 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Speech Token Learning via Low-Bitrate Neural Codec and Pretrained Representations
Paper and Code
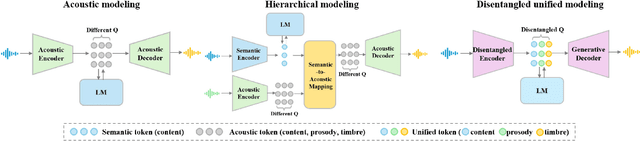
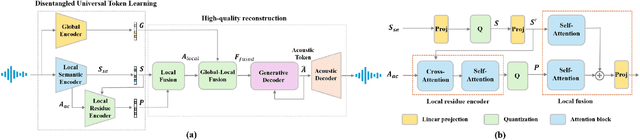
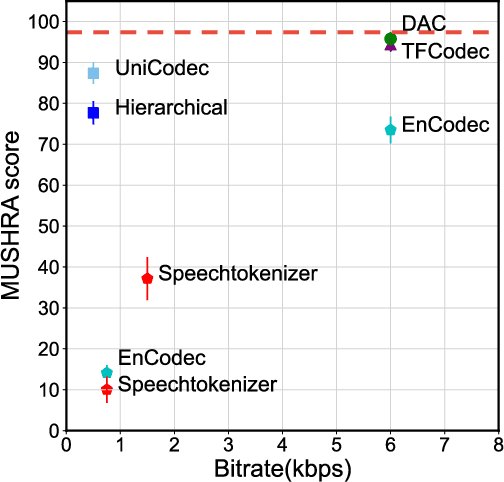

Current large speech language models are mainly based on semantic tokens from discretization of self-supervised learned representations and acoustic tokens from a neural codec, following a semantic-modeling and acoustic-synthesis paradigm. However, semantic tokens discard paralinguistic attributes of speakers that is important for natural spoken communication, while prompt-based acoustic synthesis from semantic tokens has limits in recovering paralinguistic details and suffers from robustness issues, especially when there are domain gaps between the prompt and the target. This paper unifies two types of tokens and proposes the UniCodec, a universal speech token learning that encapsulates all semantics of speech, including linguistic and paralinguistic information, into a compact and semantically-disentangled unified token. Such a unified token can not only benefit speech language models in understanding with paralinguistic hints but also help speech generation with high-quality output. A low-bitrate neural codec is leveraged to learn such disentangled discrete representations at global and local scales, with knowledge distilled from self-supervised learned features. Extensive evaluations on multilingual datasets demonstrate its effectiveness in generating natural, expressive and long-term consistent output quality with paralinguistic attributes well preserved in several speech processing tasks.