 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Run-Length Encoding
Dec 28, 2023
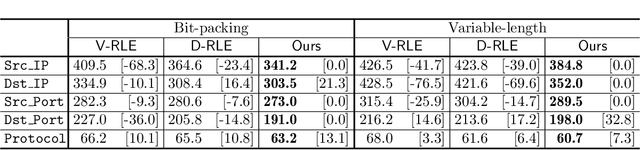
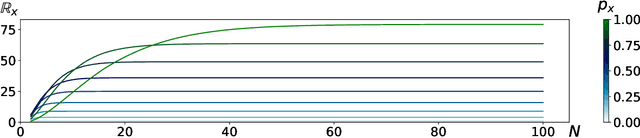

Run-Length Encoding (RLE) is one of the most fundamental tools in data compression. However, its compression power drops significantly if there lacks consecutive elements in the sequence. In extreme cases, the output of the encoder may require more space than the input (aka size inflation). To alleviate this issue, using combinatorics, we quantify RLE's space savings for a given input distribution. With this insight, we develop the first algorithm that automatically identifies suitable symbols, then selectively encodes these symbols with RLE while directly storing the others without RLE. Through experiments on real-world datasets of various modalities, we empirically validate that our method, which maintains RLE's efficiency advantage, can effectively mitigate the size inflation dilemma.
PTVD: A Large-Scale Plot-Oriented Multimodal Dataset Based on Television Dramas
Jun 26, 2023Art forms such as movies and television (TV) dramas are reflections of the real world, which have attracted much attention from the multimodal learning community recently. However, existing corpora in this domain share three limitations: (1) annotated in a scene-oriented fashion, they ignore the coherence within plots; (2) their text lacks empathy and seldom mentions situational context; (3) their video clips fail to cover long-form relationship due to short duration. To address these fundamental issues, using 1,106 TV drama episodes and 24,875 informative plot-focused sentences written by professionals, with the help of 449 human annotators, we constructed PTVD, the first plot-oriented multimodal dataset in the TV domain. It is also the first non-English dataset of its kind. Additionally, PTVD contains more than 26 million bullet screen comments (BSCs), powering large-scale pre-training. Next, aiming to open-source a strong baseline for follow-up works, we developed the multimodal algorithm that attacks different cinema/TV modelling problems with a unified architecture. Extensive experiments on three cognitive-inspired tasks yielded a number of novel observations (some of them being quite counter-intuition), further validating the value of PTVD in promoting multimodal research. The dataset and codes are released at \url{https://ptvd.github.io/}.
Dual-Gated Fusion with Prefix-Tuning for Multi-Modal Relation Extraction
Jun 19, 2023



Multi-Modal Relation Extraction (MMRE) aims at identifying the relation between two entities in texts that contain visual clues. Rich visual content is valuable for the MMRE task, but existing works cannot well model finer associations among different modalities, failing to capture the truly helpful visual information and thus limiting relation extraction performance. In this paper, we propose a novel MMRE framework to better capture the deeper correlations of text, entity pair, and image/objects, so as to mine more helpful information for the task, termed as DGF-PT. We first propose a prompt-based autoregressive encoder, which builds the associations of intra-modal and inter-modal features related to the task, respectively by entity-oriented and object-oriented prefixes. To better integrate helpful visual information, we design a dual-gated fusion module to distinguish the importance of image/objects and further enrich text representations. In addition, a generative decoder is introduced with entity type restriction on relations, better filtering out candidates. Extensive experiments conducted on the benchmark dataset show that our approach achieves excellent performance compared to strong competitors, even in the few-shot situation.
On the Security Vulnerabilities of Text-to-SQL Models
Nov 28, 2022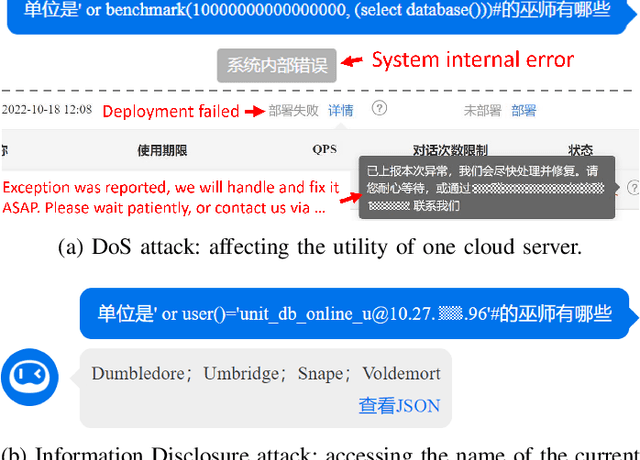


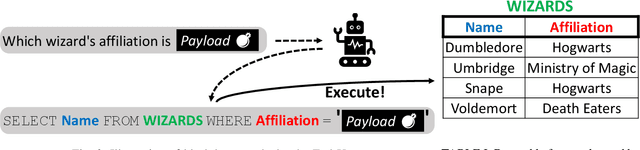
Recent studies show that, despite being effective on numerous tasks, text processing algorithms may be vulnerable to deliberate attacks. However, the question of whether such weaknesses can directly lead to security threats is still under-explored. To bridge this gap, we conducted vulnerability tests on Text-to-SQL, a technique that builds natural language interfaces for databases. Empirically, we showed that the Text-to-SQL modules of two commercial black boxes (Baidu-UNIT and Codex-powered Ai2sql) can be manipulated to produce malicious code, potentially leading to data breaches and Denial of Service. This is the first demonstration of the danger of NLP models being exploited as attack vectors in the wild. Moreover, experiments involving four open-source frameworks verified that simple backdoor attacks can achieve a 100% success rate on Text-to-SQL systems with almost no prediction performance impact. By reporting these findings and suggesting practical defences, we call for immediate attention from the NLP community to the identification and remediation of software security issues.
Generating Disentangled Arguments with Prompts: A Simple Event Extraction Framework that Works
Oct 09, 2021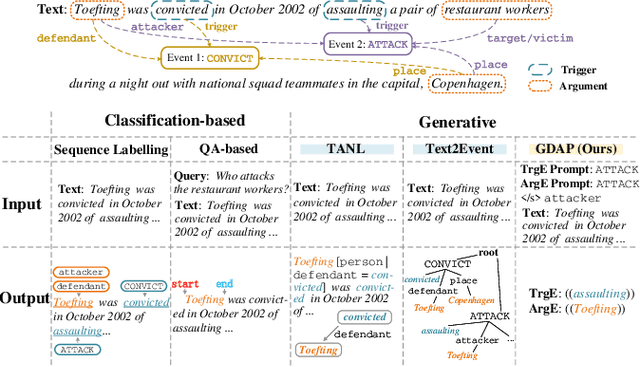
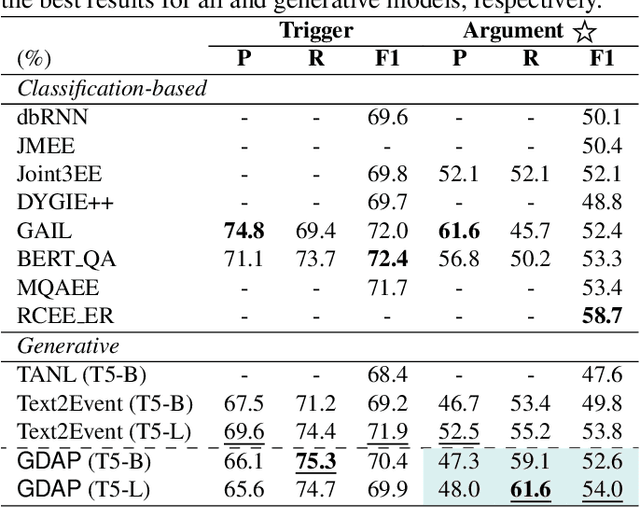
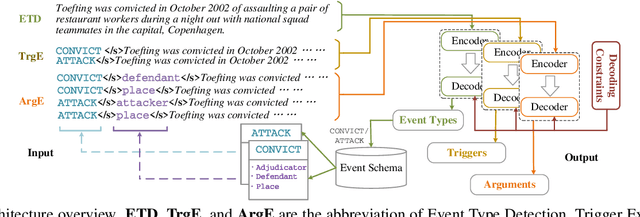
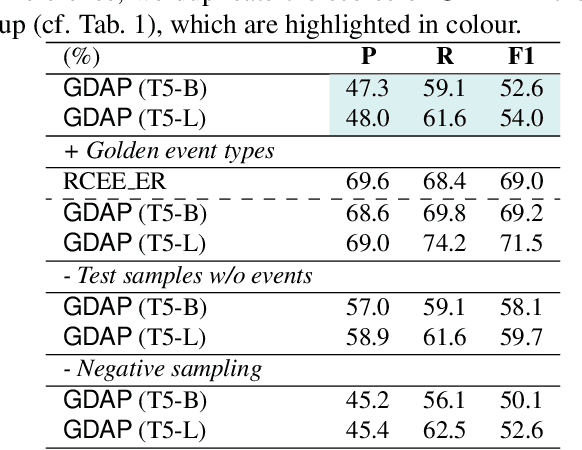
Event Extraction bridges the gap between text and event signals. Based on the assumption of trigger-argument dependency, existing approaches have achieved state-of-the-art performance with expert-designed templates or complicated decoding constraints. In this paper, for the first time we introduce the prompt-based learning strategy to the domain of Event Extraction, which empowers the automatic exploitation of label semantics on both input and output sides. To validate the effectiveness of the proposed generative method, we conduct extensive experiments with 11 diverse baselines. Empirical results show that, in terms of F1 score on Argument Extraction, our simple architecture is stronger than any other generative counterpart and even competitive with algorithms that require template engineering. Regarding the measure of recall, it sets new overall records for both Argument and Trigger Extractions. We hereby recommend this framework to the community, with the code publicly available at https://git.io/GDAP.
On the Latent Holes of VAEs for Text Generation
Oct 07, 2021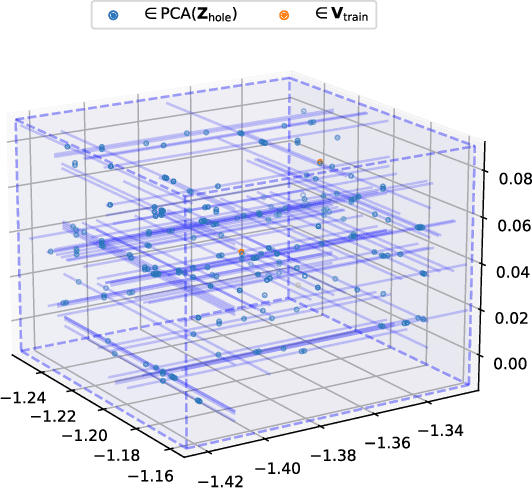

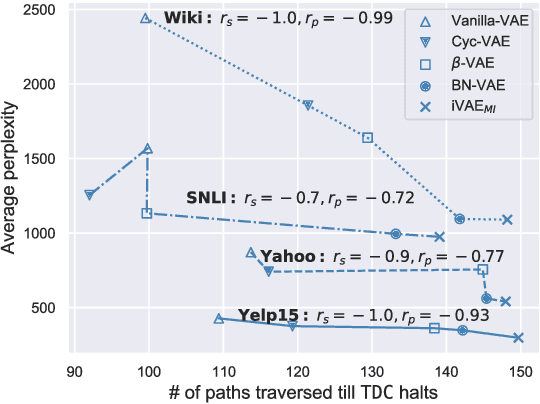

In this paper, we provide the first focused study on the discontinuities (aka. holes) in the latent space of Variational Auto-Encoders (VAEs), a phenomenon which has been shown to have a detrimental effect on model capacity. When investigating latent holes, existing works are exclusively centred around the encoder network and they merely explore the existence of holes. We tackle these limitations by proposing a highly efficient Tree-based Decoder-Centric (TDC) algorithm for latent hole identification, with a focal point on the text domain. In contrast to past studies, our approach pays attention to the decoder network, as a decoder has a direct impact on the model's output quality. Furthermore, we provide, for the first time, in-depth empirical analysis of the latent hole phenomenon, investigating several important aspects such as how the holes impact VAE algorithms' performance on text generation, and how the holes are distributed in the latent space.
Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis
Apr 17, 2021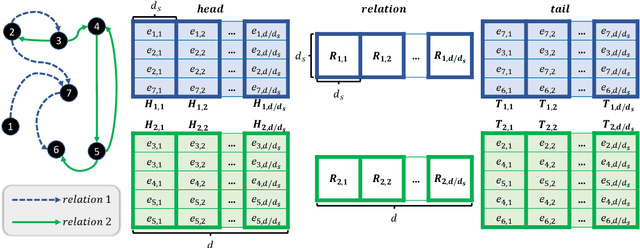
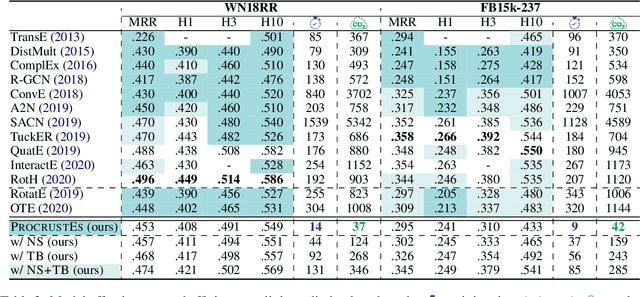
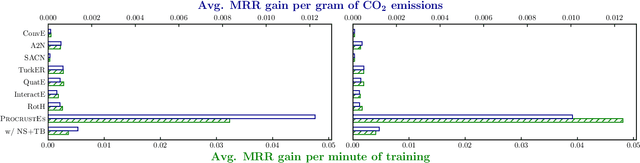
Knowledge Graph Embeddings (KGEs) have been intensively explored in recent years due to their promise for a wide range of applications. However, existing studies focus on improving the final model performance without acknowledging the computational cost of the proposed approaches, in terms of execution time and environmental impact. This paper proposes a simple yet effective KGE framework which can reduce the training time and carbon footprint by orders of magnitudes compared with state-of-the-art approaches, while producing competitive performance. We highlight three technical innovations: full batch learning via relational matrices, closed-form Orthogonal Procrustes Analysis for KGEs, and non-negative-sampling training. In addition, as the first KGE method whose entity embeddings also store full relation information, our trained models encode rich semantics and are highly interpretable. Comprehensive experiments and ablation studies involving 13 strong baselines and two standard datasets verify the effectiveness and efficiency of our algorithm.
Cross-Lingual Word Embedding Refinement by $\ell_{1}$ Norm Optimisation
Apr 11, 2021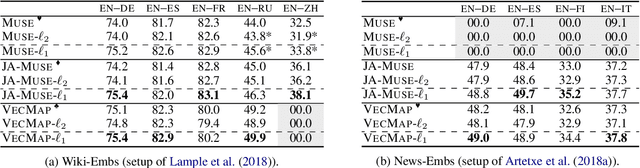


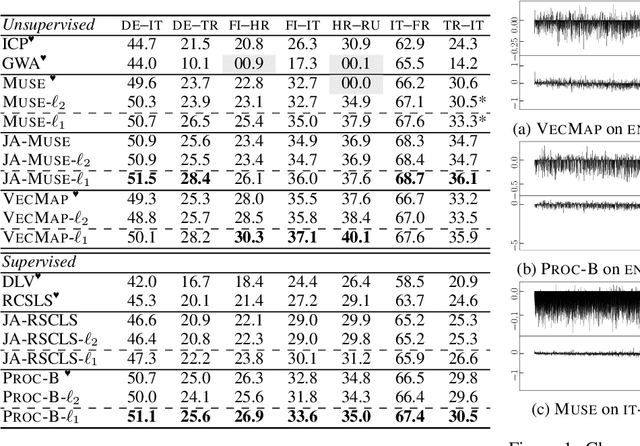
Cross-Lingual Word Embeddings (CLWEs) encode words from two or more languages in a shared high-dimensional space in which vectors representing words with similar meaning (regardless of language) are closely located. Existing methods for building high-quality CLWEs learn mappings that minimise the $\ell_{2}$ norm loss function. However, this optimisation objective has been demonstrated to be sensitive to outliers. Based on the more robust Manhattan norm (aka. $\ell_{1}$ norm) goodness-of-fit criterion, this paper proposes a simple post-processing step to improve CLWEs. An advantage of this approach is that it is fully agnostic to the training process of the original CLWEs and can therefore be applied widely. Extensive experiments are performed involving ten diverse languages and embeddings trained on different corpora. Evaluation results based on bilingual lexicon induction and cross-lingual transfer for natural language inference tasks show that the $\ell_{1}$ refinement substantially outperforms four state-of-the-art baselines in both supervised and unsupervised settings. It is therefore recommended that this strategy be adopted as a standard for CLWE methods.
Summarising Historical Text in Modern Languages
Jan 27, 2021
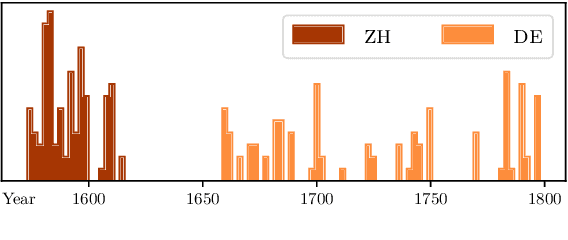
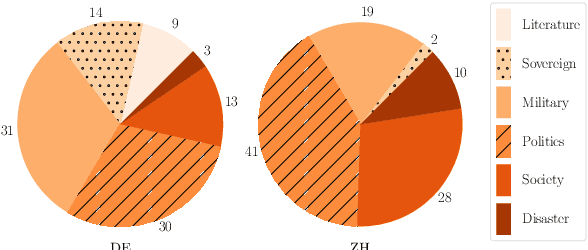
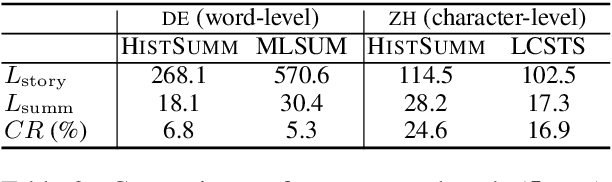
We introduce the task of historical text summarisation, where documents in historical forms of a language are summarised in the corresponding modern language. This is a fundamentally important routine to historians and digital humanities researchers but has never been automated. We compile a high-quality gold-standard text summarisation dataset, which consists of historical German and Chinese news from hundreds of years ago summarised in modern German or Chinese. Based on cross-lingual transfer learning techniques, we propose a summarisation model that can be trained even with no cross-lingual (historical to modern) parallel data, and further benchmark it against state-of-the-art algorithms. We report automatic and human evaluations that distinguish the historic to modern language summarisation task from standard cross-lingual summarisation (i.e., modern to modern language), highlight the distinctness and value of our dataset, and demonstrate that our transfer learning approach outperforms standard cross-lingual benchmarks on this task.
Forming an Electoral College for a Graph: a Heuristic Semi-supervised Learning Framework
Jun 10, 2020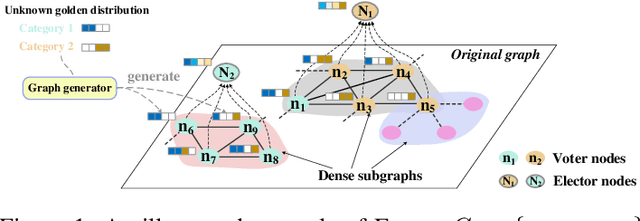

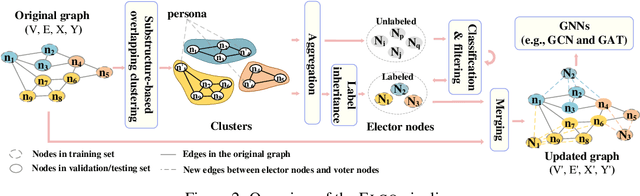
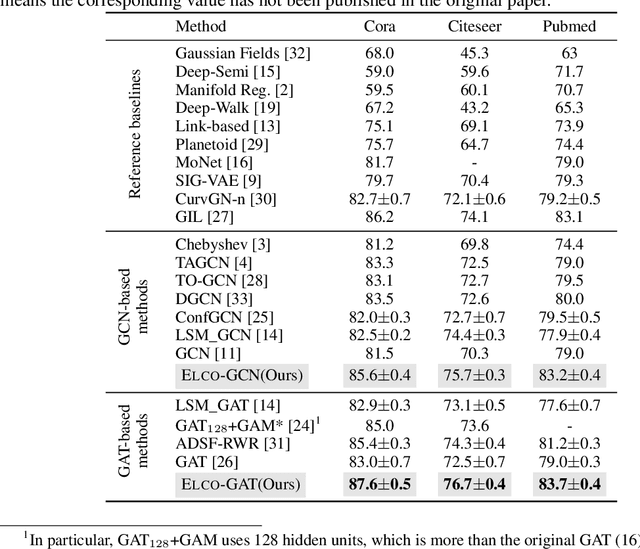
Recently, graph-based algorithms have drawn much attention because of their impressive success in semi-supervised scenarios. For better model performance, previous studies learn to transform the topology of the input graph. However, these works only focus on optimizing the original nodes and edges, leaving the direction of augmenting existing data unexplored. In this paper, by simulating the generation process of graph signals, we propose a novel heuristic pre-processing technique, namely ELectoral COllege (ELCO), which automatically expands new nodes and edges to refine the label similarity within a dense subgraph. Substantially enlarging the original training set with high-quality generated labeled data, our framework can effectively benefit downstream models. To justify the generality and practicality of ELCO, we couple it with the popular Graph Convolution Network and Graph Attention Network to extensively perform semi-supervised learning evaluations on three standard datasets. In all setups tested, our method boosts the average score of base models by a large margin of 4 points, as well as consistently outperforms the state-of-the-art. Please find our code at https://github.com/RingBDStack/ELCO.