 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSS: Contrastive Semantic Similarity for Uncertainty Quantification of LLMs
Jun 05, 2024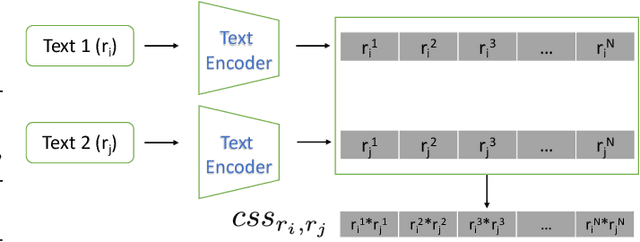
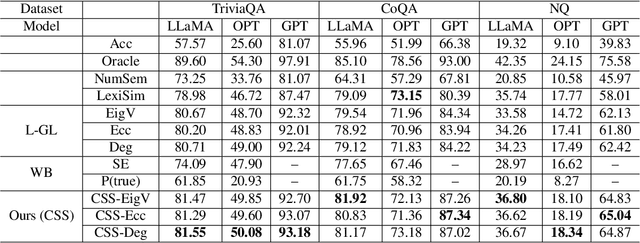
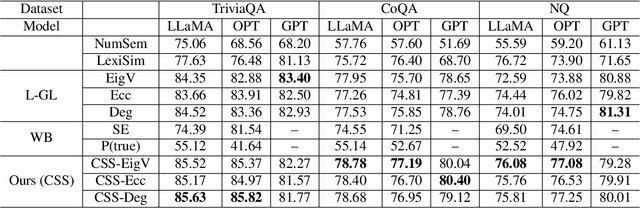
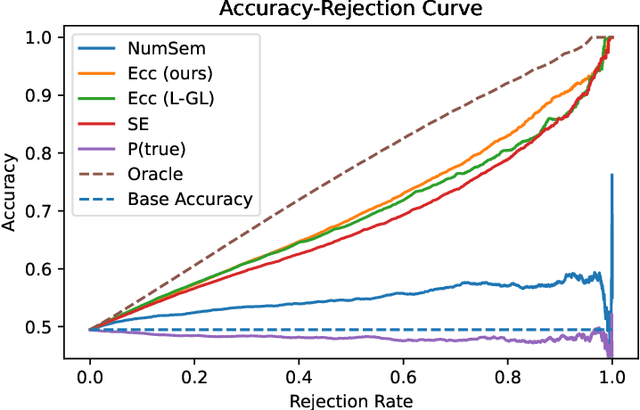
Despite the impressive capability of large language models (LLMs), knowing when to trust their generations remains an open challenge. The recent literature on uncertainty quantification of natural language generation (NLG) utilises a conventional natural language inference (NLI) classifier to measure the semantic dispersion of LLMs responses. These studies employ logits of NLI classifier for semantic clustering to estimate uncertainty. However, logits represent the probability of the predicted class and barely contain feature information for potential clustering. Alternatively, CLIP (Contrastive Language-Image Pre-training) performs impressively in extracting image-text pair features and measuring their similarity. To extend its usability, we propose Contrastive Semantic Similarity, the CLIP-based feature extraction module to obtain similarity features for measuring uncertainty for text pairs. We apply this method to selective NLG, which detects and rejects unreliable generations for better trustworthiness of LLMs. We conduct extensive experiments with three LLMs on several benchmark question-answering datasets with comprehensive evaluation metrics. Results show that our proposed method performs better in estimating reliable responses of LLMs than comparable baselines. Results show that our proposed method performs better in estimating reliable responses of LLMs than comparable baselines. The code are available at \url{https://github.com/AoShuang92/css_uq_llms}.
Textual Summarisation of Large Sets: Towards a General Approach
Jan 17, 2024We are developing techniques to generate summary descriptions of sets of objects. In this paper, we present and evaluate a rule-based NLG technique for summarising sets of bibliographical references in academic papers. This extends our previous work on summarising sets of consumer products and shows how our model generalises across these two very different domains.
Empirical Optimal Risk to Quantify Model Trustworthiness for Failure Detection
Aug 06, 2023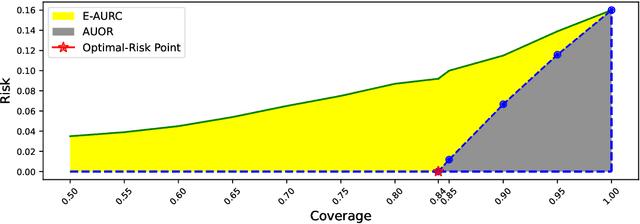
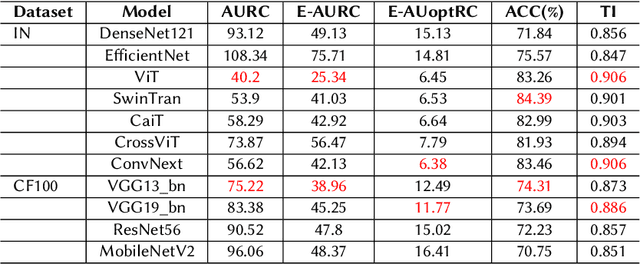
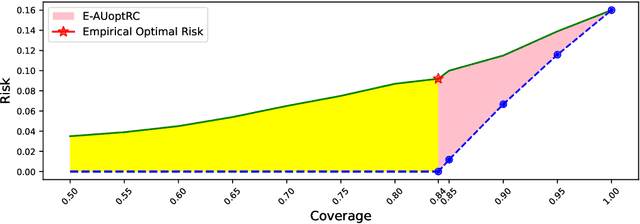
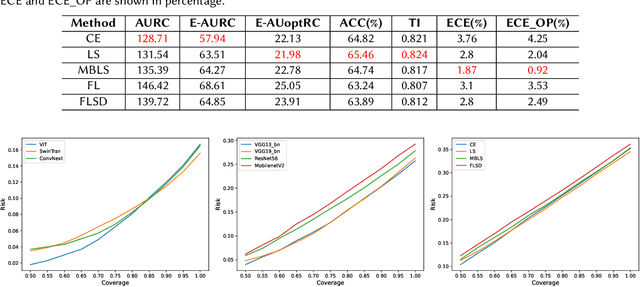
Failure detection (FD) in AI systems is a crucial safeguard for the deployment for safety-critical tasks. The common evaluation method of FD performance is the Risk-coverage (RC) curve, which reveals the trade-off between the data coverage rate and the performance on accepted data. One common way to quantify the RC curve by calculating the area under the RC curve. However, this metric does not inform on how suited any method is for FD, or what the optimal coverage rate should be. As FD aims to achieve higher performance with fewer data discarded, evaluating with partial coverage excluding the most uncertain samples is more intuitive and meaningful than full coverage. In addition, there is an optimal point in the coverage where the model could achieve ideal performance theoretically. We propose the Excess Area Under the Optimal RC Curve (E-AUoptRC), with the area in coverage from the optimal point to the full coverage. Further, the model performance at this optimal point can represent both model learning ability and calibration. We propose it as the Trust Index (TI), a complementary evaluation metric to the overall model accuracy. We report extensive experiments on three benchmark image datasets with ten variants of transformer and CNN models. Our results show that our proposed methods can better reflect the model trustworthiness than existing evaluation metrics. We further observe that the model with high overall accuracy does not always yield the high TI, which indicates the necessity of the proposed Trust Index as a complementary metric to the model overall accuracy. The code are available at \url{https://github.com/AoShuang92/optimal_risk}.
* 7 pages
Two Sides of Miscalibration: Identifying Over and Under-Confidence Prediction for Network Calibration
Aug 06, 2023Proper confidence calibration of deep neural networks is essential for reliable predictions in safety-critical tasks. Miscalibration can lead to model over-confidence and/or under-confidence; i.e., the model's confidence in its prediction can be greater or less than the model's accuracy. Recent studies have highlighted the over-confidence issue by introducing calibration techniques and demonstrated success on various tasks. However, miscalibration through under-confidence has not yet to receive much attention. In this paper, we address the necessity of paying attention to the under-confidence issue. We first introduce a novel metric, a miscalibration score, to identify the overall and class-wise calibration status, including being over or under-confident. Our proposed metric reveals the pitfalls of existing calibration techniques, where they often overly calibrate the model and worsen under-confident predictions. Then we utilize the class-wise miscalibration score as a proxy to design a calibration technique that can tackle both over and under-confidence. We report extensive experiments that show our proposed methods substantially outperforming existing calibration techniques. We also validate our proposed calibration technique on an automatic failure detection task with a risk-coverage curve, reporting that our methods improve failure detection as well as trustworthiness of the model. The code are available at \url{https://github.com/AoShuang92/miscalibration_TS}.
* 9 pages
Confidence-Aware Calibration and Scoring Functions for Curriculum Learning
Jan 29, 2023Despite the great success of state-of-the-art deep neural networks, several studies have reported models to be over-confident in predictions, indicating miscalibration. Label Smoothing has been proposed as a solution to the over-confidence problem and works by softening hard targets during training, typically by distributing part of the probability mass from a `one-hot' label uniformly to all other labels. However, neither model nor human confidence in a label are likely to be uniformly distributed in this manner, with some labels more likely to be confused than others. In this paper we integrate notions of model confidence and human confidence with label smoothing, respectively \textit{Model Confidence LS} and \textit{Human Confidence LS}, to achieve better model calibration and generalization. To enhance model generalization, we show how our model and human confidence scores can be successfully applied to curriculum learning, a training strategy inspired by learning of `easier to harder' tasks. A higher model or human confidence score indicates a more recognisable and therefore easier sample, and can therefore be used as a scoring function to rank samples in curriculum learning. We evaluate our proposed methods with four state-of-the-art architectures for image and text classification task, using datasets with multi-rater label annotations by humans. We report that integrating model or human confidence information in label smoothing and curriculum learning improves both model performance and model calibration. The code are available at \url{https://github.com/AoShuang92/Confidence_Calibration_CL}.
Extractive and Abstractive Sentence Labelling of Sentiment-bearing Topics
Aug 29, 2021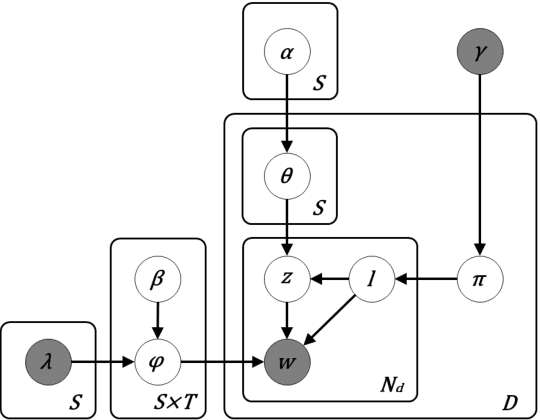
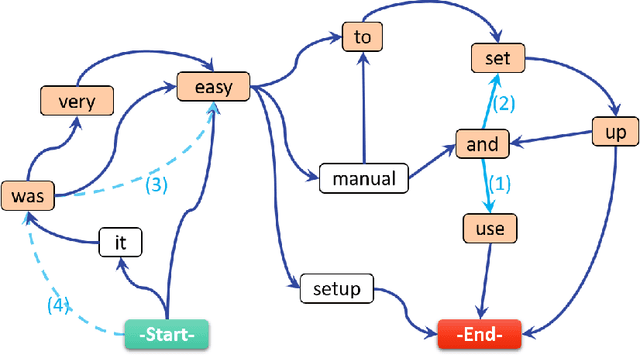

This paper tackles the problem of automatically labelling sentiment-bearing topics with descriptive sentence labels. We propose two approaches to the problem, one extractive and the other abstractive. Both approaches rely on a novel mechanism to automatically learn the relevance of each sentence in a corpus to sentiment-bearing topics extracted from that corpus. The extractive approach uses a sentence ranking algorithm for label selection which for the first time jointly optimises topic--sentence relevance as well as aspect--sentiment co-coverage. The abstractive approach instead addresses aspect--sentiment co-coverage by using sentence fusion to generate a sentential label that includes relevant content from multiple sentences. To our knowledge, we are the first to study the problem of labelling sentiment-bearing topics. Our experimental results on three real-world datasets show that both the extractive and abstractive approaches outperform four strong baselines in terms of facilitating topic understanding and interpretation. In addition, when comparing extractive and abstractive labels, our evaluation shows that our best performing abstractive method is able to provide more topic information coverage in fewer words, at the cost of generating less grammatical labels than the extractive method. We conclude that abstractive methods can effectively synthesise the rich information contained in sentiment-bearing topics.
Summarising Historical Text in Modern Languages
Jan 27, 2021
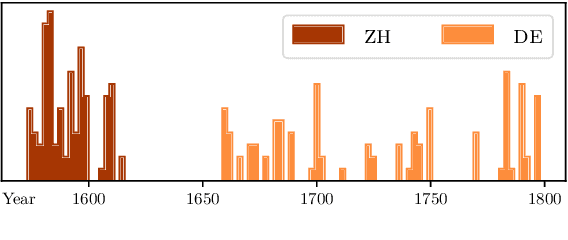
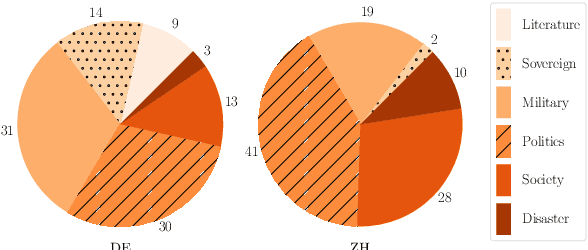
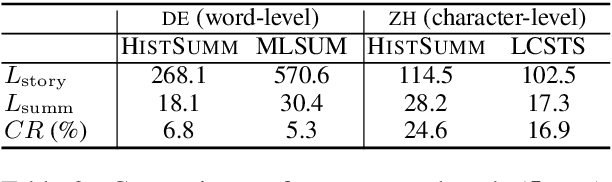
We introduce the task of historical text summarisation, where documents in historical forms of a language are summarised in the corresponding modern language. This is a fundamentally important routine to historians and digital humanities researchers but has never been automated. We compile a high-quality gold-standard text summarisation dataset, which consists of historical German and Chinese news from hundreds of years ago summarised in modern German or Chinese. Based on cross-lingual transfer learning techniques, we propose a summarisation model that can be trained even with no cross-lingual (historical to modern) parallel data, and further benchmark it against state-of-the-art algorithms. We report automatic and human evaluations that distinguish the historic to modern language summarisation task from standard cross-lingual summarisation (i.e., modern to modern language), highlight the distinctness and value of our dataset, and demonstrate that our transfer learning approach outperforms standard cross-lingual benchmarks on this task.
WordNet-feelings: A linguistic categorisation of human feelings
Nov 06, 2018


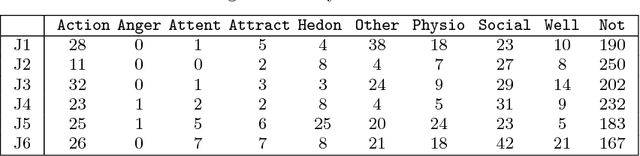
In this article, we present the first in depth linguistic study of human feelings. While there has been substantial research on incorporating some affective categories into linguistic analysis (e.g. sentiment, and to a lesser extent, emotion), the more diverse category of human feelings has thus far not been investigated. We surveyed the extensive interdisciplinary literature around feelings to construct a working definition of what constitutes a feeling and propose 9 broad categories of feeling. We identified potential feeling words based on their pointwise mutual information with morphological variants of the word `feel' in the Google n-gram corpus, and present a manual annotation exercise where 317 WordNet senses of one hundred of these words were categorised as `not a feeling' or as one of the 9 proposed categories of feeling. We then proceeded to annotate 11386 WordNet senses of all these words to create WordNet-feelings, a new affective dataset that identifies 3664 word senses as feelings, and associates each of these with one of the 9 categories of feeling. WordNet-feelings can be used in conjunction with other datasets such as SentiWordNet that annotate word senses with complementary affective properties such as valence and intensity.