
While current deep learning (DL)-based beamforming techniques have been proved effective in speech separation, they are often designed to process narrow-band (NB) frequencies independently which results in higher computational costs and inference times, making them unsuitable for real-world use. In this paper, we propose DL-based mel-subband spatio-temporal beamformer to perform speech separation in a car environment with reduced computation cost and inference time. As opposed to conventional subband (SB) approaches, our framework uses a mel-scale based subband selection strategy which ensures a fine-grained processing for lower frequencies where most speech formant structure is present, and coarse-grained processing for higher frequencies. In a recursive way, robust frame-level beamforming weights are determined for each speaker location/zone in a car from the estimated subband speech and noise covariance matrices. Furthermore, proposed framework also estimates and suppresses any echoes from the loudspeaker(s) by using the echo reference signals. We compare the performance of our proposed framework to several NB, SB, and full-band (FB) processing techniques in terms of speech quality and recognition metrics. Based on experimental evaluations on simulated and real-world recordings, we find that our proposed framework achieves better separation performance over all SB and FB approaches and achieves performance closer to NB processing techniques while requiring lower computing cost.
Joint AEC AND Beamforming with Double-Talk Detection using RNN-Transformer
Nov 09, 2021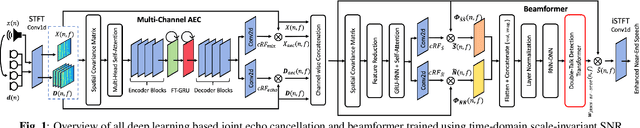
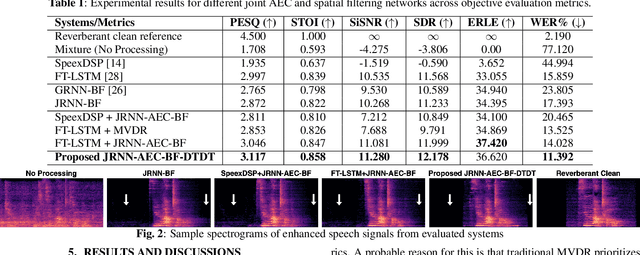
Acoustic echo cancellation (AEC) is a technique used in full-duplex communication systems to eliminate acoustic feedback of far-end speech. However, their performance degrades in naturalistic environments due to nonlinear distortions introduced by the speaker, as well as background noise, reverberation, and double-talk scenarios. To address nonlinear distortions and co-existing background noise, several deep neural network (DNN)-based joint AEC and denoising systems were developed. These systems are based on either purely "black-box" neural networks or "hybrid" systems that combine traditional AEC algorithms with neural networks. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. Furthermore, we propose a double-talk detection transformer (DTDT) module based on the multi-head attention transformer structure that computes attention over time by leveraging frame-wise double-talk predictions. Experiments show that our proposed method outperforms other approaches in terms of improving speech quality and speech recognition rate of an ASR system.
Analyzing Large Receptive Field Convolutional Networks for Distant Speech Recognition
Oct 15, 2019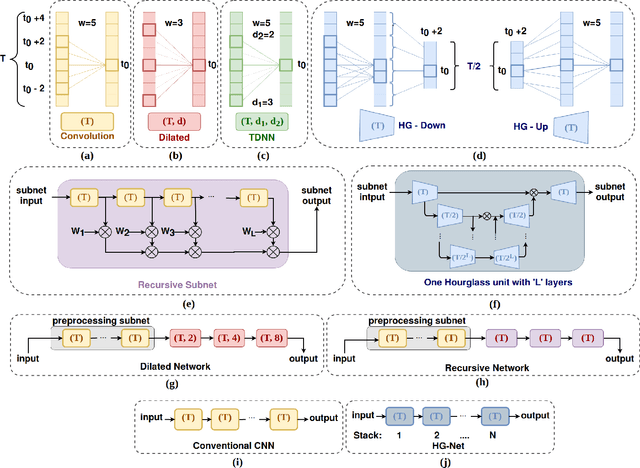
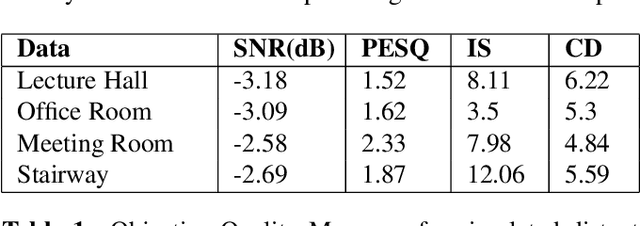
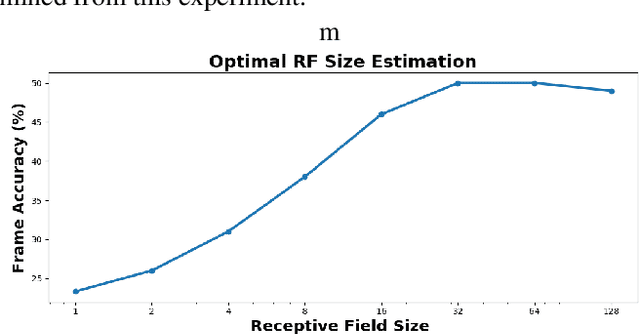
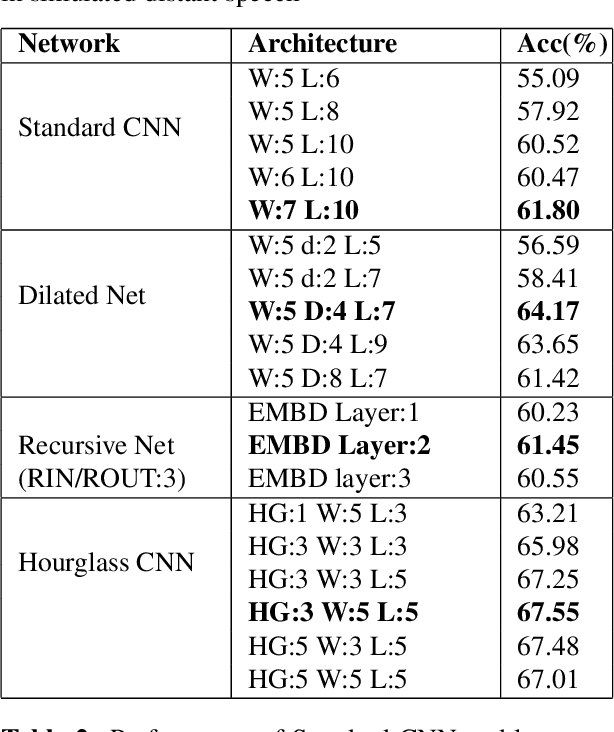
Despite significant efforts over the last few years to build a robust automatic speech recognition (ASR) system for different acoustic settings, the performance of the current state-of-the-art technologies significantly degrades in noisy reverberant environments. Convolutional Neural Networks (CNNs) have been successfully used to achieve substantial improvements in many speech processing applications including distant speech recognition (DSR). However, standard CNN architectures were not efficient in capturing long-term speech dynamics, which are essential in the design of a robust DSR system. In the present study, we address this issue by investigating variants of large receptive field CNNs (LRF-CNNs) which include deeply recursive networks, dilated convolutional neural networks, and stacked hourglass networks. To compare the efficacy of the aforementioned architectures with the standard CNN for Wall Street Journal (WSJ) corpus, we use a hybrid DNN-HMM based speech recognition system. We extend the study to evaluate the system performances for distant speech simulated using realistic room impulse responses (RIRs). Our experiments show that with fixed number of parameters across all architectures, the large receptive field networks show consistent improvements over the standard CNNs for distant speech. Amongst the explored LRF-CNNs, stacked hourglass network has shown improvements with a 8.9% relative reduction in word error rate (WER) and 10.7% relative improvement in frame accuracy compared to the standard CNNs for distant simulated speech signals.