 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Formal Reasoning Capabilities of Large Language Models through Chomsky Hierarchy
Apr 03, 2026The formal reasoning capabilities of LLMs are crucial for advancing automated software engineering. However, existing benchmarks for LLMs lack systematic evaluation based on computation and complexity, leaving a critical gap in understanding their formal reasoning capabilities. Therefore, it is still unknown whether SOTA LLMs can grasp the structured, hierarchical complexity of formal languages as defined by Computation Theory. To address this, we introduce ChomskyBench, a benchmark for systematically evaluating LLMs through the lens of Chomsky Hierarchy. Unlike prior work that uses vectorized classification for neural networks, ChomskyBench is the first to combine full Chomsky Hierarchy coverage, process-trace evaluation via natural language, and deterministic symbolic verifiability. ChomskyBench is composed of a comprehensive suite of language recognition and generation tasks designed to test capabilities at each level. Extensive experiments indicate a clear performance stratification that correlates with the hierarchy's levels of complexity. Our analysis reveals a direct relationship where increasing task difficulty substantially impacts both inference length and performance. Furthermore, we find that while larger models and advanced inference methods offer notable relative gains, they face severe efficiency barriers: achieving practical reliability would require prohibitive computational costs, revealing that current limitations stem from inefficiency rather than absolute capability bounds. A time complexity analysis further indicates that LLMs are significantly less efficient than traditional algorithmic programs for these formal tasks. These results delineate the practical limits of current LLMs, highlight the indispensability of traditional software tools, and provide insights to guide the development of future LLMs with more powerful formal reasoning capabilities.
Think Anywhere in Code Generation
Apr 02, 2026Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
Baguan-TS: A Sequence-Native In-Context Learning Model for Time Series Forecasting with Covariates
Mar 18, 2026Transformers enable in-context learning (ICL) for rapid, gradient-free adaptation in time series forecasting, yet most ICL-style approaches rely on tabularized, hand-crafted features, while end-to-end sequence models lack inference-time adaptation. We bridge this gap with a unified framework, Baguan-TS, which integrates the raw-sequence representation learning with ICL, instantiated by a 3D Transformer that attends jointly over temporal, variable, and context axes. To make this high-capacity model practical, we tackle two key hurdles: (i) calibration and training stability, improved with a feature-agnostic, target-space retrieval-based local calibration; and (ii) output oversmoothing, mitigated via context-overfitting strategy. On public benchmark with covariates, Baguan-TS consistently outperforms established baselines, achieving the highest win rate and significant reductions in both point and probabilistic forecasting metrics. Further evaluations across diverse real-world energy datasets demonstrate its robustness, yielding substantial improvements.
Disco: Densely-overlapping Cell Instance Segmentation via Adjacency-aware Collaborative Coloring
Feb 05, 2026Accurate cell instance segmentation is foundational for digital pathology analysis. Existing methods based on contour detection and distance mapping still face significant challenges in processing complex and dense cellular regions. Graph coloring-based methods provide a new paradigm for this task, yet the effectiveness of this paradigm in real-world scenarios with dense overlaps and complex topologies has not been verified. Addressing this issue, we release a large-scale dataset GBC-FS 2025, which contains highly complex and dense sub-cellular nuclear arrangements. We conduct the first systematic analysis of the chromatic properties of cell adjacency graphs across four diverse datasets and reveal an important discovery: most real-world cell graphs are non-bipartite, with a high prevalence of odd-length cycles (predominantly triangles). This makes simple 2-coloring theory insufficient for handling complex tissues, while higher-chromaticity models would cause representational redundancy and optimization difficulties. Building on this observation of complex real-world contexts, we propose Disco (Densely-overlapping Cell Instance Segmentation via Adjacency-aware COllaborative Coloring), an adjacency-aware framework based on the "divide and conquer" principle. It uniquely combines a data-driven topological labeling strategy with a constrained deep learning system to resolve complex adjacency conflicts. First, "Explicit Marking" strategy transforms the topological challenge into a learnable classification task by recursively decomposing the cell graph and isolating a "conflict set." Second, "Implicit Disambiguation" mechanism resolves ambiguities in conflict regions by enforcing feature dissimilarity between different instances, enabling the model to learn separable feature representations.
KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?
Jan 19, 2026Large language models (LLMs) excel at general programming but struggle with domain-specific software development, necessitating domain specialization methods for LLMs to learn and utilize domain knowledge and data. However, existing domain-specific code benchmarks cannot evaluate the effectiveness of domain specialization methods, which focus on assessing what knowledge LLMs possess rather than how they acquire and apply new knowledge, lacking explicit knowledge corpora for developing domain specialization methods. To this end, we present KOCO-BENCH, a novel benchmark designed for evaluating domain specialization methods in real-world software development. KOCO-BENCH contains 6 emerging domains with 11 software frameworks and 25 projects, featuring curated knowledge corpora alongside multi-granularity evaluation tasks including domain code generation (from function-level to project-level with rigorous test suites) and domain knowledge understanding (via multiple-choice Q&A). Unlike previous benchmarks that only provide test sets for direct evaluation, KOCO-BENCH requires acquiring and applying diverse domain knowledge (APIs, rules, constraints, etc.) from knowledge corpora to solve evaluation tasks. Our evaluations reveal that KOCO-BENCH poses significant challenges to state-of-the-art LLMs. Even with domain specialization methods (e.g., SFT, RAG, kNN-LM) applied, improvements remain marginal. Best-performing coding agent, Claude Code, achieves only 34.2%, highlighting the urgent need for more effective domain specialization methods. We release KOCO-BENCH, evaluation code, and baselines to advance further research at https://github.com/jiangxxxue/KOCO-bench.
AirSpatialBot: A Spatially-Aware Aerial Agent for Fine-Grained Vehicle Attribute Recognization and Retrieval
Jan 04, 2026Despite notable advancements in remote sensing vision-language models (VLMs), existing models often struggle with spatial understanding, limiting their effectiveness in real-world applications. To push the boundaries of VLMs in remote sensing, we specifically address vehicle imagery captured by drones and introduce a spatially-aware dataset AirSpatial, which comprises over 206K instructions and introduces two novel tasks: Spatial Grounding and Spatial Question Answering. It is also the first remote sensing grounding dataset to provide 3DBB. To effectively leverage existing image understanding of VLMs to spatial domains, we adopt a two-stage training strategy comprising Image Understanding Pre-training and Spatial Understanding Fine-tuning. Utilizing this trained spatially-aware VLM, we develop an aerial agent, AirSpatialBot, which is capable of fine-grained vehicle attribute recognition and retrieval. By dynamically integrating task planning, image understanding, spatial understanding, and task execution capabilities, AirSpatialBot adapts to diverse query requirements. Experimental results validate the effectiveness of our approach, revealing the spatial limitations of existing VLMs while providing valuable insights. The model, code, and datasets will be released at https://github.com/VisionXLab/AirSpatialBot
DVGBench: Implicit-to-Explicit Visual Grounding Benchmark in UAV Imagery with Large Vision-Language Models
Jan 02, 2026Remote sensing (RS) large vision-language models (LVLMs) have shown strong promise across visual grounding (VG) tasks. However, existing RS VG datasets predominantly rely on explicit referring expressions-such as relative position, relative size, and color cues-thereby constraining performance on implicit VG tasks that require scenario-specific domain knowledge. This article introduces DVGBench, a high-quality implicit VG benchmark for drones, covering six major application scenarios: traffic, disaster, security, sport, social activity, and productive activity. Each object provides both explicit and implicit queries. Based on the dataset, we design DroneVG-R1, an LVLM that integrates the novel Implicit-to-Explicit Chain-of-Thought (I2E-CoT) within a reinforcement learning paradigm. This enables the model to take advantage of scene-specific expertise, converting implicit references into explicit ones and thus reducing grounding difficulty. Finally, an evaluation of mainstream models on both explicit and implicit VG tasks reveals substantial limitations in their reasoning capabilities. These findings provide actionable insights for advancing the reasoning capacity of LVLMs for drone-based agents. The code and datasets will be released at https://github.com/zytx121/DVGBench
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
A Survey on Code Generation with LLM-based Agents
Jul 31, 2025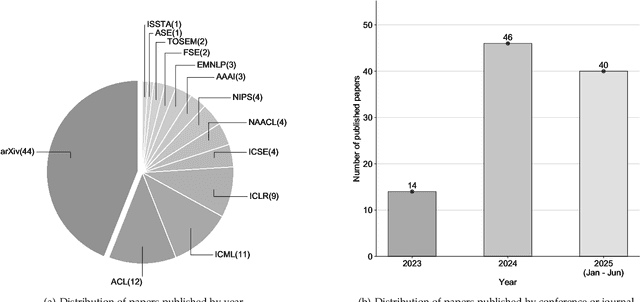
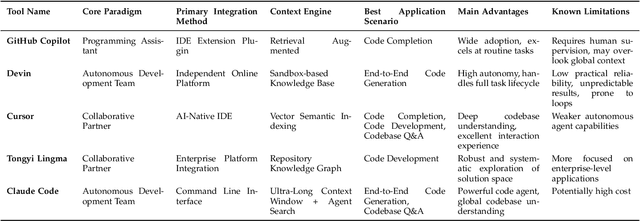
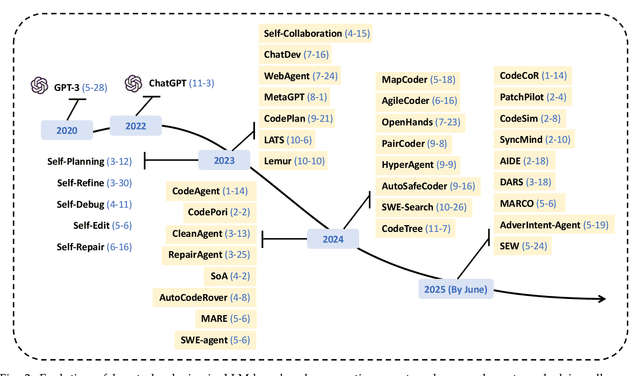
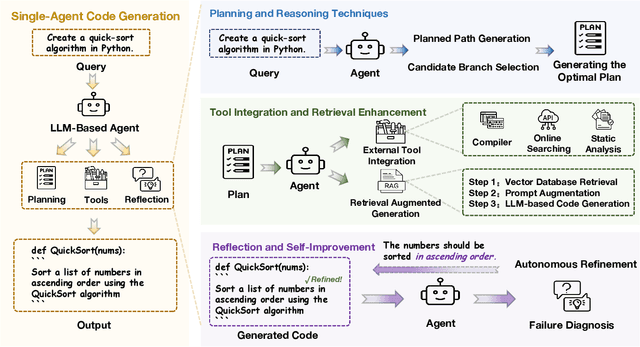
Code generation agents powered by large language models (LLMs) are revolutionizing the software development paradigm. Distinct from previous code generation techniques, code generation agents are characterized by three core features. 1) Autonomy: the ability to independently manage the entire workflow, from task decomposition to coding and debugging. 2) Expanded task scope: capabilities that extend beyond generating code snippets to encompass the full software development lifecycle (SDLC). 3) Enhancement of engineering practicality: a shift in research emphasis from algorithmic innovation toward practical engineering challenges, such as system reliability, process management, and tool integration. This domain has recently witnessed rapid development and an explosion in research, demonstrating significant application potential. This paper presents a systematic survey of the field of LLM-based code generation agents. We trace the technology's developmental trajectory from its inception and systematically categorize its core techniques, including both single-agent and multi-agent architectures. Furthermore, this survey details the applications of LLM-based agents across the full SDLC, summarizes mainstream evaluation benchmarks and metrics, and catalogs representative tools. Finally, by analyzing the primary challenges, we identify and propose several foundational, long-term research directions for the future work of the field.
Multi-objective Aligned Bidword Generation Model for E-commerce Search Advertising
Jun 04, 2025

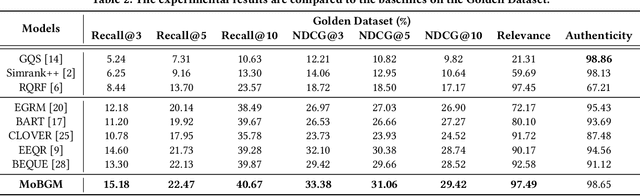

Retrieval systems primarily address the challenge of matching user queries with the most relevant advertisements, playing a crucial role in e-commerce search advertising. The diversity of user needs and expressions often produces massive long-tail queries that cannot be matched with merchant bidwords or product titles, which results in some advertisements not being recalled, ultimately harming user experience and search efficiency. Existing query rewriting research focuses on various methods such as query log mining, query-bidword vector matching, or generation-based rewriting. However, these methods often fail to simultaneously optimize the relevance and authenticity of the user's original query and rewrite and maximize the revenue potential of recalled ads. In this paper, we propose a Multi-objective aligned Bidword Generation Model (MoBGM), which is composed of a discriminator, generator, and preference alignment module, to address these challenges. To simultaneously improve the relevance and authenticity of the query and rewrite and maximize the platform revenue, we design a discriminator to optimize these key objectives. Using the feedback signal of the discriminator, we train a multi-objective aligned bidword generator that aims to maximize the combined effect of the three objectives. Extensive offline and online experiments show that our proposed algorithm significantly outperforms the state of the art. After deployment, the algorithm has created huge commercial value for the platform, further verifying its feasibility and robustness.