 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoB2G: A Large Language Model-Driven Agentic Framework For Automated Building-Grid Co-Simulation
Mar 27, 2026The growing availability of building operational data motivates the use of reinforcement learning (RL), which can learn control policies directly from data and cope with the complexity and uncertainty of large-scale building clusters. However, most existing simulation environments prioritize building-side performance metrics and lack systematic evaluation of grid-level impacts, while their experimental workflows still rely heavily on manual configuration and substantial programming expertise. Therefore, this paper proposes AutoB2G, an automated building-grid co-simulation framework that completes the entire simulation workflow solely based on natural-language task descriptions. The framework extends CityLearn V2 to support Building-to-Grid (B2G) interaction and adopts the large language model (LLM)-based SOCIA (Simulation Orchestration for Computational Intelligence with Agents) framework to automatically generate, execute, and iteratively refine the simulator. As LLMs lack prior knowledge of the implementation context of simulation functions, a codebase covering simulation configurations and functional modules is constructed and organized as a directed acyclic graph (DAG) to explicitly represent module dependencies and execution order, guiding the LLM to retrieve a complete executable path. Experimental results demonstrate that AutoB2G can effectively enable automated simulator implementations, coordinating B2G interactions to improve grid-side performance metrics.
S3LoRA: Safe Spectral Sharpness-Guided Pruning in Adaptation of Agent Planner
Aug 20, 2025Adapting Large Language Models (LLMs) using parameter-efficient fine-tuning (PEFT) techniques such as LoRA has enabled powerful capabilities in LLM-based agents. However, these adaptations can unintentionally compromise safety alignment, leading to unsafe or unstable behaviors, particularly in agent planning tasks. Existing safety-aware adaptation methods often require access to both base and instruction-tuned model checkpoints, which are frequently unavailable in practice, limiting their applicability. We propose S3LoRA (Safe Spectral Sharpness-Guided Pruning LoRA), a lightweight, data-free, and model-independent framework that mitigates safety risks in LoRA-adapted models by inspecting only the fine-tuned weight updates. We first introduce Magnitude-Aware Spherically Normalized SVD (MAS-SVD), which robustly analyzes the structural properties of LoRA updates while preserving global magnitude information. We then design the Spectral Sharpness Index (SSI), a sharpness-aware metric to detect layers with highly concentrated and potentially unsafe updates. These layers are pruned post-hoc to reduce risk without sacrificing task performance. Extensive experiments and ablation studies across agent planning and language generation tasks show that S3LoRA consistently improves safety metrics while maintaining or improving utility metrics and significantly reducing inference cost. These results establish S3LoRA as a practical and scalable solution for safely deploying LLM-based agents in real-world, resource-constrained, and safety-critical environments.
EMAC+: Embodied Multimodal Agent for Collaborative Planning with VLM+LLM
May 26, 2025Although LLMs demonstrate proficiency in several text-based reasoning and planning tasks, their implementation in robotics control is constrained by significant deficiencies: (1) LLM agents are designed to work mainly with textual inputs rather than visual conditions; (2) Current multimodal agents treat LLMs as static planners, which separates their reasoning from environment dynamics, resulting in actions that do not take domain-specific knowledge into account; and (3) LLMs are not designed to learn from visual interactions, which makes it harder for them to make better policies for specific domains. In this paper, we introduce EMAC+, an Embodied Multimodal Agent that collaboratively integrates LLM and VLM via a bidirectional training paradigm. Unlike existing methods, EMAC+ dynamically refines high-level textual plans generated by an LLM using real-time feedback from a VLM executing low-level visual control tasks. We address critical limitations of previous models by enabling the LLM to internalize visual environment dynamics directly through interactive experience, rather than relying solely on static symbolic mappings. Extensive experimental evaluations on ALFWorld and RT-1 benchmarks demonstrate that EMAC+ achieves superior task performance, robustness against noisy observations, and efficient learning. We also conduct thorough ablation studies and provide detailed analyses of success and failure cases.
Position: Towards a Responsible LLM-empowered Multi-Agent Systems
Feb 03, 2025



The rise of Agent AI and Large Language Model-powered Multi-Agent Systems (LLM-MAS) has underscored the need for responsible and dependable system operation. Tools like LangChain and Retrieval-Augmented Generation have expanded LLM capabilities, enabling deeper integration into MAS through enhanced knowledge retrieval and reasoning. However, these advancements introduce critical challenges: LLM agents exhibit inherent unpredictability, and uncertainties in their outputs can compound across interactions, threatening system stability. To address these risks, a human-centered design approach with active dynamic moderation is essential. Such an approach enhances traditional passive oversight by facilitating coherent inter-agent communication and effective system governance, allowing MAS to achieve desired outcomes more efficiently.
REVEAL-IT: REinforcement learning with Visibility of Evolving Agent poLicy for InTerpretability
Jun 20, 2024Understanding the agent's learning process, particularly the factors that contribute to its success or failure post-training, is crucial for comprehending the rationale behind the agent's decision-making process. Prior methods clarify the learning process by creating a structural causal model (SCM) or visually representing the distribution of value functions. Nevertheless, these approaches have constraints as they exclusively function in 2D-environments or with uncomplicated transition dynamics. Understanding the agent's learning process in complicated environments or tasks is more challenging. In this paper, we propose REVEAL-IT, a novel framework for explaining the learning process of an agent in complex environments. Initially, we visualize the policy structure and the agent's learning process for various training tasks. By visualizing these findings, we can understand how much a particular training task or stage affects the agent's performance in test. Then, a GNN-based explainer learns to highlight the most important section of the policy, providing a more clear and robust explanation of the agent's learning process. The experiments demonstrate that explanations derived from this framework can effectively help in the optimization of the
XXLTraffic: Expanding and Extremely Long Traffic Dataset for Ultra-Dynamic Forecasting Challenges
Jun 18, 2024Traffic forecasting is crucial for smart cities and intelligent transportation initiatives, where deep learning has made significant progress in modeling complex spatio-temporal patterns in recent years. However, current public datasets have limitations in reflecting the ultra-dynamic nature of real-world scenarios, characterized by continuously evolving infrastructures, varying temporal distributions, and temporal gaps due to sensor downtimes or changes in traffic patterns. These limitations inevitably restrict the practical applicability of existing traffic forecasting datasets. To bridge this gap, we present XXLTraffic, the largest available public traffic dataset with the longest timespan and increasing number of sensor nodes over the multiple years observed in the data, curated to support research in ultra-dynamic forecasting. Our benchmark includes both typical time-series forecasting settings with hourly and daily aggregated data and novel configurations that introduce gaps and down-sample the training size to better simulate practical constraints. We anticipate the new XXLTraffic will provide a fresh perspective for the time-series and traffic forecasting communities. It would also offer a robust platform for developing and evaluating models designed to tackle ultra-dynamic and extremely long forecasting problems. Our dataset supplements existing spatio-temporal data resources and leads to new research directions in this domain.
Enhancing Spatio-temporal Quantile Forecasting with Curriculum Learning: Lessons Learned
Jun 18, 2024



Training models on spatio-temporal (ST) data poses an open problem due to the complicated and diverse nature of the data itself, and it is challenging to ensure the model's performance directly trained on the original ST data. While limiting the variety of training data can make training easier, it can also lead to a lack of knowledge and information for the model, resulting in a decrease in performance. To address this challenge, we presented an innovative paradigm that incorporates three separate forms of curriculum learning specifically targeting from spatial, temporal, and quantile perspectives. Furthermore, our framework incorporates a stacking fusion module to combine diverse information from three types of curriculum learning, resulting in a strong and thorough learning process. We demonstrated the effectiveness of this framework with extensive empirical evaluations, highlighting its better performance in addressing complex ST challenges. We provided thorough ablation studies to investigate the effectiveness of our curriculum and to explain how it contributes to the improvement of learning efficiency on ST data.
CSS: Contrastive Semantic Similarity for Uncertainty Quantification of LLMs
Jun 05, 2024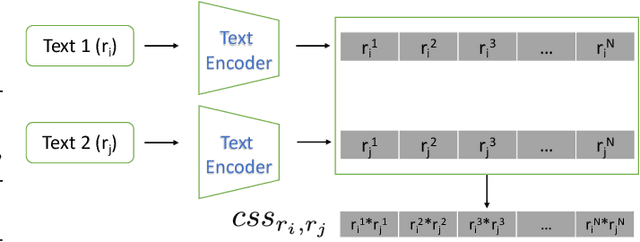
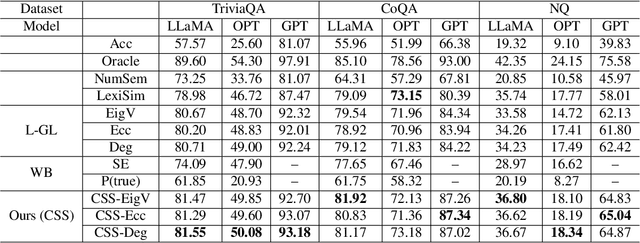
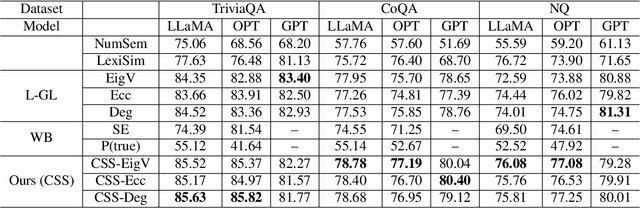
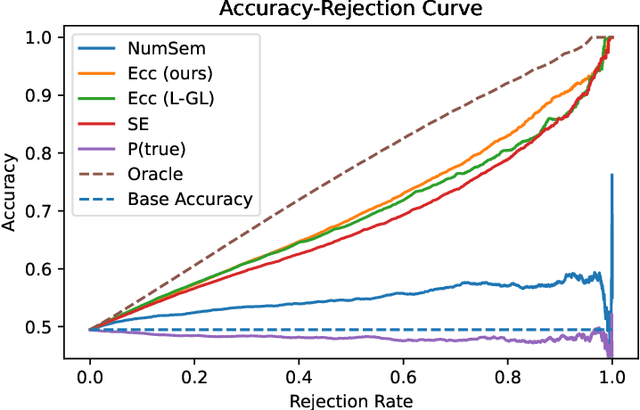
Despite the impressive capability of large language models (LLMs), knowing when to trust their generations remains an open challenge. The recent literature on uncertainty quantification of natural language generation (NLG) utilises a conventional natural language inference (NLI) classifier to measure the semantic dispersion of LLMs responses. These studies employ logits of NLI classifier for semantic clustering to estimate uncertainty. However, logits represent the probability of the predicted class and barely contain feature information for potential clustering. Alternatively, CLIP (Contrastive Language-Image Pre-training) performs impressively in extracting image-text pair features and measuring their similarity. To extend its usability, we propose Contrastive Semantic Similarity, the CLIP-based feature extraction module to obtain similarity features for measuring uncertainty for text pairs. We apply this method to selective NLG, which detects and rejects unreliable generations for better trustworthiness of LLMs. We conduct extensive experiments with three LLMs on several benchmark question-answering datasets with comprehensive evaluation metrics. Results show that our proposed method performs better in estimating reliable responses of LLMs than comparable baselines. Results show that our proposed method performs better in estimating reliable responses of LLMs than comparable baselines. The code are available at \url{https://github.com/AoShuang92/css_uq_llms}.
Large Language Models for Next Point-of-Interest Recommendation
Apr 19, 2024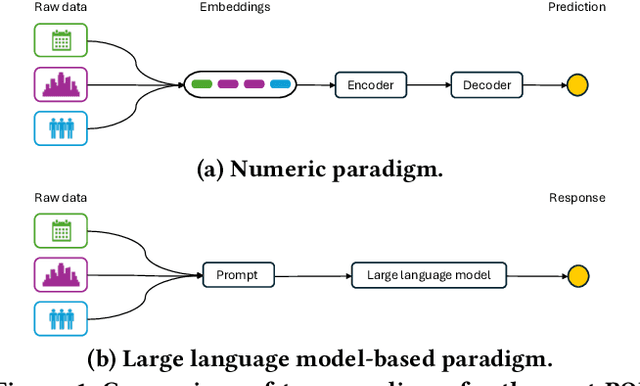
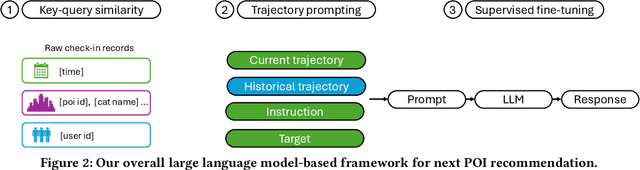

The next Point of Interest (POI) recommendation task is to predict users' immediate next POI visit given their historical data. Location-Based Social Network (LBSN) data, which is often used for the next POI recommendation task, comes with challenges. One frequently disregarded challenge is how to effectively use the abundant contextual information present in LBSN data. Previous methods are limited by their numerical nature and fail to address this challenge. In this paper, we propose a framework that uses pretrained Large Language Models (LLMs) to tackle this challenge. Our framework allows us to preserve heterogeneous LBSN data in its original format, hence avoiding the loss of contextual information. Furthermore, our framework is capable of comprehending the inherent meaning of contextual information due to the inclusion of commonsense knowledge. In experiments, we test our framework on three real-world LBSN datasets. Our results show that the proposed framework outperforms the state-of-the-art models in all three datasets. Our analysis demonstrates the effectiveness of the proposed framework in using contextual information as well as alleviating the commonly encountered cold-start and short trajectory problems.
Curriculum Reinforcement Learning via Morphology-Environment Co-Evolution
Sep 21, 2023Throughout long history, natural species have learned to survive by evolving their physical structures adaptive to the environment changes. In contrast, current reinforcement learning (RL) studies mainly focus on training an agent with a fixed morphology (e.g., skeletal structure and joint attributes) in a fixed environment, which can hardly generalize to changing environments or new tasks. In this paper, we optimize an RL agent and its morphology through ``morphology-environment co-evolution (MECE)'', in which the morphology keeps being updated to adapt to the changing environment, while the environment is modified progressively to bring new challenges and stimulate the improvement of the morphology. This leads to a curriculum to train generalizable RL, whose morphology and policy are optimized for different environments. Instead of hand-crafting the curriculum, we train two policies to automatically change the morphology and the environment. To this end, (1) we develop two novel and effective rewards for the two policies, which are solely based on the learning dynamics of the RL agent; (2) we design a scheduler to automatically determine when to change the environment and the morphology. In experiments on two classes of tasks, the morphology and RL policies trained via MECE exhibit significantly better generalization performance in unseen test environments than SOTA morphology optimization methods. Our ablation studies on the two MECE policies further show that the co-evolution between the morphology and environment is the key to the success.