 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Improving Continual Learning in Spoken Language Understanding
Feb 16, 2024Continual learning has emerged as an increasingly important challenge across various tasks, including Spoken Language Understanding (SLU). In SLU, its objective is to effectively handle the emergence of new concepts and evolving environments. The evaluation of continual learning algorithms typically involves assessing the model's stability, plasticity, and generalizability as fundamental aspects of standards. However, existing continual learning metrics primarily focus on only one or two of the properties. They neglect the overall performance across all tasks, and do not adequately disentangle the plasticity versus stability/generalizability trade-offs within the model. In this work, we propose an evaluation methodology that provides a unified evaluation on stability, plasticity, and generalizability in continual learning. By employing the proposed metric, we demonstrate how introducing various knowledge distillations can improve different aspects of these three properties of the SLU model. We further show that our proposed metric is more sensitive in capturing the impact of task ordering in continual learning, making it better suited for practical use-case scenarios.
Continual Contrastive Spoken Language Understanding
Oct 04, 2023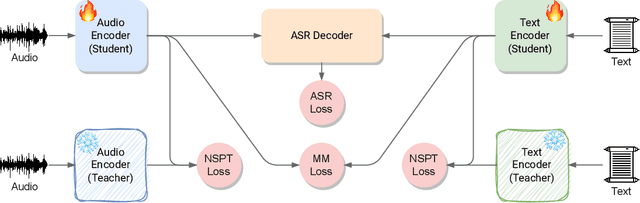


Recently, neural networks have shown impressive progress across diverse fields, with speech processing being no exception. However, recent breakthroughs in this area require extensive offline training using large datasets and tremendous computing resources. Unfortunately, these models struggle to retain their previously acquired knowledge when learning new tasks continually, and retraining from scratch is almost always impractical. In this paper, we investigate the problem of learning sequence-to-sequence models for spoken language understanding in a class-incremental learning (CIL) setting and we propose COCONUT, a CIL method that relies on the combination of experience replay and contrastive learning. Through a modified version of the standard supervised contrastive loss applied only to the rehearsal samples, COCONUT preserves the learned representations by pulling closer samples from the same class and pushing away the others. Moreover, we leverage a multimodal contrastive loss that helps the model learn more discriminative representations of the new data by aligning audio and text features. We also investigate different contrastive designs to combine the strengths of the contrastive loss with teacher-student architectures used for distillation. Experiments on two established SLU datasets reveal the effectiveness of our proposed approach and significant improvements over the baselines. We also show that COCONUT can be combined with methods that operate on the decoder side of the model, resulting in further metrics improvements.
uSee: Unified Speech Enhancement and Editing with Conditional Diffusion Models
Oct 02, 2023Speech enhancement aims to improve the quality of speech signals in terms of quality and intelligibility, and speech editing refers to the process of editing the speech according to specific user needs. In this paper, we propose a Unified Speech Enhancement and Editing (uSee) model with conditional diffusion models to handle various tasks at the same time in a generative manner. Specifically, by providing multiple types of conditions including self-supervised learning embeddings and proper text prompts to the score-based diffusion model, we can enable controllable generation of the unified speech enhancement and editing model to perform corresponding actions on the source speech. Our experiments show that our proposed uSee model can achieve superior performance in both speech denoising and dereverberation compared to other related generative speech enhancement models, and can perform speech editing given desired environmental sound text description, signal-to-noise ratios (SNR), and room impulse responses (RIR). Demos of the generated speech are available at https://muqiaoy.github.io/usee.
Unifying Robustness and Fidelity: A Comprehensive Study of Pretrained Generative Methods for Speech Enhancement in Adverse Conditions
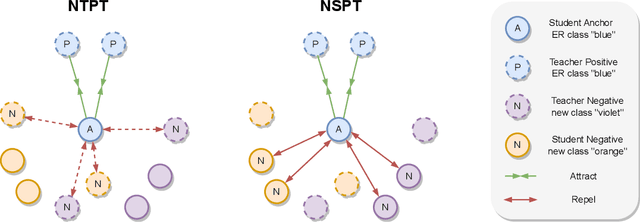
Sep 16, 2023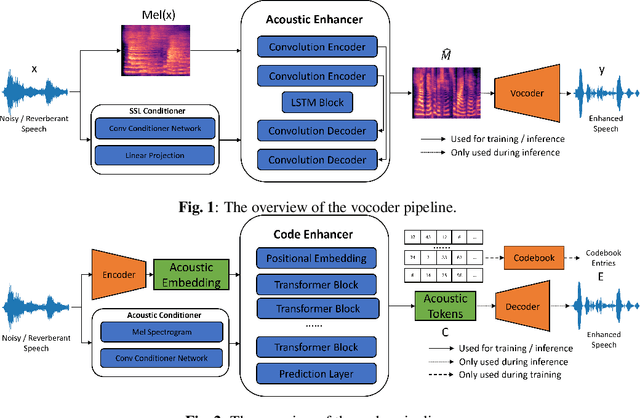

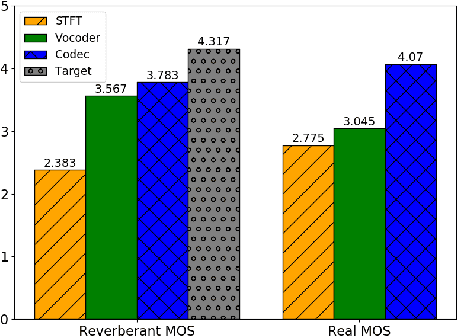
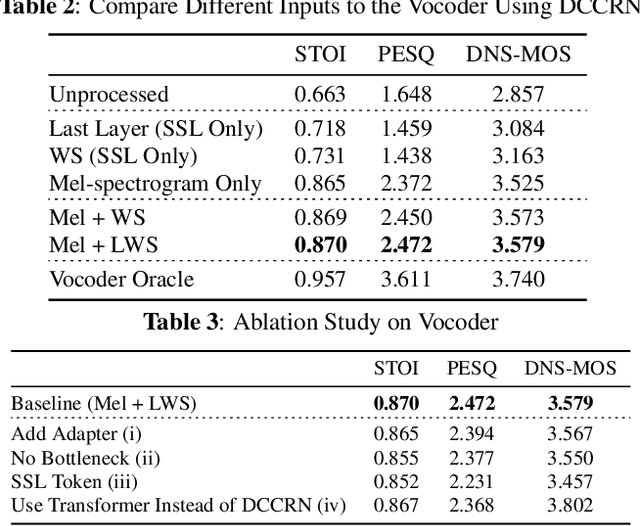
Enhancing speech signal quality in adverse acoustic environments is a persistent challenge in speech processing. Existing deep learning based enhancement methods often struggle to effectively remove background noise and reverberation in real-world scenarios, hampering listening experiences. To address these challenges, we propose a novel approach that uses pre-trained generative methods to resynthesize clean, anechoic speech from degraded inputs. This study leverages pre-trained vocoder or codec models to synthesize high-quality speech while enhancing robustness in challenging scenarios. Generative methods effectively handle information loss in speech signals, resulting in regenerated speech that has improved fidelity and reduced artifacts. By harnessing the capabilities of pre-trained models, we achieve faithful reproduction of the original speech in adverse conditions. Experimental evaluations on both simulated datasets and realistic samples demonstrate the effectiveness and robustness of our proposed methods. Especially by leveraging codec, we achieve superior subjective scores for both simulated and realistic recordings. The generated speech exhibits enhanced audio quality, reduced background noise, and reverberation. Our findings highlight the potential of pre-trained generative techniques in speech processing, particularly in scenarios where traditional methods falter. Demos are available at https://whmrtm.github.io/SoundResynthesis.
SpatialCodec: Neural Spatial Speech Coding
Sep 14, 2023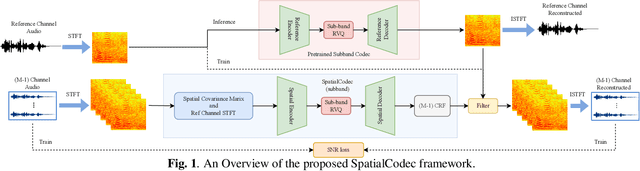
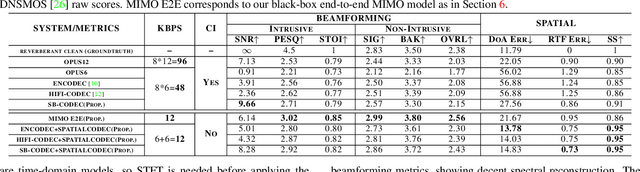

In this work, we address the challenge of encoding speech captured by a microphone array using deep learning techniques with the aim of preserving and accurately reconstructing crucial spatial cues embedded in multi-channel recordings. We propose a neural spatial audio coding framework that achieves a high compression ratio, leveraging single-channel neural sub-band codec and SpatialCodec. Our approach encompasses two phases: (i) a neural sub-band codec is designed to encode the reference channel with low bit rates, and (ii), a SpatialCodec captures relative spatial information for accurate multi-channel reconstruction at the decoder end. In addition, we also propose novel evaluation metrics to assess the spatial cue preservation: (i) spatial similarity, which calculates cosine similarity on a spatially intuitive beamspace, and (ii), beamformed audio quality. Our system shows superior spatial performance compared with high bitrate baselines and black-box neural architecture. Demos are available at https://xzwy.github.io/SpatialCodecDemo. Codes and models are available at https://github.com/XZWY/SpatialCodec.
Rethinking Voice-Face Correlation: A Geometry View
Jul 26, 2023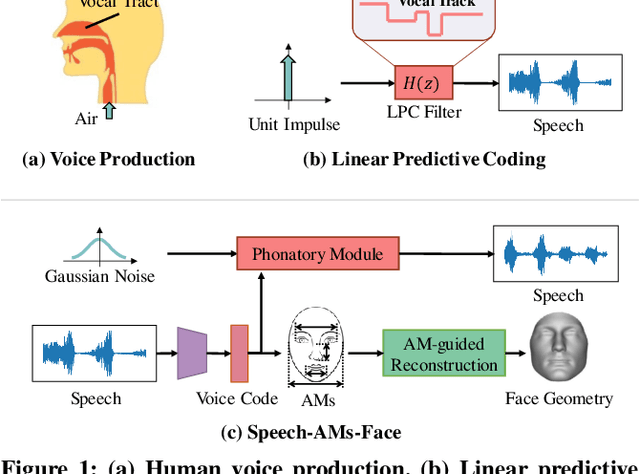

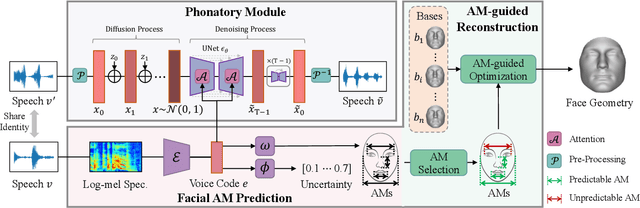

Previous works on voice-face matching and voice-guided face synthesis demonstrate strong correlations between voice and face, but mainly rely on coarse semantic cues such as gender, age, and emotion. In this paper, we aim to investigate the capability of reconstructing the 3D facial shape from voice from a geometry perspective without any semantic information. We propose a voice-anthropometric measurement (AM)-face paradigm, which identifies predictable facial AMs from the voice and uses them to guide 3D face reconstruction. By leveraging AMs as a proxy to link the voice and face geometry, we can eliminate the influence of unpredictable AMs and make the face geometry tractable. Our approach is evaluated on our proposed dataset with ground-truth 3D face scans and corresponding voice recordings, and we find significant correlations between voice and specific parts of the face geometry, such as the nasal cavity and cranium. Our work offers a new perspective on voice-face correlation and can serve as a good empirical study for anthropometry science.
Sequence-Level Knowledge Distillation for Class-Incremental End-to-End Spoken Language Understanding
May 23, 2023The ability to learn new concepts sequentially is a major weakness for modern neural networks, which hinders their use in non-stationary environments. Their propensity to fit the current data distribution to the detriment of the past acquired knowledge leads to the catastrophic forgetting issue. In this work we tackle the problem of Spoken Language Understanding applied to a continual learning setting. We first define a class-incremental scenario for the SLURP dataset. Then, we propose three knowledge distillation (KD) approaches to mitigate forgetting for a sequence-to-sequence transformer model: the first KD method is applied to the encoder output (audio-KD), and the other two work on the decoder output, either directly on the token-level (tok-KD) or on the sequence-level (seq-KD) distributions. We show that the seq-KD substantially improves all the performance metrics, and its combination with the audio-KD further decreases the average WER and enhances the entity prediction metric.
Backdoor Attacks with Input-unique Triggers in NLP
Mar 25, 2023



Backdoor attack aims at inducing neural models to make incorrect predictions for poison data while keeping predictions on the clean dataset unchanged, which creates a considerable threat to current natural language processing (NLP) systems. Existing backdoor attacking systems face two severe issues:firstly, most backdoor triggers follow a uniform and usually input-independent pattern, e.g., insertion of specific trigger words, synonym replacement. This significantly hinders the stealthiness of the attacking model, leading the trained backdoor model being easily identified as malicious by model probes. Secondly, trigger-inserted poisoned sentences are usually disfluent, ungrammatical, or even change the semantic meaning from the original sentence, making them being easily filtered in the pre-processing stage. To resolve these two issues, in this paper, we propose an input-unique backdoor attack(NURA), where we generate backdoor triggers unique to inputs. IDBA generates context-related triggers by continuing writing the input with a language model like GPT2. The generated sentence is used as the backdoor trigger. This strategy not only creates input-unique backdoor triggers, but also preserves the semantics of the original input, simultaneously resolving the two issues above. Experimental results show that the IDBA attack is effective for attack and difficult to defend: it achieves high attack success rate across all the widely applied benchmarks, while is immune to existing defending methods. In addition, it is able to generate fluent, grammatical, and diverse backdoor inputs, which can hardly be recognized through human inspection.
TAPLoss: A Temporal Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023
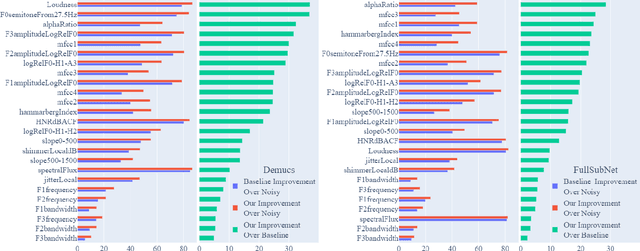

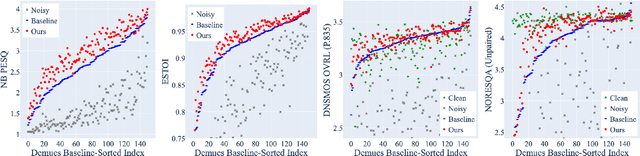
Speech enhancement models have greatly progressed in recent years, but still show limits in perceptual quality of their speech outputs. We propose an objective for perceptual quality based on temporal acoustic parameters. These are fundamental speech features that play an essential role in various applications, including speaker recognition and paralinguistic analysis. We provide a differentiable estimator for four categories of low-level acoustic descriptors involving: frequency-related parameters, energy or amplitude-related parameters, spectral balance parameters, and temporal features. Unlike prior work that looks at aggregated acoustic parameters or a few categories of acoustic parameters, our temporal acoustic parameter (TAP) loss enables auxiliary optimization and improvement of many fine-grain speech characteristics in enhancement workflows. We show that adding TAPLoss as an auxiliary objective in speech enhancement produces speech with improved perceptual quality and intelligibility. We use data from the Deep Noise Suppression 2020 Challenge to demonstrate that both time-domain models and time-frequency domain models can benefit from our method.
PAAPLoss: A Phonetic-Aligned Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023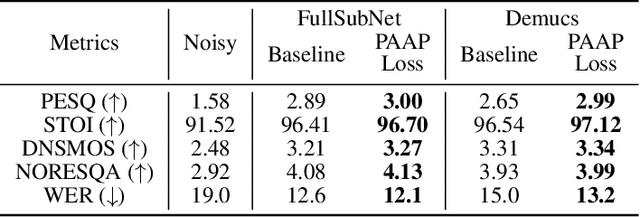
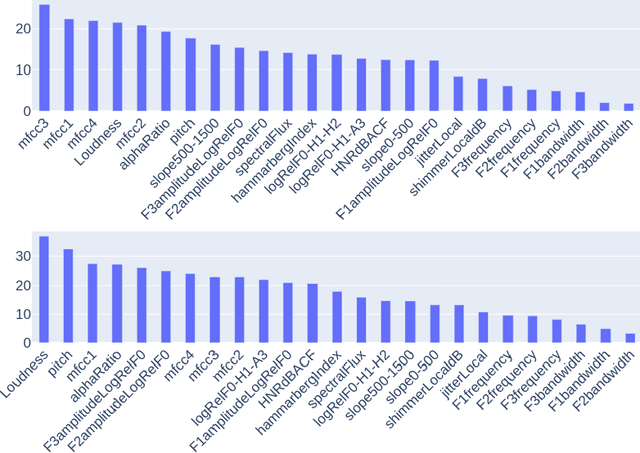
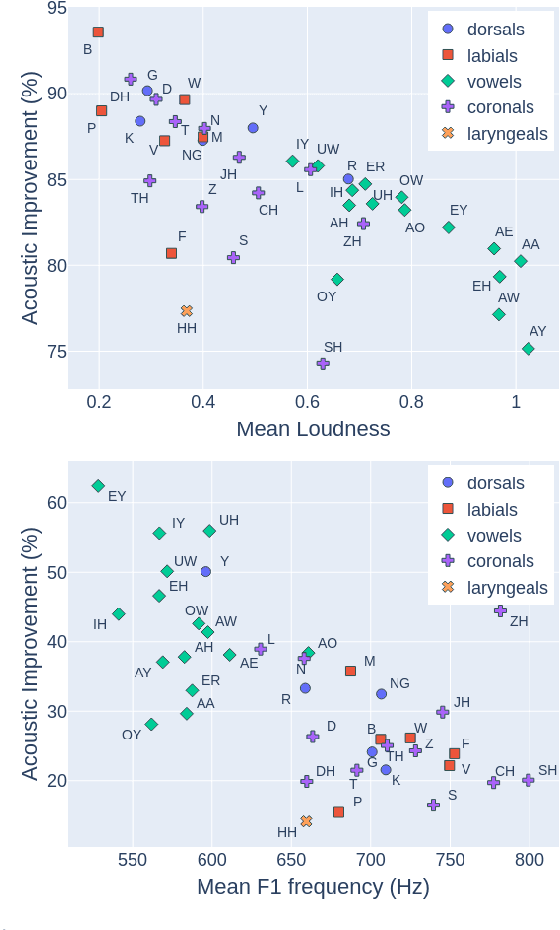
Despite rapid advancement in recent years, current speech enhancement models often produce speech that differs in perceptual quality from real clean speech. We propose a learning objective that formalizes differences in perceptual quality, by using domain knowledge of acoustic-phonetics. We identify temporal acoustic parameters -- such as spectral tilt, spectral flux, shimmer, etc. -- that are non-differentiable, and we develop a neural network estimator that can accurately predict their time-series values across an utterance. We also model phoneme-specific weights for each feature, as the acoustic parameters are known to show different behavior in different phonemes. We can add this criterion as an auxiliary loss to any model that produces speech, to optimize speech outputs to match the values of clean speech in these features. Experimentally we show that it improves speech enhancement workflows in both time-domain and time-frequency domain, as measured by standard evaluation metrics. We also provide an analysis of phoneme-dependent improvement on acoustic parameters, demonstrating the additional interpretability that our method provides. This analysis can suggest which features are currently the bottleneck for improvement.