 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Surface-based Multimodal Framework for Multitask Analysis in Alzheimer's Disease
Jun 14, 2026Alzheimer's Disease (AD) is a progressive neurodegenerative disorder, and longitudinal analysis is critical for early detection and effective intervention. Developing models capable of multimodal and multitask analysis enables a more comprehensive understanding of AD progression. However, multimodal learning remains challenged by cross-modal misalignment, non-Euclidean surface representations of cortical data, and limited data availability in small-sample clinical settings. In this work, we propose an augmented spherical data-driven multimodal framework for multitask AD analysis. A spherical diffusion model is first trained to generate paired cortical thickness and Tau PET Standardized Uptake Value Ratio (SUVR) data, enabling structurally consistent multimodal augmentation on cortical surfaces while preserving anatomical correspondence. The augmented data are subsequently used to train a contrastive learning model that learns aligned and fused cross-modal representations. This design strengthens multimodal integration and encourages more balanced representation learning. The learned imaging features are further integrated with tabular cognitive assessments and demographic variables, and processed using an in-context learning model to perform both classification and regression tasks without task-specific fine-tuning. Experiments on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset ($n = 802$) demonstrate consistent performance improvements across five diagnostic and longitudinal tasks, outperforming six baseline models.
LaMP: Learning Vision-Language-Action Policies with 3D Scene Flow as Latent Motion Prior
Mar 26, 2026We introduce \textbf{LaMP}, a dual-expert Vision-Language-Action framework that embeds dense 3D scene flow as a latent motion prior for robotic manipulation. Existing VLA models regress actions directly from 2D semantic visual features, forcing them to learn complex 3D physical interactions implicitly. This implicit learning strategy degrades under unfamiliar spatial dynamics. LaMP addresses this limitation by aligning a flow-matching \emph{Motion Expert} with a policy-predicting \emph{Action Expert} through gated cross-attention. Specifically, the Motion Expert generates a one-step partially denoised 3D scene flow, and its hidden states condition the Action Expert without full multi-step reconstruction. We evaluate LaMP on the LIBERO, LIBERO-Plus, and SimplerEnv-WidowX simulation benchmarks as well as real-world experiments. LaMP consistently outperforms evaluated VLA baselines across LIBERO, LIBERO-Plus, and SimplerEnv-WidowX benchmarks, achieving the highest reported average success rates under the same training budgets. On LIBERO-Plus OOD perturbations, LaMP shows improved robustness with an average 9.7% gain over the strongest prior baseline. Our project page is available at https://summerwxk.github.io/lamp-project-page/.
Synergizing Understanding and Generation with Interleaved Analyzing-Drafting Thinking
Feb 24, 2026Unified Vision-Language Models (UVLMs) aim to advance multimodal learning by supporting both understanding and generation within a single framework. However, existing approaches largely focus on architectural unification while overlooking the need for explicit interaction between the two capabilities during task solving. As a result, current models treat understanding and generation as parallel skills rather than synergistic processes. To achieve real synergy, we introduce the interleaved Analyzing-Drafting problem-solving loop (AD-Loop), a new think paradigm that dynamically alternates between analytic and drafting operations. By interleaving textual thoughts with visual thoughts, AD-Loop enables models to iteratively refine both comprehension and outputs, fostering genuine synergy. To train this mechanism, we design a two-stage strategy: supervised learning on interleaved thought data to initialize alternation, followed by reinforcement learning to promote adaptive and autonomous control. Extensive experiments demonstrate that AD-Loop consistently improves performance across standard benchmarks for both understanding and generation, with strong transferability to various UVLMs architectures. Visual analyses further validate the effectiveness of implicit visual thoughts. These results highlight AD-Loop as a principled and broadly applicable strategy for synergizing comprehension and creation. The project page is at https://sqwu.top/AD-Loop.
MRUCT: Mixed Reality Assistance for Acupuncture Guided by Ultrasonic Computed Tomography
Feb 12, 2025Chinese acupuncture practitioners primarily depend on muscle memory and tactile feedback to insert needles and accurately target acupuncture points, as the current workflow lacks imaging modalities and visual aids. Consequently, new practitioners often learn through trial and error, requiring years of experience to become proficient and earn the trust of patients. Medical students face similar challenges in mastering this skill. To address these challenges, we developed an innovative system, MRUCT, that integrates ultrasonic computed tomography (UCT) with mixed reality (MR) technology to visualize acupuncture points in real-time. This system offers offline image registration and real-time guidance during needle insertion, enabling them to accurately position needles based on anatomical structures such as bones, muscles, and auto-generated reference points, with the potential for clinical implementation. In this paper, we outline the non-rigid registration methods used to reconstruct anatomical structures from UCT data, as well as the key design considerations of the MR system. We evaluated two different 3D user interface (3DUI) designs and compared the performance of our system to traditional workflows for both new practitioners and medical students. The results highlight the potential of MR to enhance therapeutic medical practices and demonstrate the effectiveness of the system we developed.
DipMe: Haptic Recognition of Granular Media for Tangible Interactive Applications
Nov 13, 2024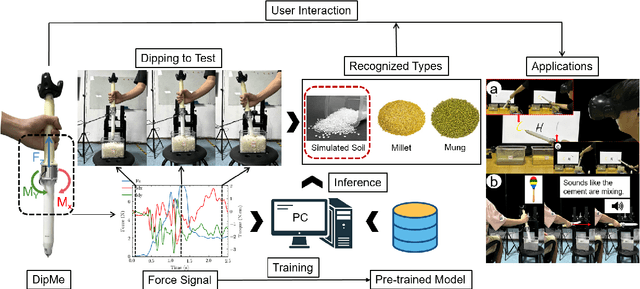


While tangible user interface has shown its power in naturally interacting with rigid or soft objects, users cannot conveniently use different types of granular materials as the interaction media. We introduce DipMe as a smart device to recognize the types of granular media in real time, which can be used to connect the granular materials in the physical world with various virtual content. Other than vision-based solutions, we propose a dip operation of our device and exploit the haptic signals to recognize different types of granular materials. With modern machine learning tools, we find the haptic signals from different granular media are distinguishable by DipMe. With the online granular object recognition, we build several tangible interactive applications, demonstrating the effects of DipMe in perceiving granular materials and its potential in developing a tangible user interface with granular objects as the new media.
Diffusion Conditional Expectation Model for Efficient and Robust Target Speech Extraction
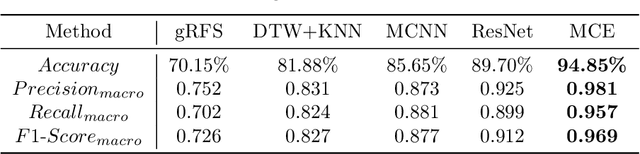
Sep 25, 2023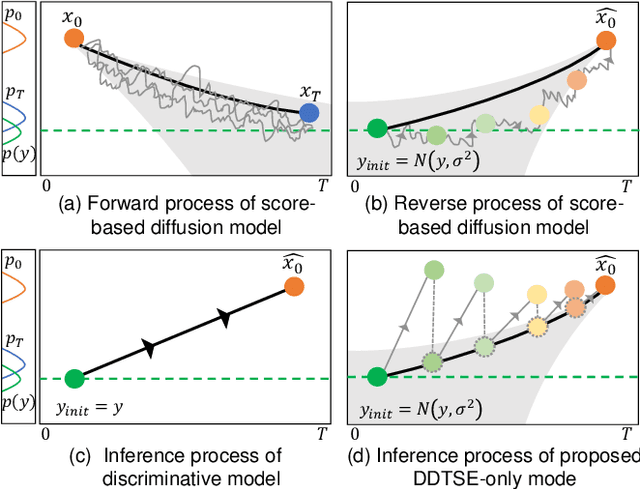
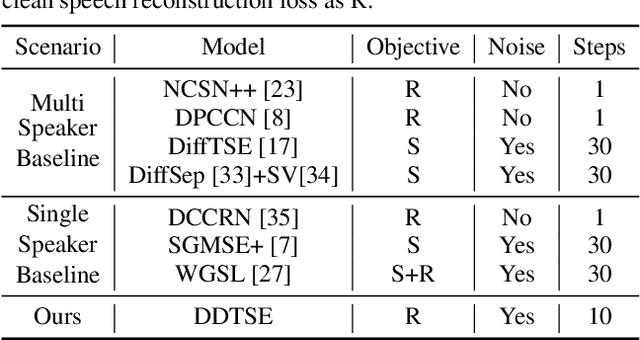
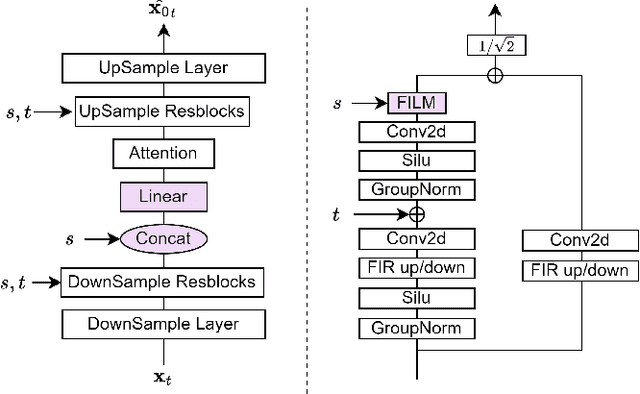
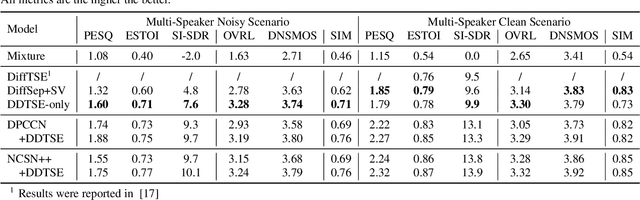
Target Speech Extraction (TSE) is a crucial task in speech processing that focuses on isolating the clean speech of a specific speaker from complex mixtures. While discriminative methods are commonly used for TSE, they can introduce distortion in terms of speech perception quality. On the other hand, generative approaches, particularly diffusion-based methods, can enhance speech quality perceptually but suffer from slower inference speed. We propose an efficient generative approach named Diffusion Conditional Expectation Model (DCEM) for TSE. It can handle multi- and single-speaker scenarios in both noisy and clean conditions. Additionally, we introduce Regenerate-DCEM (R-DCEM) that can regenerate and optimize speech quality based on pre-processed speech from a discriminative model. Our method outperforms conventional methods in terms of both intrusive and non-intrusive metrics and demonstrates notable strengths in inference efficiency and robustness to unseen tasks. Audio examples are available online (https://vivian556123.github.io/dcem).