 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decade-Scale Benchmark Evaluating LLMs' Clinical Practice Guidelines Detection and Adherence in Multi-turn Conversations
Mar 26, 2026Clinical practice guidelines (CPGs) play a pivotal role in ensuring evidence-based decision-making and improving patient outcomes. While Large Language Models (LLMs) are increasingly deployed in healthcare scenarios, it is unclear to which extend LLMs could identify and adhere to CPGs during conversations. To address this gap, we introduce CPGBench, an automated framework benchmarking the clinical guideline detection and adherence capabilities of LLMs in multi-turn conversations. We collect 3,418 CPG documents from 9 countries/regions and 2 international organizations published in the last decade spanning across 24 specialties. From these documents, we extract 32,155 clinical recommendations with corresponding publication institute, date, country, specialty, recommendation strength, evidence level, etc. One multi-turn conversation is generated for each recommendation accordingly to evaluate the detection and adherence capabilities of 8 leading LLMs. We find that the 71.1%-89.6% recommendations can be correctly detected, while only 3.6%-29.7% corresponding titles can be correctly referenced, revealing the gap between knowing the guideline contents and where they come from. The adherence rates range from 21.8% to 63.2% in different models, indicating a large gap between knowing the guidelines and being able to apply them. To confirm the validity of our automatic analysis, we further conduct a comprehensive human evaluation involving 56 clinicians from different specialties. To our knowledge, CPGBench is the first benchmark systematically revealing which clinical recommendations LLMs fail to detect or adhere to during conversations. Given that each clinical recommendation may affect a large population and that clinical applications are inherently safety critical, addressing these gaps is crucial for the safe and responsible deployment of LLMs in real world clinical practice.
CARE: Towards Clinical Accountability in Multi-Modal Medical Reasoning with an Evidence-Grounded Agentic Framework
Mar 02, 2026Large visual language models (VLMs) have shown strong multi-modal medical reasoning ability, but most operate as end-to-end black boxes, diverging from clinicians' evidence-based, staged workflows and hindering clinical accountability. Complementarily, expert visual grounding models can accurately localize regions of interest (ROIs), providing explicit, reliable evidence that improves both reasoning accuracy and trust. In this paper, we introduce CARE, advancing Clinical Accountability in multi-modal medical Reasoning with an Evidence-grounded agentic framework. Unlike existing approaches that couple grounding and reasoning within a single generalist model, CARE decomposes the task into coordinated sub-modules to reduce shortcut learning and hallucination: a compact VLM proposes relevant medical entities; an expert entity-referring segmentation model produces pixel-level ROI evidence; and a grounded VLM reasons over the full image augmented by ROI hints. The VLMs are optimized with reinforcement learning with verifiable rewards to align answers with supporting evidence. Furthermore, a VLM coordinator plans tool invocation and reviews evidence-answer consistency, providing agentic control and final verification. Evaluated on standard medical VQA benchmarks, our CARE-Flow (coordinator-free) improves average accuracy by 10.9% over the same size (10B) state-of-the-art (SOTA). With dynamic planning and answer review, our CARE-Coord yields a further gain, outperforming the heavily pre-trained SOTA by 5.2%. Our experiments demonstrate that an agentic framework that emulates clinical workflows, incorporating decoupled specialized models and explicit evidence, yields more accurate and accountable medical AI.
GS-Marker: Generalizable and Robust Watermarking for 3D Gaussian Splatting
Mar 24, 2025



In the Generative AI era, safeguarding 3D models has become increasingly urgent. While invisible watermarking is well-established for 2D images with encoder-decoder frameworks, generalizable and robust solutions for 3D remain elusive. The main difficulty arises from the renderer between the 3D encoder and 2D decoder, which disrupts direct gradient flow and complicates training. Existing 3D methods typically rely on per-scene iterative optimization, resulting in time inefficiency and limited generalization. In this work, we propose a single-pass watermarking approach for 3D Gaussian Splatting (3DGS), a well-known yet underexplored representation for watermarking. We identify two major challenges: (1) ensuring effective training generalized across diverse 3D models, and (2) reliably extracting watermarks from free-view renderings, even under distortions. Our framework, named GS-Marker, incorporates a 3D encoder to embed messages, distortion layers to enhance resilience against various distortions, and a 2D decoder to extract watermarks from renderings. A key innovation is the Adaptive Marker Control mechanism that adaptively perturbs the initially optimized 3DGS, escaping local minima and improving both training stability and convergence. Extensive experiments show that GS-Marker outperforms per-scene training approaches in terms of decoding accuracy and model fidelity, while also significantly reducing computation time.
StreamGS: Online Generalizable Gaussian Splatting Reconstruction for Unposed Image Streams
Mar 08, 2025



The advent of 3D Gaussian Splatting (3DGS) has advanced 3D scene reconstruction and novel view synthesis. With the growing interest of interactive applications that need immediate feedback, online 3DGS reconstruction in real-time is in high demand. However, none of existing methods yet meet the demand due to three main challenges: the absence of predetermined camera parameters, the need for generalizable 3DGS optimization, and the necessity of reducing redundancy. We propose StreamGS, an online generalizable 3DGS reconstruction method for unposed image streams, which progressively transform image streams to 3D Gaussian streams by predicting and aggregating per-frame Gaussians. Our method overcomes the limitation of the initial point reconstruction \cite{dust3r} in tackling out-of-domain (OOD) issues by introducing a content adaptive refinement. The refinement enhances cross-frame consistency by establishing reliable pixel correspondences between adjacent frames. Such correspondences further aid in merging redundant Gaussians through cross-frame feature aggregation. The density of Gaussians is thereby reduced, empowering online reconstruction by significantly lowering computational and memory costs. Extensive experiments on diverse datasets have demonstrated that StreamGS achieves quality on par with optimization-based approaches but does so 150 times faster, and exhibits superior generalizability in handling OOD scenes.
UVRM: A Scalable 3D Reconstruction Model from Unposed Videos
Jan 16, 2025



Large Reconstruction Models (LRMs) have recently become a popular method for creating 3D foundational models. Training 3D reconstruction models with 2D visual data traditionally requires prior knowledge of camera poses for the training samples, a process that is both time-consuming and prone to errors. Consequently, 3D reconstruction training has been confined to either synthetic 3D datasets or small-scale datasets with annotated poses. In this study, we investigate the feasibility of 3D reconstruction using unposed video data of various objects. We introduce UVRM, a novel 3D reconstruction model capable of being trained and evaluated on monocular videos without requiring any information about the pose. UVRM uses a transformer network to implicitly aggregate video frames into a pose-invariant latent feature space, which is then decoded into a tri-plane 3D representation. To obviate the need for ground-truth pose annotations during training, UVRM employs a combination of the score distillation sampling (SDS) method and an analysis-by-synthesis approach, progressively synthesizing pseudo novel-views using a pre-trained diffusion model. We qualitatively and quantitatively evaluate UVRM's performance on the G-Objaverse and CO3D datasets without relying on pose information. Extensive experiments show that UVRM is capable of effectively and efficiently reconstructing a wide range of 3D objects from unposed videos.
Efficient Autoregressive Audio Modeling via Next-Scale Prediction
Aug 16, 2024



Audio generation has achieved remarkable progress with the advance of sophisticated generative models, such as diffusion models (DMs) and autoregressive (AR) models. However, due to the naturally significant sequence length of audio, the efficiency of audio generation remains an essential issue to be addressed, especially for AR models that are incorporated in large language models (LLMs). In this paper, we analyze the token length of audio tokenization and propose a novel \textbf{S}cale-level \textbf{A}udio \textbf{T}okenizer (SAT), with improved residual quantization. Based on SAT, a scale-level \textbf{A}coustic \textbf{A}uto\textbf{R}egressive (AAR) modeling framework is further proposed, which shifts the next-token AR prediction to next-scale AR prediction, significantly reducing the training cost and inference time. To validate the effectiveness of the proposed approach, we comprehensively analyze design choices and demonstrate the proposed AAR framework achieves a remarkable \textbf{35}$\times$ faster inference speed and +\textbf{1.33} Fr\'echet Audio Distance (FAD) against baselines on the AudioSet benchmark. Code: \url{https://github.com/qiuk2/AAR}.
$\text{R}^2$-Bench: Benchmarking the Robustness of Referring Perception Models under Perturbations
Mar 07, 2024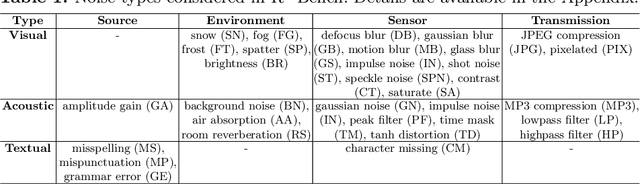


Referring perception, which aims at grounding visual objects with multimodal referring guidance, is essential for bridging the gap between humans, who provide instructions, and the environment where intelligent systems perceive. Despite progress in this field, the robustness of referring perception models (RPMs) against disruptive perturbations is not well explored. This work thoroughly assesses the resilience of RPMs against various perturbations in both general and specific contexts. Recognizing the complex nature of referring perception tasks, we present a comprehensive taxonomy of perturbations, and then develop a versatile toolbox for synthesizing and evaluating the effects of composite disturbances. Employing this toolbox, we construct $\text{R}^2$-Bench, a benchmark for assessing the Robustness of Referring perception models under noisy conditions across five key tasks. Moreover, we propose the $\text{R}^2$-Agent, an LLM-based agent that simplifies and automates model evaluation via natural language instructions. Our investigation uncovers the vulnerabilities of current RPMs to various perturbations and provides tools for assessing model robustness, potentially promoting the safe and resilient integration of intelligent systems into complex real-world scenarios.
Rethinking Audiovisual Segmentation with Semantic Quantization and Decomposition
Sep 29, 2023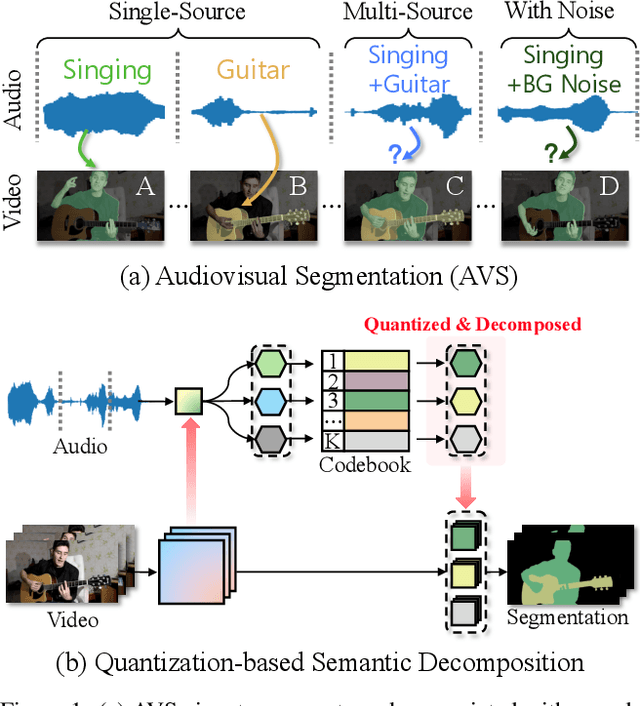
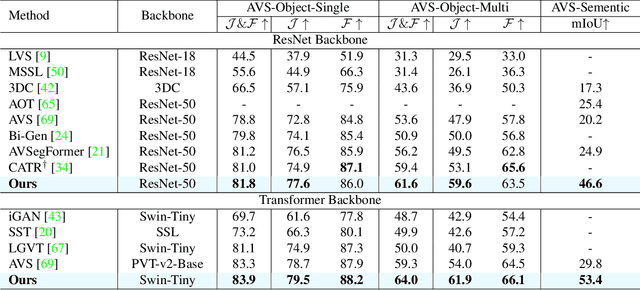
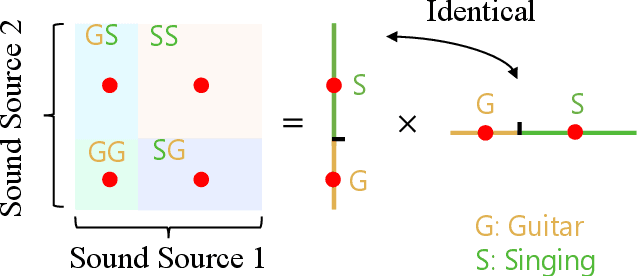
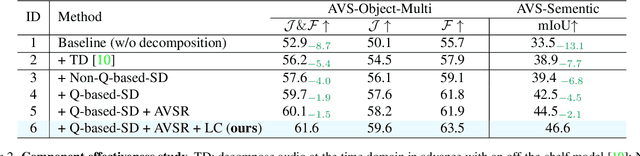
Audiovisual segmentation (AVS) is a challenging task that aims to segment visual objects in videos based on their associated acoustic cues. With multiple sound sources involved, establishing robust correspondences between audio and visual contents poses unique challenges due to its (1) intricate entanglement across sound sources and (2) frequent shift among sound events. Assuming sound events occur independently, the multi-source semantic space (which encompasses all possible semantic categories) can be viewed as the Cartesian product of single-source sub-spaces. This motivates us to decompose the multi-source audio semantics into single-source semantics, allowing for more effective interaction with visual content. Specifically, we propose a semantic decomposition method based on product quantization, where the multi-source semantics can be decomposed and represented by several quantized single-source semantics. Furthermore, we introduce a global-to-local quantization mechanism that distills knowledge from stable global (clip-level) features into local (frame-level) ones to handle the constant shift of audio semantics. Extensive experiments demonstrate that semantically quantized and decomposed audio representation significantly improves AVS performance, e.g., +21.2% mIoU on the most challenging AVS-Semantic benchmark.
Efficient View Synthesis with Neural Radiance Distribution Field
Aug 22, 2023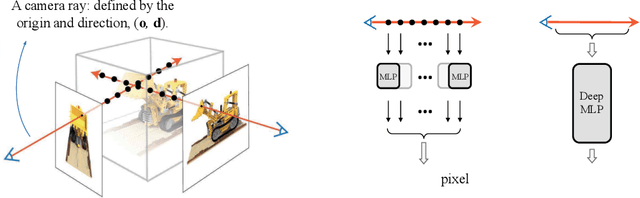

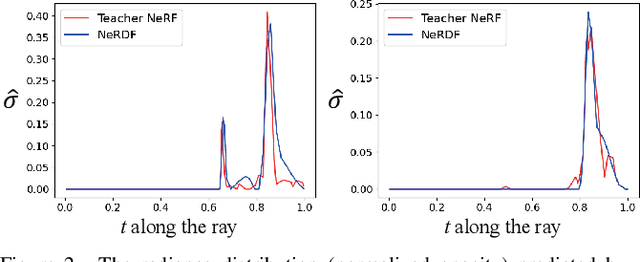
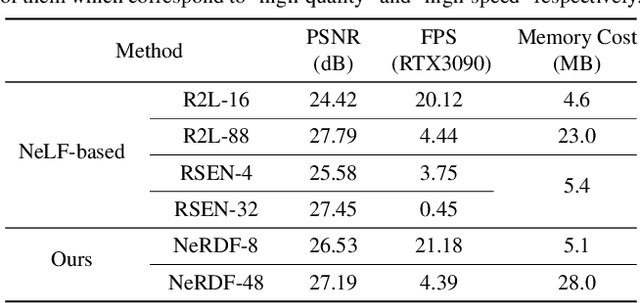
Recent work on Neural Radiance Fields (NeRF) has demonstrated significant advances in high-quality view synthesis. A major limitation of NeRF is its low rendering efficiency due to the need for multiple network forwardings to render a single pixel. Existing methods to improve NeRF either reduce the number of required samples or optimize the implementation to accelerate the network forwarding. Despite these efforts, the problem of multiple sampling persists due to the intrinsic representation of radiance fields. In contrast, Neural Light Fields (NeLF) reduce the computation cost of NeRF by querying only one single network forwarding per pixel. To achieve a close visual quality to NeRF, existing NeLF methods require significantly larger network capacities which limits their rendering efficiency in practice. In this work, we propose a new representation called Neural Radiance Distribution Field (NeRDF) that targets efficient view synthesis in real-time. Specifically, we use a small network similar to NeRF while preserving the rendering speed with a single network forwarding per pixel as in NeLF. The key is to model the radiance distribution along each ray with frequency basis and predict frequency weights using the network. Pixel values are then computed via volume rendering on radiance distributions. Experiments show that our proposed method offers a better trade-off among speed, quality, and network size than existing methods: we achieve a ~254x speed-up over NeRF with similar network size, with only a marginal performance decline. Our project page is at yushuang-wu.github.io/NeRDF.
Rethinking Voice-Face Correlation: A Geometry View
Jul 26, 2023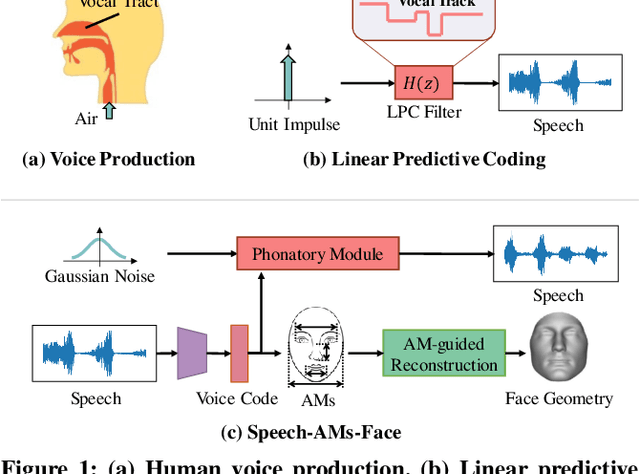

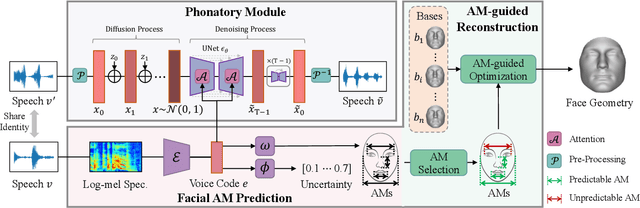

Previous works on voice-face matching and voice-guided face synthesis demonstrate strong correlations between voice and face, but mainly rely on coarse semantic cues such as gender, age, and emotion. In this paper, we aim to investigate the capability of reconstructing the 3D facial shape from voice from a geometry perspective without any semantic information. We propose a voice-anthropometric measurement (AM)-face paradigm, which identifies predictable facial AMs from the voice and uses them to guide 3D face reconstruction. By leveraging AMs as a proxy to link the voice and face geometry, we can eliminate the influence of unpredictable AMs and make the face geometry tractable. Our approach is evaluated on our proposed dataset with ground-truth 3D face scans and corresponding voice recordings, and we find significant correlations between voice and specific parts of the face geometry, such as the nasal cavity and cranium. Our work offers a new perspective on voice-face correlation and can serve as a good empirical study for anthropometry science.