 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Multi-Modal Hypergraph Attention Network for Multi-Modal Relation Extraction
Apr 18, 2024
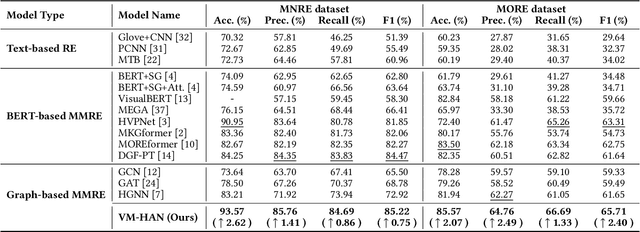
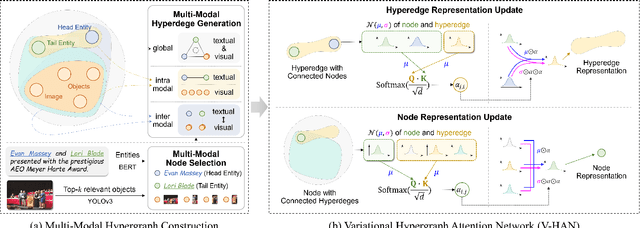
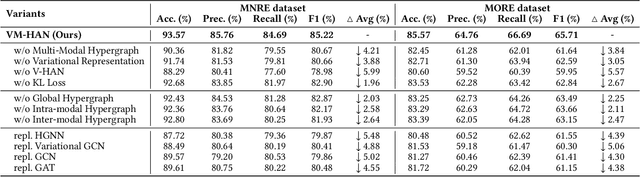
Multi-modal relation extraction (MMRE) is a challenging task that aims to identify relations between entities in text leveraging image information. Existing methods are limited by their neglect of the multiple entity pairs in one sentence sharing very similar contextual information (ie, the same text and image), resulting in increased difficulty in the MMRE task. To address this limitation, we propose the Variational Multi-Modal Hypergraph Attention Network (VM-HAN) for multi-modal relation extraction. Specifically, we first construct a multi-modal hypergraph for each sentence with the corresponding image, to establish different high-order intra-/inter-modal correlations for different entity pairs in each sentence. We further design the Variational Hypergraph Attention Networks (V-HAN) to obtain representational diversity among different entity pairs using Gaussian distribution and learn a better hypergraph structure via variational attention. VM-HAN achieves state-of-the-art performance on the multi-modal relation extraction task, outperforming existing methods in terms of accuracy and efficiency.
Uncertainty-Aware Relational Graph Neural Network for Few-Shot Knowledge Graph Completion
Mar 07, 2024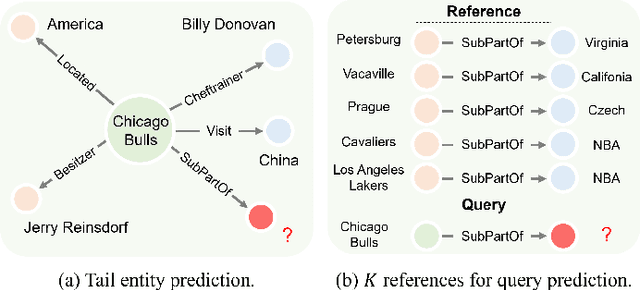
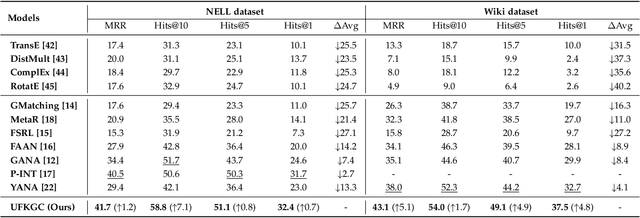
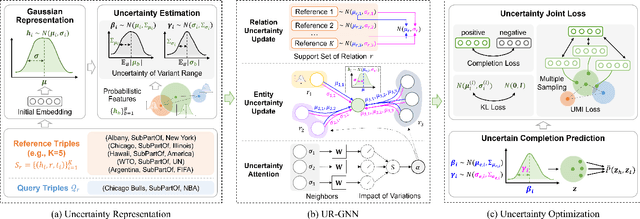
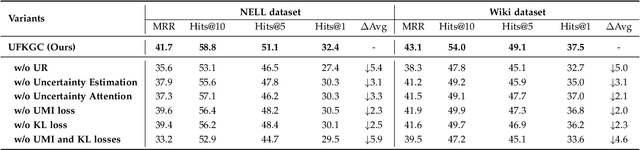
Few-shot knowledge graph completion (FKGC) aims to query the unseen facts of a relation given its few-shot reference entity pairs. The side effect of noises due to the uncertainty of entities and triples may limit the few-shot learning, but existing FKGC works neglect such uncertainty, which leads them more susceptible to limited reference samples with noises. In this paper, we propose a novel uncertainty-aware few-shot KG completion framework (UFKGC) to model uncertainty for a better understanding of the limited data by learning representations under Gaussian distribution. Uncertainty representation is first designed for estimating the uncertainty scope of the entity pairs after transferring feature representations into a Gaussian distribution. Further, to better integrate the neighbors with uncertainty characteristics for entity features, we design an uncertainty-aware relational graph neural network (UR-GNN) to conduct convolution operations between the Gaussian distributions. Then, multiple random samplings are conducted for reference triples within the Gaussian distribution to generate smooth reference representations during the optimization. The final completion score for each query instance is measured by the designed uncertainty optimization to make our approach more robust to the noises in few-shot scenarios. Experimental results show that our approach achieves excellent performance on two benchmark datasets compared to its competitors.
Multi-Modal Knowledge Graph Transformer Framework for Multi-Modal Entity Alignment
Oct 10, 2023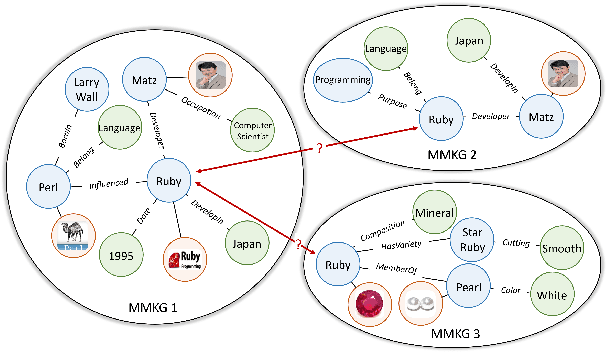
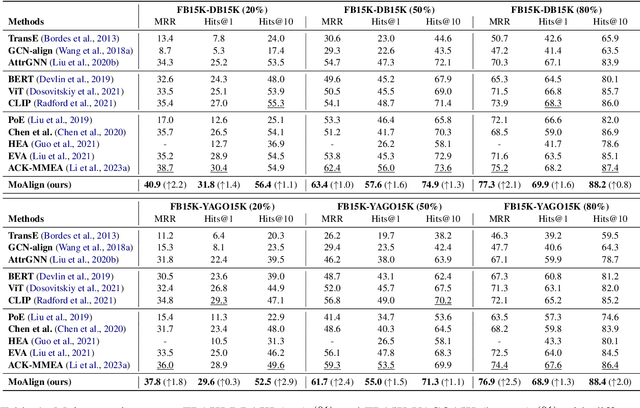
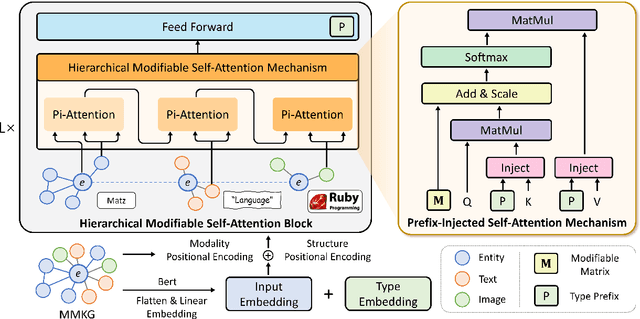
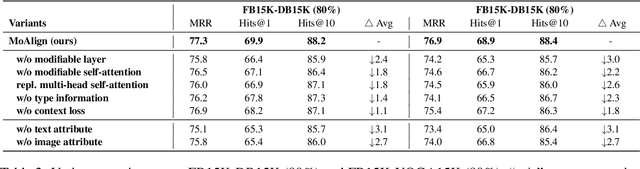
Multi-Modal Entity Alignment (MMEA) is a critical task that aims to identify equivalent entity pairs across multi-modal knowledge graphs (MMKGs). However, this task faces challenges due to the presence of different types of information, including neighboring entities, multi-modal attributes, and entity types. Directly incorporating the above information (e.g., concatenation or attention) can lead to an unaligned information space. To address these challenges, we propose a novel MMEA transformer, called MoAlign, that hierarchically introduces neighbor features, multi-modal attributes, and entity types to enhance the alignment task. Taking advantage of the transformer's ability to better integrate multiple information, we design a hierarchical modifiable self-attention block in a transformer encoder to preserve the unique semantics of different information. Furthermore, we design two entity-type prefix injection methods to integrate entity-type information using type prefixes, which help to restrict the global information of entities not present in the MMKGs. Our extensive experiments on benchmark datasets demonstrate that our approach outperforms strong competitors and achieves excellent entity alignment performance.
Dual-Gated Fusion with Prefix-Tuning for Multi-Modal Relation Extraction
Jun 19, 2023



Multi-Modal Relation Extraction (MMRE) aims at identifying the relation between two entities in texts that contain visual clues. Rich visual content is valuable for the MMRE task, but existing works cannot well model finer associations among different modalities, failing to capture the truly helpful visual information and thus limiting relation extraction performance. In this paper, we propose a novel MMRE framework to better capture the deeper correlations of text, entity pair, and image/objects, so as to mine more helpful information for the task, termed as DGF-PT. We first propose a prompt-based autoregressive encoder, which builds the associations of intra-modal and inter-modal features related to the task, respectively by entity-oriented and object-oriented prefixes. To better integrate helpful visual information, we design a dual-gated fusion module to distinguish the importance of image/objects and further enrich text representations. In addition, a generative decoder is introduced with entity type restriction on relations, better filtering out candidates. Extensive experiments conducted on the benchmark dataset show that our approach achieves excellent performance compared to strong competitors, even in the few-shot situation.
Attribute-Consistent Knowledge Graph Representation Learning for Multi-Modal Entity Alignment
Apr 04, 2023The multi-modal entity alignment (MMEA) aims to find all equivalent entity pairs between multi-modal knowledge graphs (MMKGs). Rich attributes and neighboring entities are valuable for the alignment task, but existing works ignore contextual gap problems that the aligned entities have different numbers of attributes on specific modality when learning entity representations. In this paper, we propose a novel attribute-consistent knowledge graph representation learning framework for MMEA (ACK-MMEA) to compensate the contextual gaps through incorporating consistent alignment knowledge. Attribute-consistent KGs (ACKGs) are first constructed via multi-modal attribute uniformization with merge and generate operators so that each entity has one and only one uniform feature in each modality. The ACKGs are then fed into a relation-aware graph neural network with random dropouts, to obtain aggregated relation representations and robust entity representations. In order to evaluate the ACK-MMEA facilitated for entity alignment, we specially design a joint alignment loss for both entity and attribute evaluation. Extensive experiments conducted on two benchmark datasets show that our approach achieves excellent performance compared to its competitors.
High-Speed Light Focusing through Scattering Medium by Cooperatively Accelerated Genetic Algorithm
Nov 29, 2021

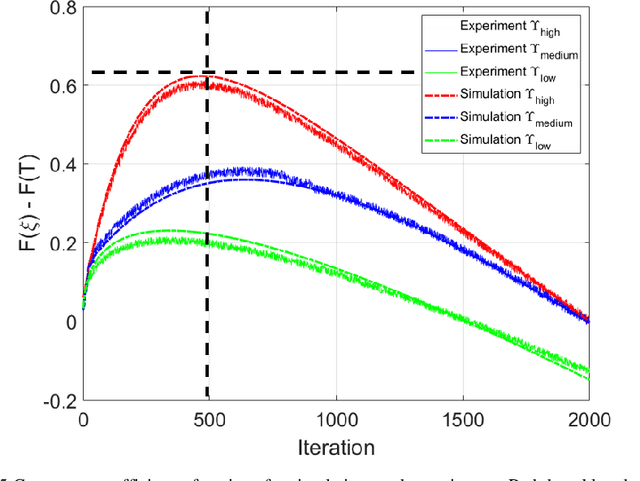

We develop an accelerated Genetic Algorithm (GA) system constructed by the cooperation of field-programmable gate array (FPGA) and optimized parameters of the GA. We found the enhanced decay of mutation rate makes convergence of the GA much faster, enabling the parameter-induced acceleration of the GA. Furthermore, the accelerated configuration of the GA is programmed in FPGA to boost processing speed at the hardware level without external computation devices. This system has ability to focus light through scattering medium within 4 seconds with robust noise resistance and stable repetition performance, which could be further reduced to millisecond level with advanced board configuration. This study solves the long-term limitation of the GA, it promotes the applications of the GA in dynamic scattering mediums, with the capability to tackle wavefront shaping in biological material.
Event Extraction by Associating Event Types and Argument Roles
Aug 23, 2021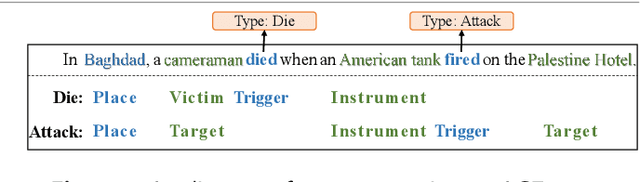

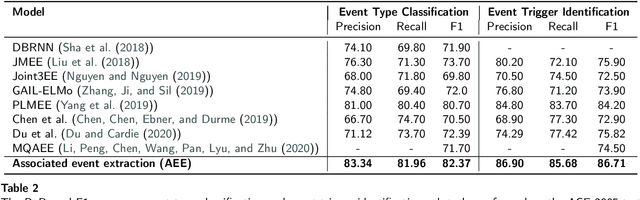
Event extraction (EE), which acquires structural event knowledge from texts, can be divided into two sub-tasks: event type classification and element extraction (namely identifying triggers and arguments under different role patterns). As different event types always own distinct extraction schemas (i.e., role patterns), previous work on EE usually follows an isolated learning paradigm, performing element extraction independently for different event types. It ignores meaningful associations among event types and argument roles, leading to relatively poor performance for less frequent types/roles. This paper proposes a novel neural association framework for the EE task. Given a document, it first performs type classification via constructing a document-level graph to associate sentence nodes of different types, and adopting a graph attention network to learn sentence embeddings. Then, element extraction is achieved by building a universal schema of argument roles, with a parameter inheritance mechanism to enhance role preference for extracted elements. As such, our model takes into account type and role associations during EE, enabling implicit information sharing among them. Experimental results show that our approach consistently outperforms most state-of-the-art EE methods in both sub-tasks. Particularly, for types/roles with less training data, the performance is superior to the existing methods.
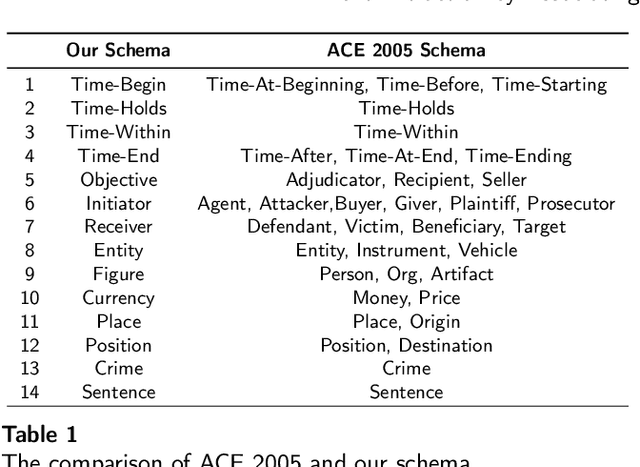
Deep Learning Schema-based Event Extraction: Literature Review and Current Trends
Jul 22, 2021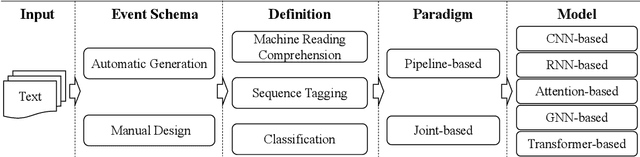



Schema-based event extraction is a critical technique to apprehend the essential content of events promptly. With the rapid development of deep learning technology, event extraction technology based on deep learning has become a research hotspot. Numerous methods, datasets, and evaluation metrics have been proposed in the literature, raising the need for a comprehensive and updated survey. This paper fills the gap by reviewing the state-of-the-art approaches, focusing on deep learning-based models. We summarize the task definition, paradigm, and models of schema-based event extraction and then discuss each of these in detail. We introduce benchmark datasets that support tests of predictions and evaluation metrics. A comprehensive comparison between different techniques is also provided in this survey. Finally, we conclude by summarizing future research directions facing the research area.
Deep Structural Point Process for Learning Temporal Interaction Networks
Jul 08, 2021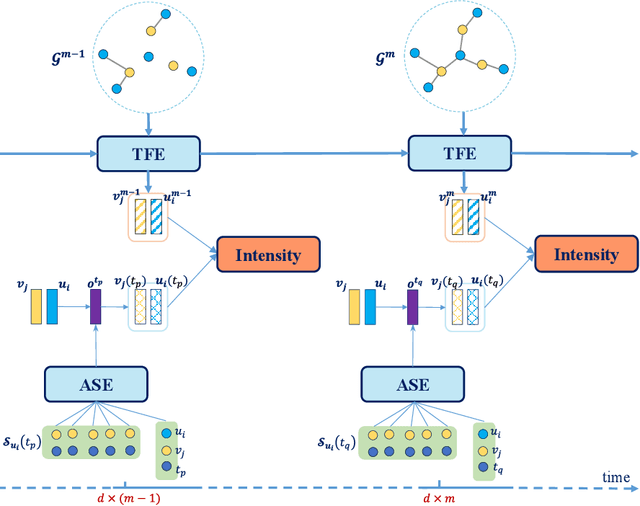

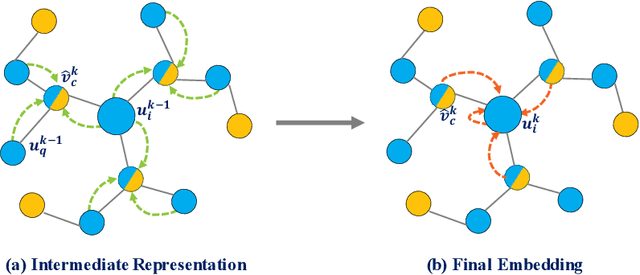
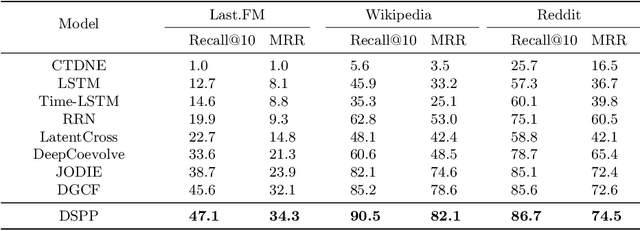
This work investigates the problem of learning temporal interaction networks. A temporal interaction network consists of a series of chronological interactions between users and items. Previous methods tackle this problem by using different variants of recurrent neural networks to model sequential interactions, which fail to consider the structural information of temporal interaction networks and inevitably lead to sub-optimal results. To this end, we propose a novel Deep Structural Point Process termed as DSPP for learning temporal interaction networks. DSPP simultaneously incorporates the topological structure and long-range dependency structure into our intensity function to enhance model expressiveness. To be specific, by using the topological structure as a strong prior, we first design a topological fusion encoder to obtain node embeddings. An attentive shift encoder is then developed to learn the long-range dependency structure between users and items in continuous time. The proposed two modules enable our model to capture the user-item correlation and dynamic influence in temporal interaction networks. DSPP is evaluated on three real-world datasets for both tasks of item prediction and time prediction. Extensive experiments demonstrate that our model achieves consistent and significant improvements over state-of-the-art baselines.
CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction
Jul 04, 2021

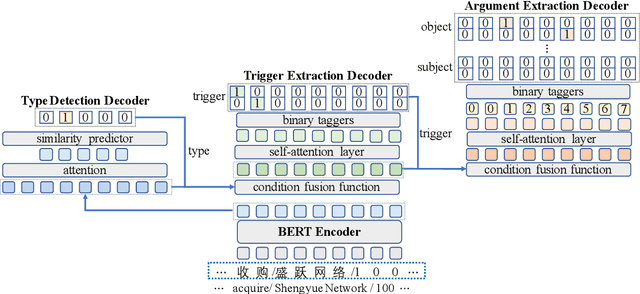
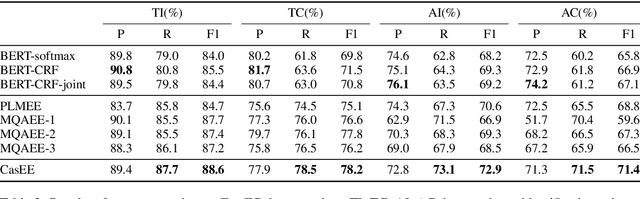
Event extraction (EE) is a crucial information extraction task that aims to extract event information in texts. Most existing methods assume that events appear in sentences without overlaps, which are not applicable to the complicated overlapping event extraction. This work systematically studies the realistic event overlapping problem, where a word may serve as triggers with several types or arguments with different roles. To tackle the above problem, we propose a novel joint learning framework with cascade decoding for overlapping event extraction, termed as CasEE. Particularly, CasEE sequentially performs type detection, trigger extraction and argument extraction, where the overlapped targets are extracted separately conditioned on the specific former prediction. All the subtasks are jointly learned in a framework to capture dependencies among the subtasks. The evaluation on a public event extraction benchmark FewFC demonstrates that CasEE achieves significant improvements on overlapping event extraction over previous competitive methods.