 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Combined Generative and Predictive Modeling for Speech Super-resolution
Jan 25, 2024
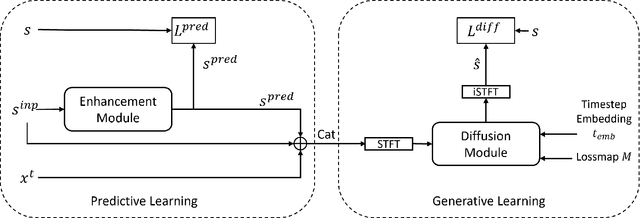
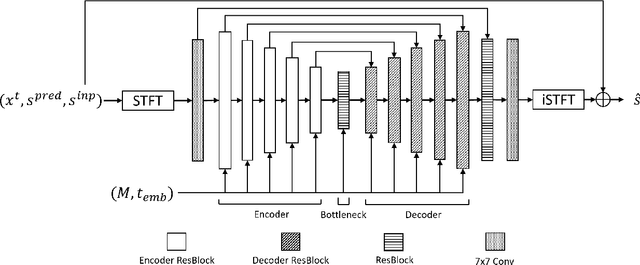
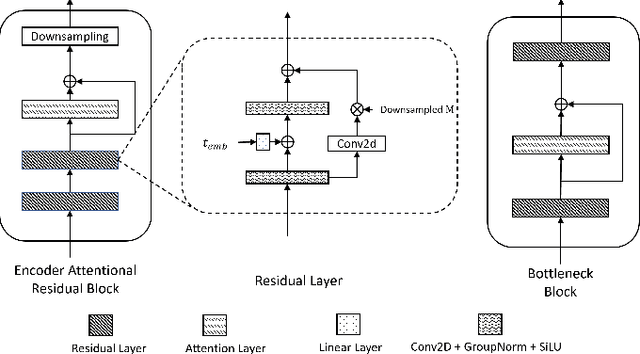
Speech super-resolution (SR) is the task that restores high-resolution speech from low-resolution input. Existing models employ simulated data and constrained experimental settings, which limit generalization to real-world SR. Predictive models are known to perform well in fixed experimental settings, but can introduce artifacts in adverse conditions. On the other hand, generative models learn the distribution of target data and have a better capacity to perform well on unseen conditions. In this study, we propose a novel two-stage approach that combines the strengths of predictive and generative models. Specifically, we employ a diffusion-based model that is conditioned on the output of a predictive model. Our experiments demonstrate that the model significantly outperforms single-stage counterparts and existing strong baselines on benchmark SR datasets. Furthermore, we introduce a repainting technique during the inference of the diffusion process, enabling the proposed model to regenerate high-frequency components even in mismatched conditions. An additional contribution is the collection of and evaluation on real SR recordings, using the same microphone at different native sampling rates. We make this dataset freely accessible, to accelerate progress towards real-world speech super-resolution.
Leveraging Laryngograph Data for Robust Voicing Detection in Speech
Dec 05, 2023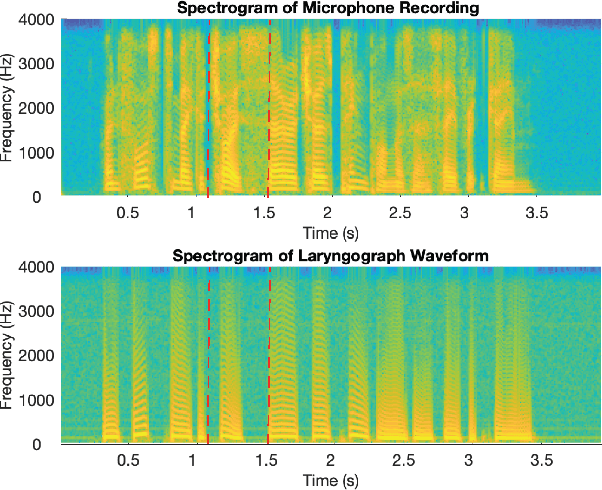
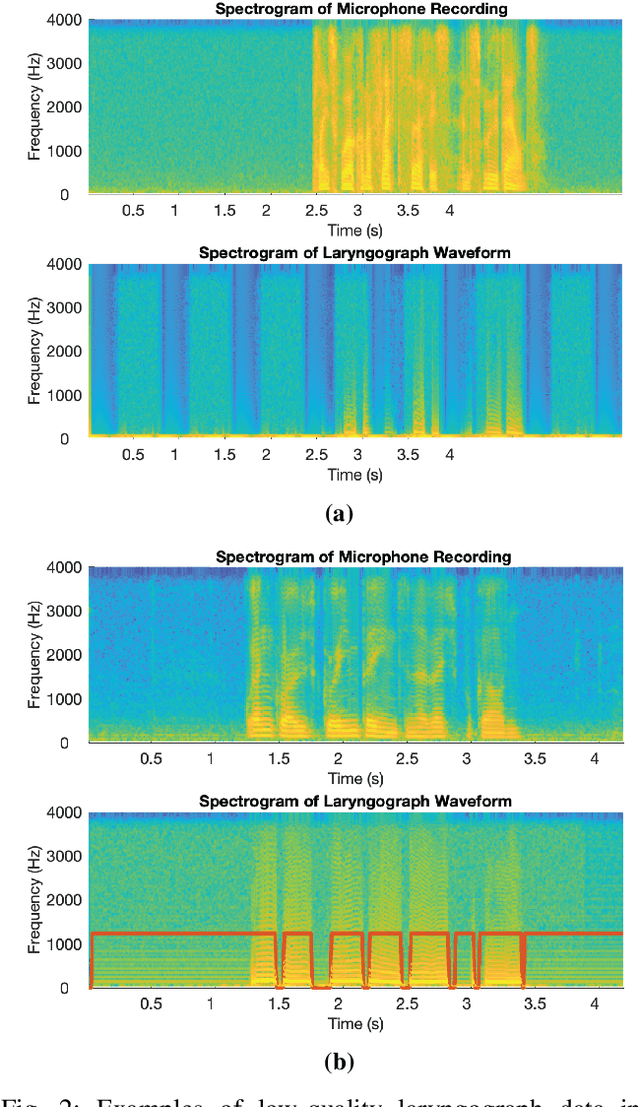
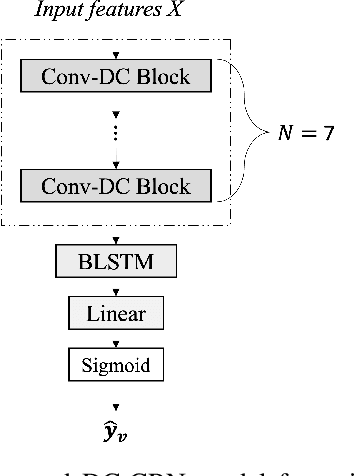
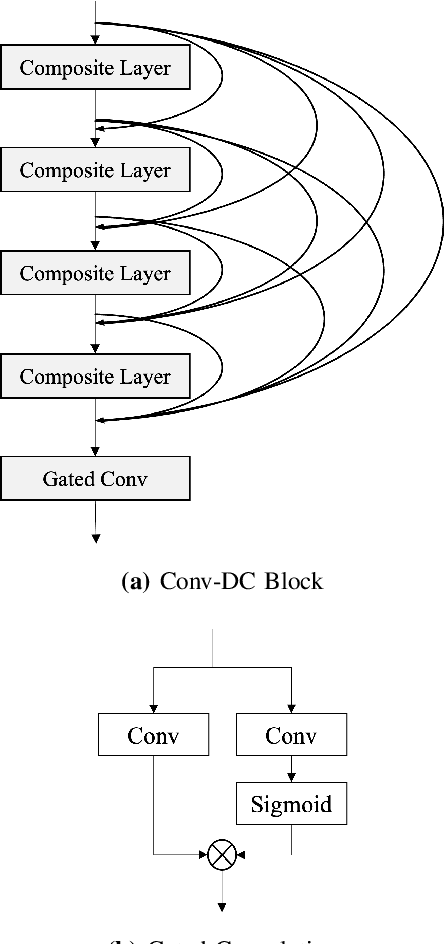
Accurately detecting voiced intervals in speech signals is a critical step in pitch tracking and has numerous applications. While conventional signal processing methods and deep learning algorithms have been proposed for this task, their need to fine-tune threshold parameters for different datasets and limited generalization restrict their utility in real-world applications. To address these challenges, this study proposes a supervised voicing detection model that leverages recorded laryngograph data. The model is based on a densely-connected convolutional recurrent neural network (DC-CRN), and trained on data with reference voicing decisions extracted from laryngograph data sets. Pretraining is also investigated to improve the generalization ability of the model. The proposed model produces robust voicing detection results, outperforming other strong baseline methods, and generalizes well to unseen datasets. The source code of the proposed model with pretraining is provided along with the list of used laryngograph datasets to facilitate further research in this area.
uSee: Unified Speech Enhancement and Editing with Conditional Diffusion Models
Oct 02, 2023Speech enhancement aims to improve the quality of speech signals in terms of quality and intelligibility, and speech editing refers to the process of editing the speech according to specific user needs. In this paper, we propose a Unified Speech Enhancement and Editing (uSee) model with conditional diffusion models to handle various tasks at the same time in a generative manner. Specifically, by providing multiple types of conditions including self-supervised learning embeddings and proper text prompts to the score-based diffusion model, we can enable controllable generation of the unified speech enhancement and editing model to perform corresponding actions on the source speech. Our experiments show that our proposed uSee model can achieve superior performance in both speech denoising and dereverberation compared to other related generative speech enhancement models, and can perform speech editing given desired environmental sound text description, signal-to-noise ratios (SNR), and room impulse responses (RIR). Demos of the generated speech are available at https://muqiaoy.github.io/usee.
Diffusion Conditional Expectation Model for Efficient and Robust Target Speech Extraction
Sep 25, 2023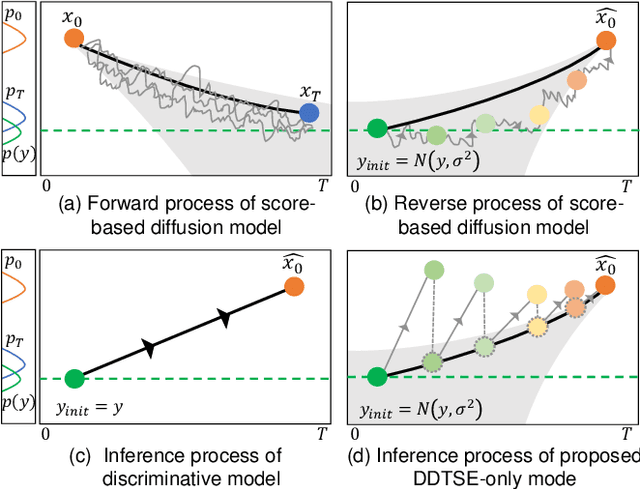
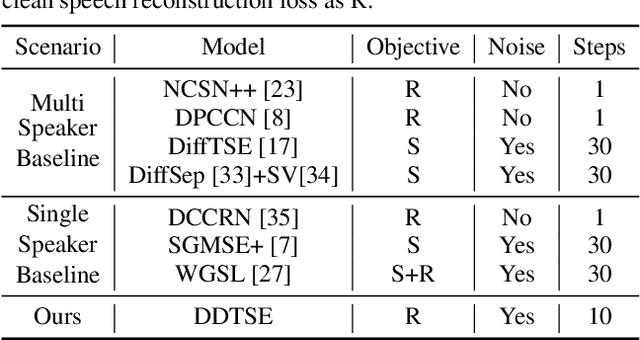
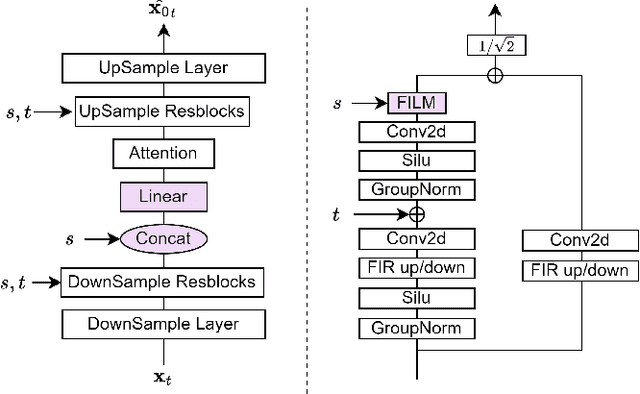
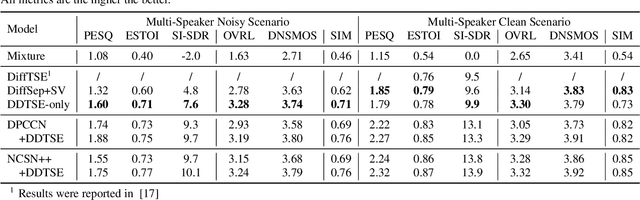
Target Speech Extraction (TSE) is a crucial task in speech processing that focuses on isolating the clean speech of a specific speaker from complex mixtures. While discriminative methods are commonly used for TSE, they can introduce distortion in terms of speech perception quality. On the other hand, generative approaches, particularly diffusion-based methods, can enhance speech quality perceptually but suffer from slower inference speed. We propose an efficient generative approach named Diffusion Conditional Expectation Model (DCEM) for TSE. It can handle multi- and single-speaker scenarios in both noisy and clean conditions. Additionally, we introduce Regenerate-DCEM (R-DCEM) that can regenerate and optimize speech quality based on pre-processed speech from a discriminative model. Our method outperforms conventional methods in terms of both intrusive and non-intrusive metrics and demonstrates notable strengths in inference efficiency and robustness to unseen tasks. Audio examples are available online (https://vivian556123.github.io/dcem).
Unifying Robustness and Fidelity: A Comprehensive Study of Pretrained Generative Methods for Speech Enhancement in Adverse Conditions
Sep 16, 2023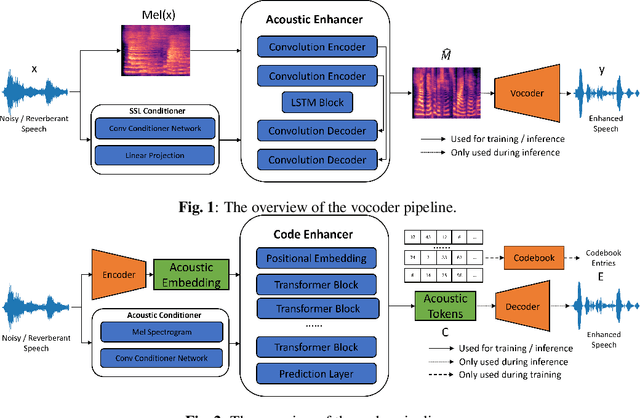

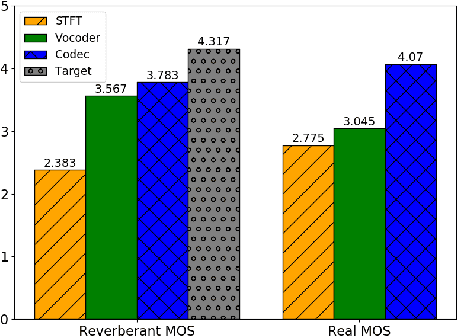
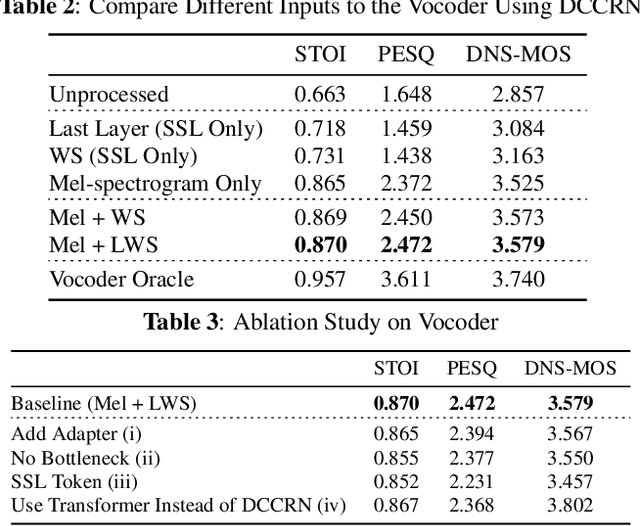
Enhancing speech signal quality in adverse acoustic environments is a persistent challenge in speech processing. Existing deep learning based enhancement methods often struggle to effectively remove background noise and reverberation in real-world scenarios, hampering listening experiences. To address these challenges, we propose a novel approach that uses pre-trained generative methods to resynthesize clean, anechoic speech from degraded inputs. This study leverages pre-trained vocoder or codec models to synthesize high-quality speech while enhancing robustness in challenging scenarios. Generative methods effectively handle information loss in speech signals, resulting in regenerated speech that has improved fidelity and reduced artifacts. By harnessing the capabilities of pre-trained models, we achieve faithful reproduction of the original speech in adverse conditions. Experimental evaluations on both simulated datasets and realistic samples demonstrate the effectiveness and robustness of our proposed methods. Especially by leveraging codec, we achieve superior subjective scores for both simulated and realistic recordings. The generated speech exhibits enhanced audio quality, reduced background noise, and reverberation. Our findings highlight the potential of pre-trained generative techniques in speech processing, particularly in scenarios where traditional methods falter. Demos are available at https://whmrtm.github.io/SoundResynthesis.
SpatialCodec: Neural Spatial Speech Coding
Sep 14, 2023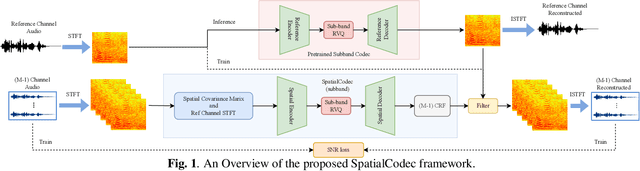
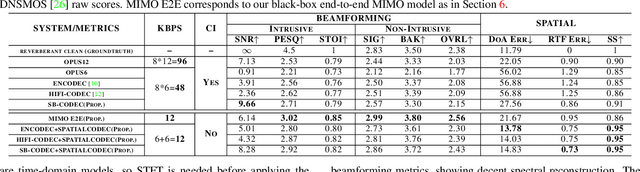

In this work, we address the challenge of encoding speech captured by a microphone array using deep learning techniques with the aim of preserving and accurately reconstructing crucial spatial cues embedded in multi-channel recordings. We propose a neural spatial audio coding framework that achieves a high compression ratio, leveraging single-channel neural sub-band codec and SpatialCodec. Our approach encompasses two phases: (i) a neural sub-band codec is designed to encode the reference channel with low bit rates, and (ii), a SpatialCodec captures relative spatial information for accurate multi-channel reconstruction at the decoder end. In addition, we also propose novel evaluation metrics to assess the spatial cue preservation: (i) spatial similarity, which calculates cosine similarity on a spatially intuitive beamspace, and (ii), beamformed audio quality. Our system shows superior spatial performance compared with high bitrate baselines and black-box neural architecture. Demos are available at https://xzwy.github.io/SpatialCodecDemo. Codes and models are available at https://github.com/XZWY/SpatialCodec.
Experimental Realization of Convolution Processing in Photonic Synthetic Frequency Dimensions
May 05, 2023Convolution is an essential operation in signal and image processing and consumes most of the computing power in convolutional neural networks. Photonic convolution has the promise of addressing computational bottlenecks and outperforming electronic implementations. Performing photonic convolution in the synthetic frequency dimension, which harnesses the dynamics of light in the spectral degrees of freedom for photons, can lead to highly compact devices. Here we experimentally realize convolution operations in the synthetic frequency dimension. Using a modulated ring resonator, we synthesize arbitrary convolution kernels using a pre-determined modulation waveform with high accuracy. We demonstrate the convolution computation between input frequency combs and synthesized kernels. We also introduce the idea of an additive offset to broaden the kinds of kernels that can be implemented experimentally when the modulation strength is limited. Our work demonstrate the use of synthetic frequency dimension to efficiently encode data and implement computation tasks, leading to a compact and scalable photonic computation architecture.
Single-shot ToF sensing with sub-mm precision using conventional CMOS sensors
Dec 02, 2022We present a novel single-shot interferometric ToF camera targeted for precise 3D measurements of dynamic objects. The camera concept is based on Synthetic Wavelength Interferometry, a technique that allows retrieval of depth maps of objects with optically rough surfaces at submillimeter depth precision. In contrast to conventional ToF cameras, our device uses only off-the-shelf CCD/CMOS detectors and works at their native chip resolution (as of today, theoretically up to 20 Mp and beyond). Moreover, we can obtain a full 3D model of the object in single-shot, meaning that no temporal sequence of exposures or temporal illumination modulation (such as amplitude or frequency modulation) is necessary, which makes our camera robust against object motion. In this paper, we introduce the novel camera concept and show first measurements that demonstrate the capabilities of our system. We present 3D measurements of small (cm-sized) objects with > 2 Mp point cloud resolution (the resolution of our used detector) and up to sub-mm depth precision. We also report a "single-shot 3D video" acquisition and a first single-shot "Non-Line-of-Sight" measurement. Our technique has great potential for high-precision applications with dynamic object movement, e.g., in AR/VR, industrial inspection, medical imaging, and imaging through scattering media like fog or human tissue.
Improving Noise Robustness of Contrastive Speech Representation Learning with Speech Reconstruction
Oct 28, 2021



Noise robustness is essential for deploying automatic speech recognition (ASR) systems in real-world environments. One way to reduce the effect of noise interference is to employ a preprocessing module that conducts speech enhancement, and then feed the enhanced speech to an ASR backend. In this work, instead of suppressing background noise with a conventional cascaded pipeline, we employ a noise-robust representation learned by a refined self-supervised framework for noisy speech recognition. We propose to combine a reconstruction module with contrastive learning and perform multi-task continual pre-training on noisy data. The reconstruction module is used for auxiliary learning to improve the noise robustness of the learned representation and thus is not required during inference. Experiments demonstrate the effectiveness of our proposed method. Our model substantially reduces the word error rate (WER) for the synthesized noisy LibriSpeech test sets, and yields around 4.1/7.5% WER reduction on noisy clean/other test sets compared to data augmentation. For the real-world noisy speech from the CHiME-4 challenge (1-channel track), we have obtained the state of the art ASR performance without any denoising front-end. Moreover, we achieve comparable performance to the best supervised approach reported with only 16% of labeled data.