 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Forecasts: Bridging Modality Gap with Temporal Evolution Semantic Space
Mar 16, 2026Incorporating textual information into time-series forecasting holds promise for addressing event-driven non-stationarity; however, a fundamental modality gap hinders effective fusion: textual descriptions express temporal impacts implicitly and qualitatively, whereas forecasting models rely on explicit and quantitative signals. Through controlled semi-synthetic experiments, we show that existing methods over-attend to redundant tokens and struggle to reliably translate textual semantics into usable numerical cues. To bridge this gap, we propose TESS, which introduces a Temporal Evolution Semantic Space as an intermediate bottleneck between modalities. This space consists of interpretable, numerically grounded temporal primitives (mean shift, volatility, shape, and lag) extracted from text by an LLM via structured prompting and filtered through confidence-aware gating. Experiments on four real-world datasets demonstrate up to a 29 percent reduction in forecasting error compared to state-of-the-art unimodal and multimodal baselines. The code will be released after acceptance.
Accurate and Efficient Multivariate Time Series Forecasting via Offline Clustering
May 09, 2025Accurate and efficient multivariate time series (MTS) forecasting is essential for applications such as traffic management and weather prediction, which depend on capturing long-range temporal dependencies and interactions between entities. Existing methods, particularly those based on Transformer architectures, compute pairwise dependencies across all time steps, leading to a computational complexity that scales quadratically with the length of the input. To overcome these challenges, we introduce the Forecaster with Offline Clustering Using Segments (FOCUS), a novel approach to MTS forecasting that simplifies long-range dependency modeling through the use of prototypes extracted via offline clustering. These prototypes encapsulate high-level events in the real-world system underlying the data, summarizing the key characteristics of similar time segments. In the online phase, FOCUS dynamically adapts these patterns to the current input and captures dependencies between the input segment and high-level events, enabling both accurate and efficient forecasting. By identifying prototypes during the offline clustering phase, FOCUS reduces the computational complexity of modeling long-range dependencies in the online phase to linear scaling. Extensive experiments across diverse benchmarks demonstrate that FOCUS achieves state-of-the-art accuracy while significantly reducing computational costs.
FANformer: Improving Large Language Models Through Effective Periodicity Modeling
Feb 28, 2025Periodicity, as one of the most important basic characteristics, lays the foundation for facilitating structured knowledge acquisition and systematic cognitive processes within human learning paradigms. However, the potential flaws of periodicity modeling in Transformer affect the learning efficiency and establishment of underlying principles from data for large language models (LLMs) built upon it. In this paper, we demonstrate that integrating effective periodicity modeling can improve the learning efficiency and performance of LLMs. We introduce FANformer, which integrates Fourier Analysis Network (FAN) into attention mechanism to achieve efficient periodicity modeling, by modifying the feature projection process of attention mechanism. Extensive experimental results on language modeling show that FANformer consistently outperforms Transformer when scaling up model size and training tokens, underscoring its superior learning efficiency. To further validate the effectiveness of FANformer, we pretrain a FANformer-1B on 1 trillion tokens. FANformer-1B exhibits marked improvements on downstream tasks compared to open-source LLMs with similar model parameters or training tokens. The results position FANformer as an effective and promising architecture for advancing LLMs.
AutoSTF: Decoupled Neural Architecture Search for Cost-Effective Automated Spatio-Temporal Forecasting
Sep 25, 2024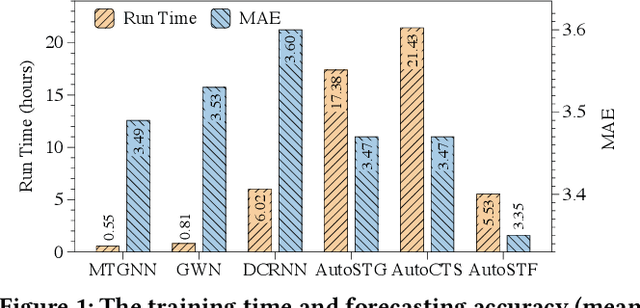



Spatio-temporal forecasting is a critical component of various smart city applications, such as transportation optimization, energy management, and socio-economic analysis. Recently, several automated spatio-temporal forecasting methods have been proposed to automatically search the optimal neural network architecture for capturing complex spatio-temporal dependencies. However, the existing automated approaches suffer from expensive neural architecture search overhead, which hinders their practical use and the further exploration of diverse spatio-temporal operators in a finer granularity. In this paper, we propose AutoSTF, a decoupled automatic neural architecture search framework for cost-effective automated spatio-temporal forecasting. From the efficiency perspective, we first decouple the mixed search space into temporal space and spatial space and respectively devise representation compression and parameter-sharing schemes to mitigate the parameter explosion. The decoupled spatio-temporal search not only expedites the model optimization process but also leaves new room for more effective spatio-temporal dependency modeling. From the effectiveness perspective, we propose a multi-patch transfer module to jointly capture multi-granularity temporal dependencies and extend the spatial search space to enable finer-grained layer-wise spatial dependency search. Extensive experiments on eight datasets demonstrate the superiority of AutoSTF in terms of both accuracy and efficiency. Specifically, our proposed method achieves up to 13.48x speed-up compared to state-of-the-art automatic spatio-temporal forecasting methods while maintaining the best forecasting accuracy.
Enhancing Spatio-temporal Quantile Forecasting with Curriculum Learning: Lessons Learned
Jun 18, 2024



Training models on spatio-temporal (ST) data poses an open problem due to the complicated and diverse nature of the data itself, and it is challenging to ensure the model's performance directly trained on the original ST data. While limiting the variety of training data can make training easier, it can also lead to a lack of knowledge and information for the model, resulting in a decrease in performance. To address this challenge, we presented an innovative paradigm that incorporates three separate forms of curriculum learning specifically targeting from spatial, temporal, and quantile perspectives. Furthermore, our framework incorporates a stacking fusion module to combine diverse information from three types of curriculum learning, resulting in a strong and thorough learning process. We demonstrated the effectiveness of this framework with extensive empirical evaluations, highlighting its better performance in addressing complex ST challenges. We provided thorough ablation studies to investigate the effectiveness of our curriculum and to explain how it contributes to the improvement of learning efficiency on ST data.
Heterogeneity-Informed Meta-Parameter Learning for Spatiotemporal Time Series Forecasting
May 17, 2024



Spatiotemporal time series forecasting plays a key role in a wide range of real-world applications. While significant progress has been made in this area, fully capturing and leveraging spatiotemporal heterogeneity remains a fundamental challenge. Therefore, we propose a novel Heterogeneity-Informed Meta-Parameter Learning scheme. Specifically, our approach implicitly captures spatiotemporal heterogeneity through learning spatial and temporal embeddings, which can be viewed as a clustering process. Then, a novel spatiotemporal meta-parameter learning paradigm is proposed to learn spatiotemporal-specific parameters from meta-parameter pools, which is informed by the captured heterogeneity. Based on these ideas, we develop a Heterogeneity-Informed Spatiotemporal Meta-Network (HimNet) for spatiotemporal time series forecasting. Extensive experiments on five widely-used benchmarks demonstrate our method achieves state-of-the-art performance while exhibiting superior interpretability. Our code is available at https://github.com/XDZhelheim/HimNet.
The Bigger the Better? Rethinking the Effective Model Scale in Long-term Time Series Forecasting
Feb 03, 2024
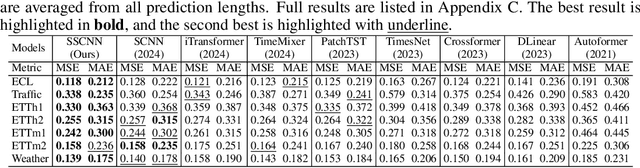
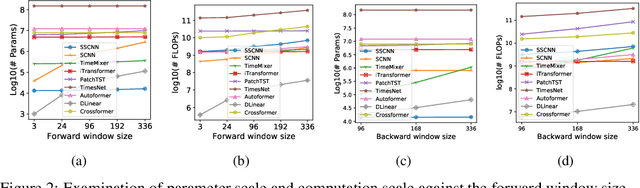
Long-term time series forecasting (LTSF) represents a critical frontier in time series analysis, distinguished by its focus on extensive input sequences, in contrast to the constrained lengths typical of traditional approaches. While longer sequences inherently convey richer information, potentially enhancing predictive precision, prevailing techniques often respond by escalating model complexity. These intricate models can inflate into millions of parameters, incorporating parameter-intensive elements like positional encodings, feed-forward networks and self-attention mechanisms. This complexity, however, leads to prohibitive model scale, particularly given the time series data's semantic simplicity. Motivated by the pursuit of parsimony, our research employs conditional correlation and auto-correlation as investigative tools, revealing significant redundancies within the input data. Leveraging these insights, we introduce the HDformer, a lightweight Transformer variant enhanced with hierarchical decomposition. This novel architecture not only inverts the prevailing trend toward model expansion but also accomplishes precise forecasting with drastically fewer computations and parameters. Remarkably, HDformer outperforms existing state-of-the-art LTSF models, while requiring over 99\% fewer parameters. Through this work, we advocate a paradigm shift in LTSF, emphasizing the importance to tailor the model to the inherent dynamics of time series data-a timely reminder that in the realm of LTSF, bigger is not invariably better.
Spatio-Temporal-Decoupled Masked Pre-training for Traffic Forecasting
Dec 01, 2023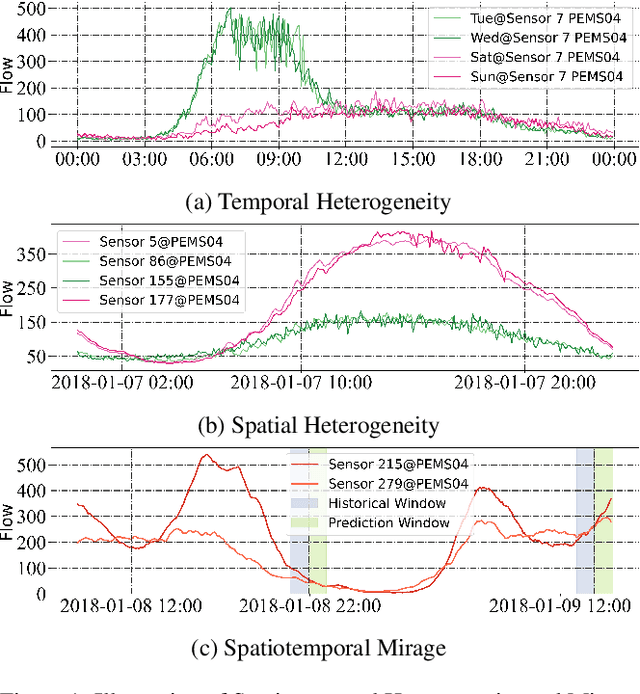

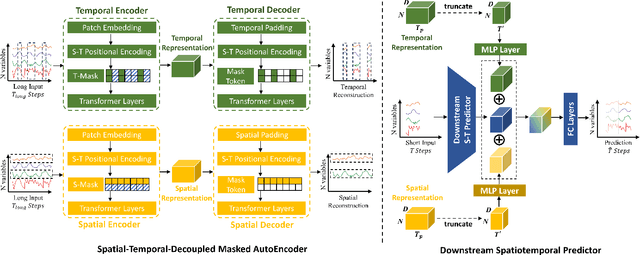
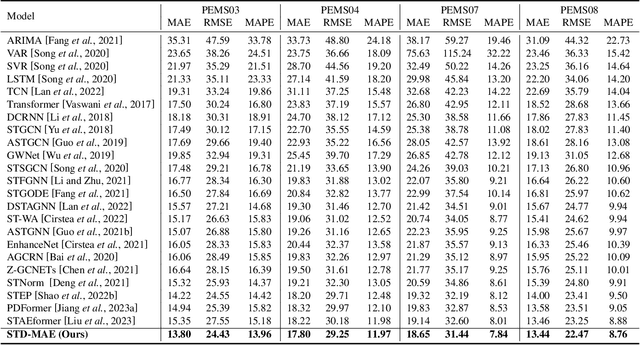
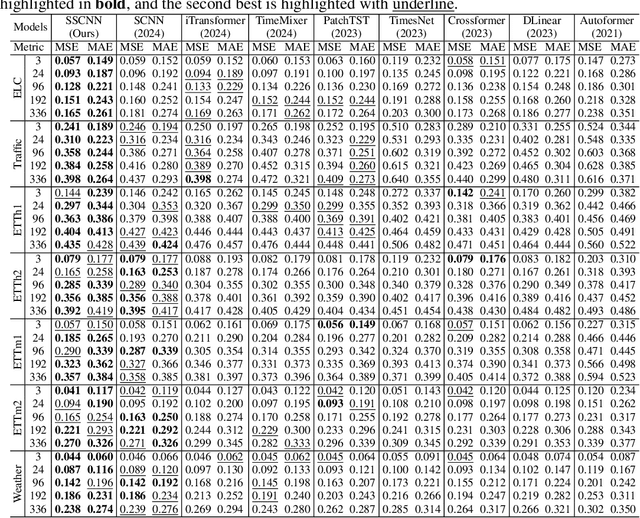
Accurate forecasting of multivariate traffic flow time series remains challenging due to substantial spatio-temporal heterogeneity and complex long-range correlative patterns. To address this, we propose Spatio-Temporal-Decoupled Masked Pre-training (STD-MAE), a novel framework that employs masked autoencoders to learn and encode complex spatio-temporal dependencies via pre-training. Specifically, we use two decoupled masked autoencoders to reconstruct the traffic data along spatial and temporal axes using a self-supervised pre-training approach. These mask reconstruction mechanisms capture the long-range correlations in space and time separately. The learned hidden representations are then used to augment the downstream spatio-temporal traffic predictor. A series of quantitative and qualitative evaluations on four widely-used traffic benchmarks (PEMS03, PEMS04, PEMS07, and PEMS08) are conducted to verify the state-of-the-art performance, with STD-MAE explicitly enhancing the downstream spatio-temporal models' ability to capture long-range intricate spatial and temporal patterns. Codes are available at https://github.com/Jimmy-7664/STD_MAE.
STAEformer: Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting
Aug 26, 2023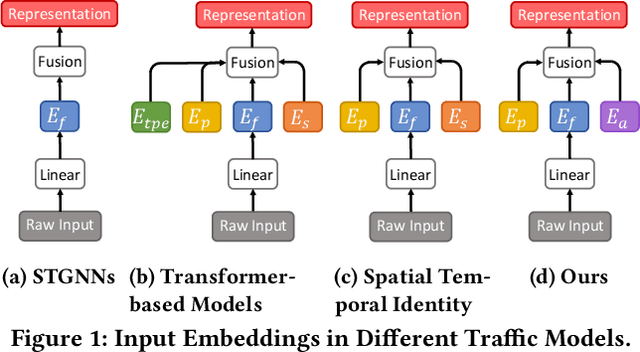
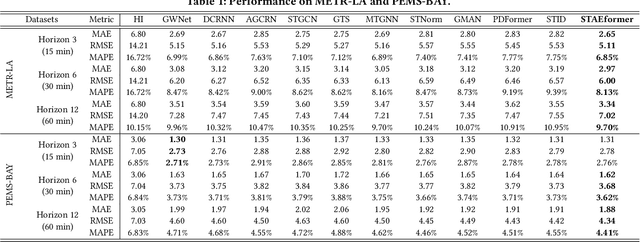
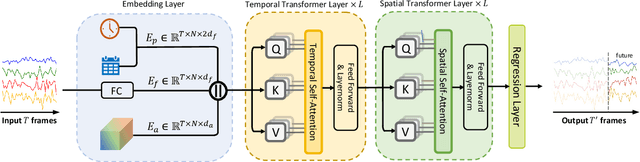
With the rapid development of the Intelligent Transportation System (ITS), accurate traffic forecasting has emerged as a critical challenge. The key bottleneck lies in capturing the intricate spatio-temporal traffic patterns. In recent years, numerous neural networks with complicated architectures have been proposed to address this issue. However, the advancements in network architectures have encountered diminishing performance gains. In this study, we present a novel component called spatio-temporal adaptive embedding that can yield outstanding results with vanilla transformers. Our proposed Spatio-Temporal Adaptive Embedding transformer (STAEformer) achieves state-of-the-art performance on five real-world traffic forecasting datasets. Further experiments demonstrate that spatio-temporal adaptive embedding plays a crucial role in traffic forecasting by effectively capturing intrinsic spatio-temporal relations and chronological information in traffic time series.
Learning Gaussian Mixture Representations for Tensor Time Series Forecasting
Jun 07, 2023Tensor time series (TTS) data, a generalization of one-dimensional time series on a high-dimensional space, is ubiquitous in real-world scenarios, especially in monitoring systems involving multi-source spatio-temporal data (e.g., transportation demands and air pollutants). Compared to modeling time series or multivariate time series, which has received much attention and achieved tremendous progress in recent years, tensor time series has been paid less effort. Properly coping with the tensor time series is a much more challenging task, due to its high-dimensional and complex inner structure. In this paper, we develop a novel TTS forecasting framework, which seeks to individually model each heterogeneity component implied in the time, the location, and the source variables. We name this framework as GMRL, short for Gaussian Mixture Representation Learning. Experiment results on two real-world TTS datasets verify the superiority of our approach compared with the state-of-the-art baselines. Code and data are published on https://github.com/beginner-sketch/GMRL.