 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkipConvGAN: Monaural Speech Dereverberation using Generative Adversarial Networks via Complex Time-Frequency Masking
Paper and Code
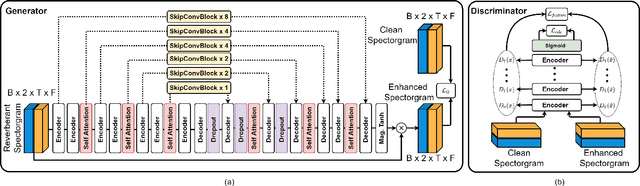
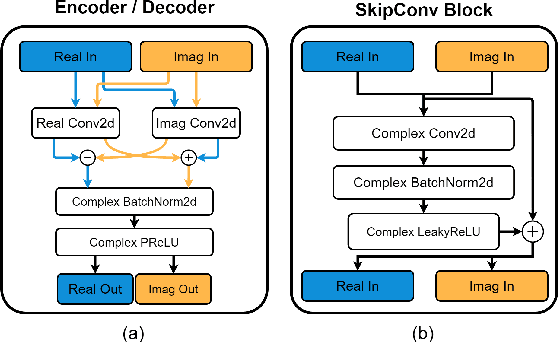
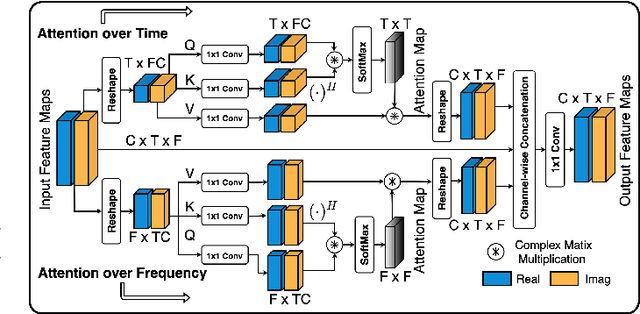
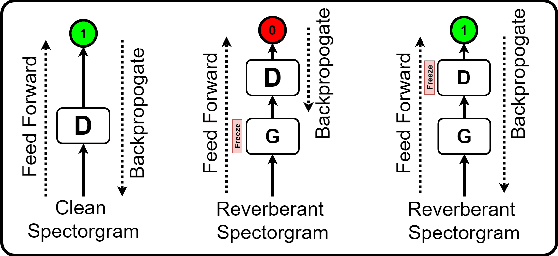
With the advancements in deep learning approaches, the performance of speech enhancing systems in the presence of background noise have shown significant improvements. However, improving the system's robustness against reverberation is still a work in progress, as reverberation tends to cause loss of formant structure due to smearing effects in time and frequency. A wide range of deep learning-based systems either enhance the magnitude response and reuse the distorted phase or enhance complex spectrogram using a complex time-frequency mask. Though these approaches have demonstrated satisfactory performance, they do not directly address the lost formant structure caused by reverberation. We believe that retrieving the formant structure can help improve the efficiency of existing systems. In this study, we propose SkipConvGAN - an extension of our prior work SkipConvNet. The proposed system's generator network tries to estimate an efficient complex time-frequency mask, while the discriminator network aids in driving the generator to restore the lost formant structure. We evaluate the performance of our proposed system on simulated and real recordings of reverberant speech from the single-channel task of the REVERB challenge corpus. The proposed system shows a consistent improvement across multiple room configurations over other deep learning-based generative adversarial frameworks.