 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformers Have the Ability for Periodicity Generalization?
Jan 30, 2026Large language models (LLMs) based on the Transformer have demonstrated strong performance across diverse tasks. However, current models still exhibit substantial limitations in out-of-distribution (OOD) generalization compared with humans. We investigate this gap through periodicity, one of the basic OOD scenarios. Periodicity captures invariance amid variation. Periodicity generalization represents a model's ability to extract periodic patterns from training data and generalize to OOD scenarios. We introduce a unified interpretation of periodicity from the perspective of abstract algebra and reasoning, including both single and composite periodicity, to explain why Transformers struggle to generalize periodicity. Then we construct Coper about composite periodicity, a controllable generative benchmark with two OOD settings, Hollow and Extrapolation. Experiments reveal that periodicity generalization in Transformers is limited, where models can memorize periodic data during training, but cannot generalize to unseen composite periodicity. We release the source code to support future research.
KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?
Jan 19, 2026Large language models (LLMs) excel at general programming but struggle with domain-specific software development, necessitating domain specialization methods for LLMs to learn and utilize domain knowledge and data. However, existing domain-specific code benchmarks cannot evaluate the effectiveness of domain specialization methods, which focus on assessing what knowledge LLMs possess rather than how they acquire and apply new knowledge, lacking explicit knowledge corpora for developing domain specialization methods. To this end, we present KOCO-BENCH, a novel benchmark designed for evaluating domain specialization methods in real-world software development. KOCO-BENCH contains 6 emerging domains with 11 software frameworks and 25 projects, featuring curated knowledge corpora alongside multi-granularity evaluation tasks including domain code generation (from function-level to project-level with rigorous test suites) and domain knowledge understanding (via multiple-choice Q&A). Unlike previous benchmarks that only provide test sets for direct evaluation, KOCO-BENCH requires acquiring and applying diverse domain knowledge (APIs, rules, constraints, etc.) from knowledge corpora to solve evaluation tasks. Our evaluations reveal that KOCO-BENCH poses significant challenges to state-of-the-art LLMs. Even with domain specialization methods (e.g., SFT, RAG, kNN-LM) applied, improvements remain marginal. Best-performing coding agent, Claude Code, achieves only 34.2%, highlighting the urgent need for more effective domain specialization methods. We release KOCO-BENCH, evaluation code, and baselines to advance further research at https://github.com/jiangxxxue/KOCO-bench.
Weights to Code: Extracting Interpretable Algorithms from the Discrete Transformer
Jan 09, 2026Algorithm extraction aims to synthesize executable programs directly from models trained on specific algorithmic tasks, enabling de novo algorithm discovery without relying on human-written code. However, extending this paradigm to Transformer is hindered by superposition, where entangled features encoded in overlapping directions obstruct the extraction of symbolic expressions. In this work, we propose the Discrete Transformer, an architecture explicitly engineered to bridge the gap between continuous representations and discrete symbolic logic. By enforcing a strict functional disentanglement, which constrains Numerical Attention to information routing and Numerical MLP to element-wise arithmetic, and employing temperature-annealed sampling, our method effectively facilitates the extraction of human-readable programs. Empirically, the Discrete Transformer not only achieves performance comparable to RNN-based baselines but crucially extends interpretability to continuous variable domains. Moreover, our analysis of the annealing process shows that the efficient discrete search undergoes a clear phase transition from exploration to exploitation. We further demonstrate that our method enables fine-grained control over synthesized programs by imposing inductive biases. Collectively, these findings establish the Discrete Transformer as a robust framework for demonstration-free algorithm discovery, offering a rigorous pathway toward Transformer interpretability.
A Survey on Code Generation with LLM-based Agents
Jul 31, 2025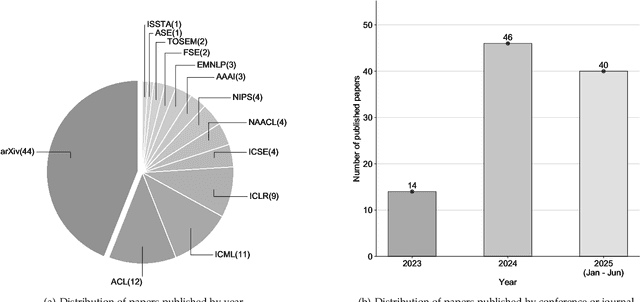
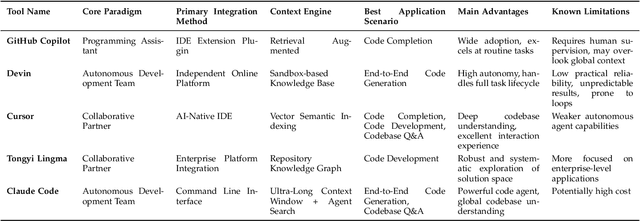
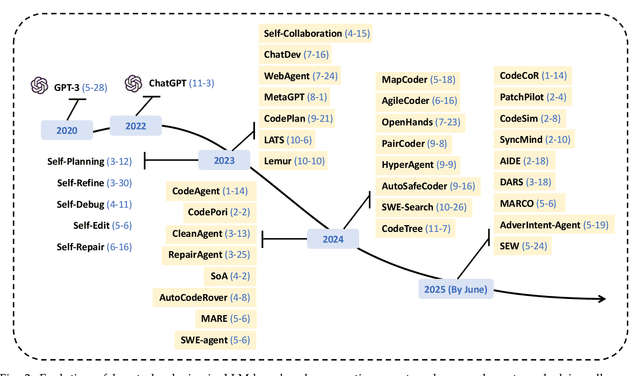
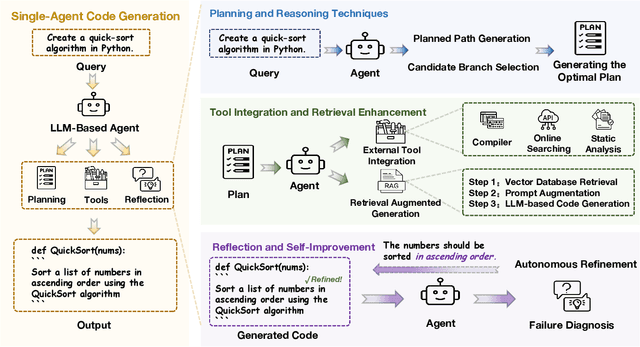
Code generation agents powered by large language models (LLMs) are revolutionizing the software development paradigm. Distinct from previous code generation techniques, code generation agents are characterized by three core features. 1) Autonomy: the ability to independently manage the entire workflow, from task decomposition to coding and debugging. 2) Expanded task scope: capabilities that extend beyond generating code snippets to encompass the full software development lifecycle (SDLC). 3) Enhancement of engineering practicality: a shift in research emphasis from algorithmic innovation toward practical engineering challenges, such as system reliability, process management, and tool integration. This domain has recently witnessed rapid development and an explosion in research, demonstrating significant application potential. This paper presents a systematic survey of the field of LLM-based code generation agents. We trace the technology's developmental trajectory from its inception and systematically categorize its core techniques, including both single-agent and multi-agent architectures. Furthermore, this survey details the applications of LLM-based agents across the full SDLC, summarizes mainstream evaluation benchmarks and metrics, and catalogs representative tools. Finally, by analyzing the primary challenges, we identify and propose several foundational, long-term research directions for the future work of the field.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
SATURN: SAT-based Reinforcement Learning to Unleash Language Model Reasoning
May 22, 2025How to design reinforcement learning (RL) tasks that effectively unleash the reasoning capability of large language models (LLMs) remains an open question. Existing RL tasks (e.g., math, programming, and constructing reasoning tasks) suffer from three key limitations: (1) Scalability. They rely heavily on human annotation or expensive LLM synthesis to generate sufficient training data. (2) Verifiability. LLMs' outputs are hard to verify automatically and reliably. (3) Controllable Difficulty. Most tasks lack fine-grained difficulty control, making it hard to train LLMs to develop reasoning ability from easy to hard. To address these limitations, we propose Saturn, a SAT-based RL framework that uses Boolean Satisfiability (SAT) problems to train and evaluate LLM reasoning. Saturn enables scalable task construction, rule-based verification, and precise difficulty control. Saturn designs a curriculum learning pipeline that continuously improves LLMs' reasoning capability by constructing SAT tasks of increasing difficulty and training LLMs from easy to hard. To ensure stable training, we design a principled mechanism to control difficulty transitions. We introduce Saturn-2.6k, a dataset of 2,660 SAT problems with varying difficulty. It supports the evaluation of how LLM reasoning changes with problem difficulty. We apply Saturn to DeepSeek-R1-Distill-Qwen and obtain Saturn-1.5B and Saturn-7B. We achieve several notable results: (1) On SAT problems, Saturn-1.5B and Saturn-7B achieve average pass@3 improvements of +14.0 and +28.1, respectively. (2) On math and programming tasks, Saturn-1.5B and Saturn-7B improve average scores by +4.9 and +1.8 on benchmarks (e.g., AIME, LiveCodeBench). (3) Compared to the state-of-the-art (SOTA) approach in constructing RL tasks, Saturn achieves further improvements of +8.8%. We release the source code, data, and models to support future research.
FANformer: Improving Large Language Models Through Effective Periodicity Modeling
Feb 28, 2025Periodicity, as one of the most important basic characteristics, lays the foundation for facilitating structured knowledge acquisition and systematic cognitive processes within human learning paradigms. However, the potential flaws of periodicity modeling in Transformer affect the learning efficiency and establishment of underlying principles from data for large language models (LLMs) built upon it. In this paper, we demonstrate that integrating effective periodicity modeling can improve the learning efficiency and performance of LLMs. We introduce FANformer, which integrates Fourier Analysis Network (FAN) into attention mechanism to achieve efficient periodicity modeling, by modifying the feature projection process of attention mechanism. Extensive experimental results on language modeling show that FANformer consistently outperforms Transformer when scaling up model size and training tokens, underscoring its superior learning efficiency. To further validate the effectiveness of FANformer, we pretrain a FANformer-1B on 1 trillion tokens. FANformer-1B exhibits marked improvements on downstream tasks compared to open-source LLMs with similar model parameters or training tokens. The results position FANformer as an effective and promising architecture for advancing LLMs.
FAN: Fourier Analysis Networks
Oct 03, 2024



Despite the remarkable success achieved by neural networks, particularly those represented by MLP and Transformer, we reveal that they exhibit potential flaws in the modeling and reasoning of periodicity, i.e., they tend to memorize the periodic data rather than genuinely understanding the underlying principles of periodicity. However, periodicity is a crucial trait in various forms of reasoning and generalization, underpinning predictability across natural and engineered systems through recurring patterns in observations. In this paper, we propose FAN, a novel network architecture based on Fourier Analysis, which empowers the ability to efficiently model and reason about periodic phenomena. By introducing Fourier Series, the periodicity is naturally integrated into the structure and computational processes of the neural network, thus achieving a more accurate expression and prediction of periodic patterns. As a promising substitute to multi-layer perceptron (MLP), FAN can seamlessly replace MLP in various models with fewer parameters and FLOPs. Through extensive experiments, we demonstrate the effectiveness of FAN in modeling and reasoning about periodic functions, and the superiority and generalizability of FAN across a range of real-world tasks, including symbolic formula representation, time series forecasting, and language modeling.
Self-Edit: Fault-Aware Code Editor for Code Generation
May 06, 2023Large language models (LLMs) have demonstrated an impressive ability to generate codes on competitive programming tasks. However, with limited sample numbers, LLMs still suffer from poor accuracy. Inspired by the process of human programming, we propose a generate-and-edit approach that utilizes execution results of the generated code from LLMs to improve the code quality on the competitive programming task. We execute the generated code on the example test case provided in the question and wrap execution results into a supplementary comment. Utilizing this comment as guidance, our fault-aware code editor is employed to correct errors in the generated code. We perform extensive evaluations across two competitive programming datasets with nine different LLMs. Compared to directly generating from LLMs, our approach can improve the average of pass@1 by 89\% on APPS-dev, 31\% on APPS-test, and 48\% on HumanEval over nine popular code generation LLMs with parameter sizes ranging from 110M to 175B. Compared to other post-processing methods, our method demonstrates superior accuracy and efficiency.
Implant Global and Local Hierarchy Information to Sequence based Code Representation Models
Mar 14, 2023Source code representation with deep learning techniques is an important research field. There have been many studies that learn sequential or structural information for code representation. But sequence-based models and non-sequence-models both have their limitations. Researchers attempt to incorporate structural information to sequence-based models, but they only mine part of token-level hierarchical structure information. In this paper, we analyze how the complete hierarchical structure influences the tokens in code sequences and abstract this influence as a property of code tokens called hierarchical embedding. The hierarchical embedding is further divided into statement-level global hierarchy and token-level local hierarchy. Furthermore, we propose the Hierarchy Transformer (HiT), a simple but effective sequence model to incorporate the complete hierarchical embeddings of source code into a Transformer model. We demonstrate the effectiveness of hierarchical embedding on learning code structure with an experiment on variable scope detection task. Further evaluation shows that HiT outperforms SOTA baseline models and show stable training efficiency on three source code-related tasks involving classification and generation tasks across 8 different datasets.