 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Conditional Expectation Model for Efficient and Robust Target Speech Extraction
Paper and Code
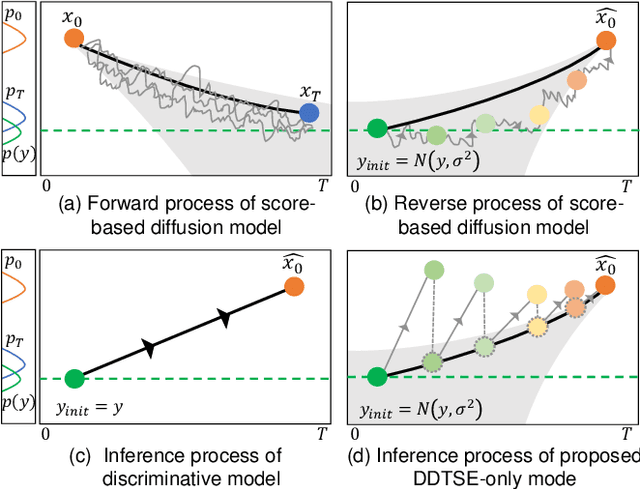
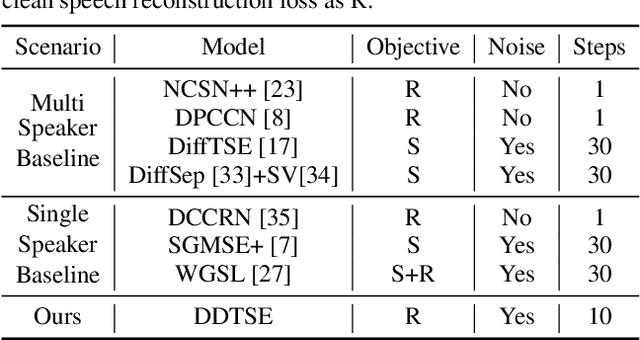
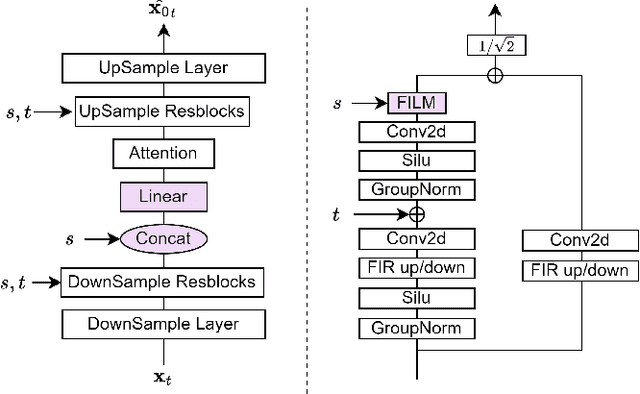
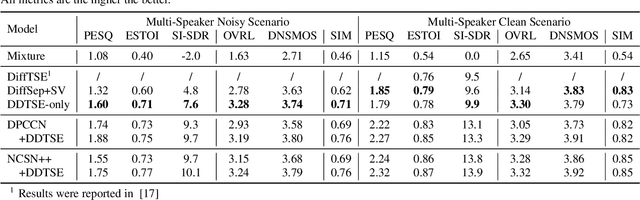
Target Speech Extraction (TSE) is a crucial task in speech processing that focuses on isolating the clean speech of a specific speaker from complex mixtures. While discriminative methods are commonly used for TSE, they can introduce distortion in terms of speech perception quality. On the other hand, generative approaches, particularly diffusion-based methods, can enhance speech quality perceptually but suffer from slower inference speed. We propose an efficient generative approach named Diffusion Conditional Expectation Model (DCEM) for TSE. It can handle multi- and single-speaker scenarios in both noisy and clean conditions. Additionally, we introduce Regenerate-DCEM (R-DCEM) that can regenerate and optimize speech quality based on pre-processed speech from a discriminative model. Our method outperforms conventional methods in terms of both intrusive and non-intrusive metrics and demonstrates notable strengths in inference efficiency and robustness to unseen tasks. Audio examples are available online (https://vivian556123.github.io/dcem).