 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Long Video Understanding with Audiovisual Entity Cohesion and Agentic Search
Jan 20, 2026Long video understanding presents significant challenges for vision-language models due to extremely long context windows. Existing solutions relying on naive chunking strategies with retrieval-augmented generation, typically suffer from information fragmentation and a loss of global coherence. We present HAVEN, a unified framework for long-video understanding that enables coherent and comprehensive reasoning by integrating audiovisual entity cohesion and hierarchical video indexing with agentic search. First, we preserve semantic consistency by integrating entity-level representations across visual and auditory streams, while organizing content into a structured hierarchy spanning global summary, scene, segment, and entity levels. Then we employ an agentic search mechanism to enable dynamic retrieval and reasoning across these layers, facilitating coherent narrative reconstruction and fine-grained entity tracking. Extensive experiments demonstrate that our method achieves good temporal coherence, entity consistency, and retrieval efficiency, establishing a new state-of-the-art with an overall accuracy of 84.1% on LVBench. Notably, it achieves outstanding performance in the challenging reasoning category, reaching 80.1%. These results highlight the effectiveness of structured, multimodal reasoning for comprehensive and context-consistent understanding of long-form videos.
Bitrate-Controlled Diffusion for Disentangling Motion and Content in Video
Sep 10, 2025We propose a novel and general framework to disentangle video data into its dynamic motion and static content components. Our proposed method is a self-supervised pipeline with less assumptions and inductive biases than previous works: it utilizes a transformer-based architecture to jointly generate flexible implicit features for frame-wise motion and clip-wise content, and incorporates a low-bitrate vector quantization as an information bottleneck to promote disentanglement and form a meaningful discrete motion space. The bitrate-controlled latent motion and content are used as conditional inputs to a denoising diffusion model to facilitate self-supervised representation learning. We validate our disentangled representation learning framework on real-world talking head videos with motion transfer and auto-regressive motion generation tasks. Furthermore, we also show that our method can generalize to other types of video data, such as pixel sprites of 2D cartoon characters. Our work presents a new perspective on self-supervised learning of disentangled video representations, contributing to the broader field of video analysis and generation.
Text-Queried Audio Source Separation via Hierarchical Modeling
May 27, 2025



Target audio source separation with natural language queries presents a promising paradigm for extracting arbitrary audio events through arbitrary text descriptions. Existing methods mainly face two challenges, the difficulty in jointly modeling acoustic-textual alignment and semantic-aware separation within a blindly-learned single-stage architecture, and the reliance on large-scale accurately-labeled training data to compensate for inefficient cross-modal learning and separation. To address these challenges, we propose a hierarchical decomposition framework, HSM-TSS, that decouples the task into global-local semantic-guided feature separation and structure-preserving acoustic reconstruction. Our approach introduces a dual-stage mechanism for semantic separation, operating on distinct global and local semantic feature spaces. We first perform global-semantic separation through a global semantic feature space aligned with text queries. A Q-Audio architecture is employed to align audio and text modalities, serving as pretrained global-semantic encoders. Conditioned on the predicted global feature, we then perform the second-stage local-semantic separation on AudioMAE features that preserve time-frequency structures, followed by acoustic reconstruction. We also propose an instruction processing pipeline to parse arbitrary text queries into structured operations, extraction or removal, coupled with audio descriptions, enabling flexible sound manipulation. Our method achieves state-of-the-art separation performance with data-efficient training while maintaining superior semantic consistency with queries in complex auditory scenes.
Universal Speech Token Learning via Low-Bitrate Neural Codec and Pretrained Representations
Mar 15, 2025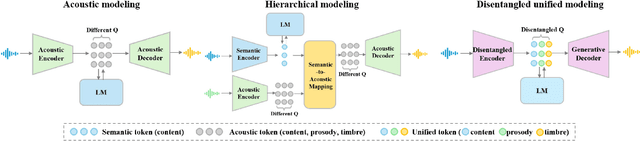
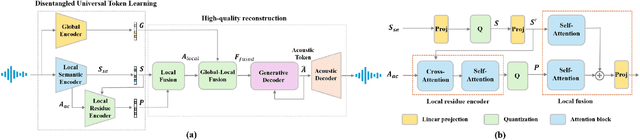
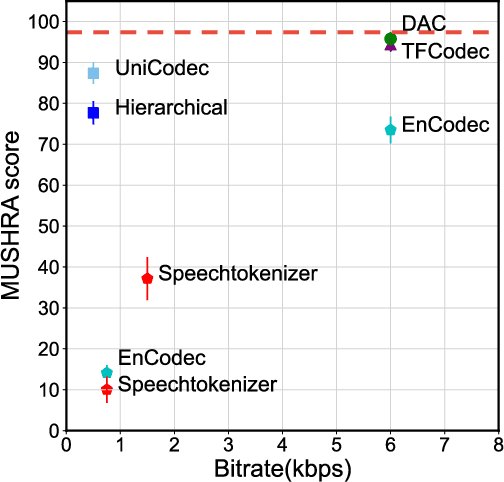

Current large speech language models are mainly based on semantic tokens from discretization of self-supervised learned representations and acoustic tokens from a neural codec, following a semantic-modeling and acoustic-synthesis paradigm. However, semantic tokens discard paralinguistic attributes of speakers that is important for natural spoken communication, while prompt-based acoustic synthesis from semantic tokens has limits in recovering paralinguistic details and suffers from robustness issues, especially when there are domain gaps between the prompt and the target. This paper unifies two types of tokens and proposes the UniCodec, a universal speech token learning that encapsulates all semantics of speech, including linguistic and paralinguistic information, into a compact and semantically-disentangled unified token. Such a unified token can not only benefit speech language models in understanding with paralinguistic hints but also help speech generation with high-quality output. A low-bitrate neural codec is leveraged to learn such disentangled discrete representations at global and local scales, with knowledge distilled from self-supervised learned features. Extensive evaluations on multilingual datasets demonstrate its effectiveness in generating natural, expressive and long-term consistent output quality with paralinguistic attributes well preserved in several speech processing tasks.
Convert and Speak: Zero-shot Accent Conversion with Minimum Supervision
Aug 22, 2024Low resource of parallel data is the key challenge of accent conversion(AC) problem in which both the pronunciation units and prosody pattern need to be converted. We propose a two-stage generative framework "convert-and-speak" in which the conversion is only operated on the semantic token level and the speech is synthesized conditioned on the converted semantic token with a speech generative model in target accent domain. The decoupling design enables the "speaking" module to use massive amount of target accent speech and relieves the parallel data required for the "conversion" module. Conversion with the bridge of semantic token also relieves the requirement for the data with text transcriptions and unlocks the usage of language pre-training technology to further efficiently reduce the need of parallel accent speech data. To reduce the complexity and latency of "speaking", a single-stage AR generative model is designed to achieve good quality as well as lower computation cost. Experiments on Indian-English to general American-English conversion show that the proposed framework achieves state-of-the-art performance in accent similarity, speech quality, and speaker maintenance with only 15 minutes of weakly parallel data which is not constrained to the same speaker. Extensive experimentation with diverse accent types suggests that this framework possesses a high degree of adaptability, making it readily scalable to accommodate other accents with low-resource data. Audio samples are available at https://www.microsoft.com/en-us/research/project/convert-and-speak-zero-shot-accent-conversion-with-minimumsupervision/.
Masked Audio Modeling with CLAP and Multi-Objective Learning
Jan 29, 2024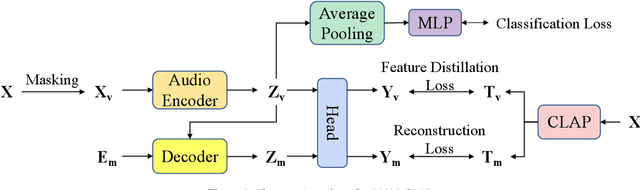
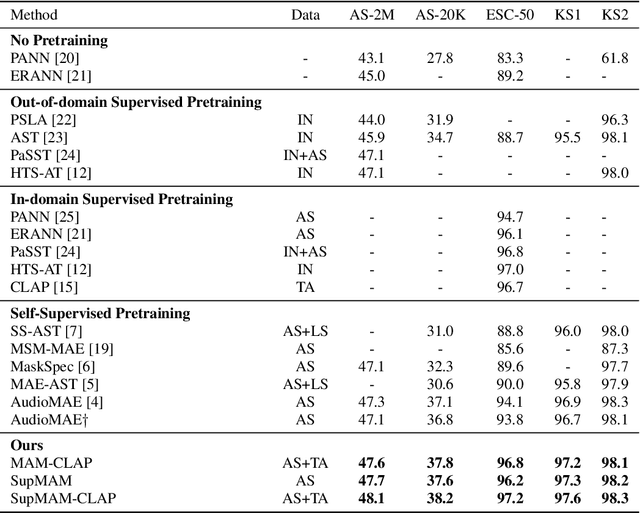
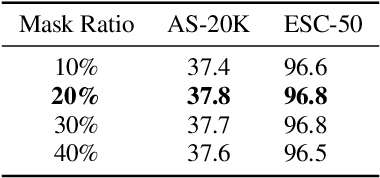
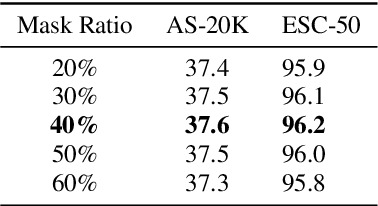
Most existing masked audio modeling (MAM) methods learn audio representations by masking and reconstructing local spectrogram patches. However, the reconstruction loss mainly accounts for the signal-level quality of the reconstructed spectrogram and is still limited in extracting high-level audio semantics. In this paper, we propose to enhance the semantic modeling of MAM by distilling cross-modality knowledge from contrastive language-audio pretraining (CLAP) representations for both masked and unmasked regions (MAM-CLAP) and leveraging a multi-objective learning strategy with a supervised classification branch (SupMAM), thereby providing more semantic knowledge for MAM and enabling it to effectively learn global features from labels. Experiments show that our methods significantly improve the performance on multiple downstream tasks. Furthermore, by combining our MAM-CLAP with SupMAM, we can achieve new state-of-the-art results on various audio and speech classification tasks, exceeding previous self-supervised learning and supervised pretraining methods.
Low-latency Speech Enhancement via Speech Token Generation
Oct 20, 2023Existing deep learning based speech enhancement mainly employ a data-driven approach, which leverage large amounts of data with a variety of noise types to achieve noise removal from noisy signal. However, the high dependence on the data limits its generalization on the unseen complex noises in real-life environment. In this paper, we focus on the low-latency scenario and regard speech enhancement as a speech generation problem conditioned on the noisy signal, where we generate clean speech instead of identifying and removing noises. Specifically, we propose a conditional generative framework for speech enhancement, which models clean speech by acoustic codes of a neural speech codec and generates the speech codes conditioned on past noisy frames in an auto-regressive way. Moreover, we propose an explicit-alignment approach to align noisy frames with the generated speech tokens to improve the robustness and scalability to different input lengths. Different from other methods that leverage multiple stages to generate speech codes, we leverage a single-stage speech generation approach based on the TF-Codec neural codec to achieve high speech quality with low latency. Extensive results on both synthetic and real-recorded test set show its superiority over data-driven approaches in terms of noise robustness and temporal speech coherence.
Rethinking Audiovisual Segmentation with Semantic Quantization and Decomposition
Sep 29, 2023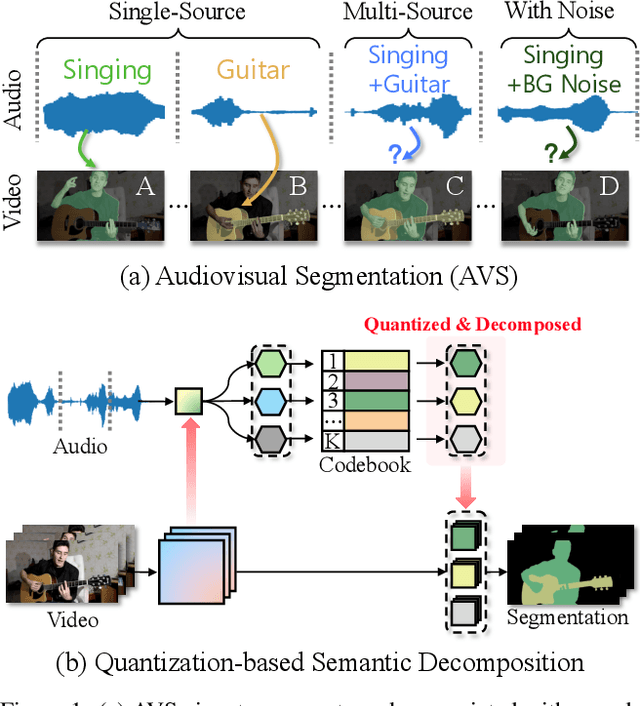
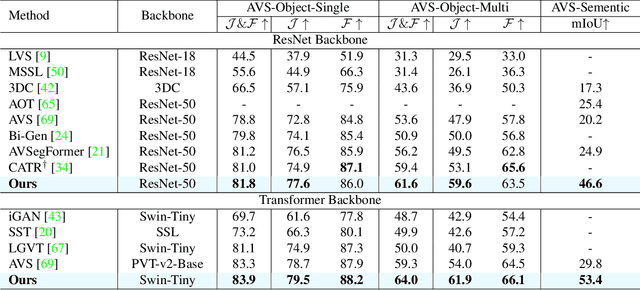
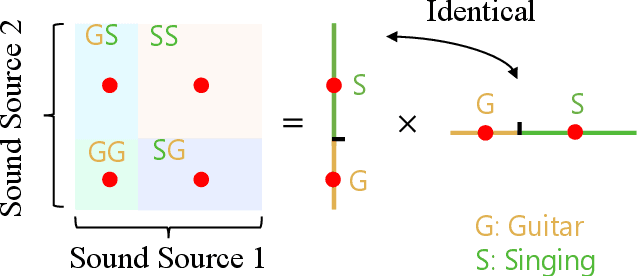
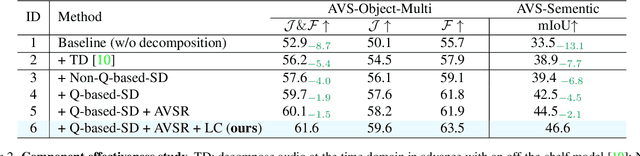
Audiovisual segmentation (AVS) is a challenging task that aims to segment visual objects in videos based on their associated acoustic cues. With multiple sound sources involved, establishing robust correspondences between audio and visual contents poses unique challenges due to its (1) intricate entanglement across sound sources and (2) frequent shift among sound events. Assuming sound events occur independently, the multi-source semantic space (which encompasses all possible semantic categories) can be viewed as the Cartesian product of single-source sub-spaces. This motivates us to decompose the multi-source audio semantics into single-source semantics, allowing for more effective interaction with visual content. Specifically, we propose a semantic decomposition method based on product quantization, where the multi-source semantics can be decomposed and represented by several quantized single-source semantics. Furthermore, we introduce a global-to-local quantization mechanism that distills knowledge from stable global (clip-level) features into local (frame-level) ones to handle the constant shift of audio semantics. Extensive experiments demonstrate that semantically quantized and decomposed audio representation significantly improves AVS performance, e.g., +21.2% mIoU on the most challenging AVS-Semantic benchmark.
ABC-KD: Attention-Based-Compression Knowledge Distillation for Deep Learning-Based Noise Suppression
May 26, 2023Noise suppression (NS) models have been widely applied to enhance speech quality. Recently, Deep Learning-Based NS, which we denote as Deep Noise Suppression (DNS), became the mainstream NS method due to its excelling performance over traditional ones. However, DNS models face 2 major challenges for supporting the real-world applications. First, high-performing DNS models are usually large in size, causing deployment difficulties. Second, DNS models require extensive training data, including noisy audios as inputs and clean audios as labels. It is often difficult to obtain clean labels for training DNS models. We propose the use of knowledge distillation (KD) to resolve both challenges. Our study serves 2 main purposes. To begin with, we are among the first to comprehensively investigate mainstream KD techniques on DNS models to resolve the two challenges. Furthermore, we propose a novel Attention-Based-Compression KD method that outperforms all investigated mainstream KD frameworks on DNS task.
DasFormer: Deep Alternating Spectrogram Transformer for Multi/Single-Channel Speech Separation
Mar 14, 2023



For the task of speech separation, previous study usually treats multi-channel and single-channel scenarios as two research tracks with specialized solutions developed respectively. Instead, we propose a simple and unified architecture - DasFormer (Deep alternating spectrogram transFormer) to handle both of them in the challenging reverberant environments. Unlike frame-wise sequence modeling, each TF-bin in the spectrogram is assigned with an embedding encoding spectral and spatial information. With such input, DasFormer is then formed by multiple repetition of simple blocks each of which integrates 1) two multi-head self-attention (MHSA) modules alternately processing within each frequency bin & temporal frame of the spectrogram 2) MBConv before each MHSA for modeling local features on the spectrogram. Experiments show that DasFormer has a powerful ability to model the time-frequency representation, whose performance far exceeds the current SOTA models in multi-channel speech separation, and also achieves single-channel SOTA in the more challenging yet realistic reverberation scenario.