 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Preference-Guided Diffusion Model for Cross-Domain Recommendation
Jan 20, 2025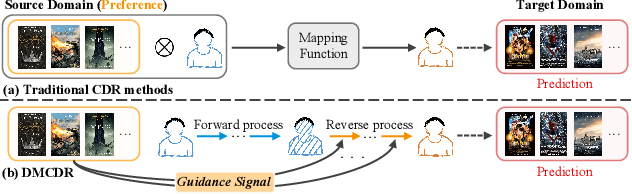
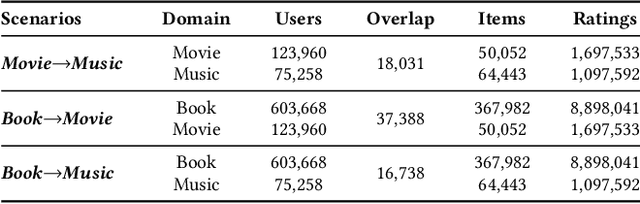
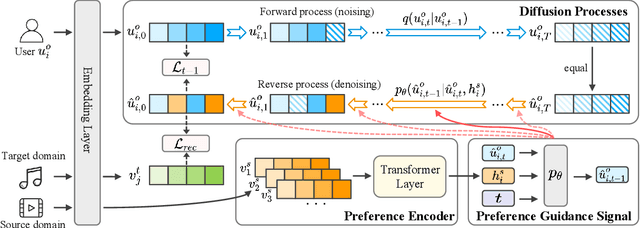
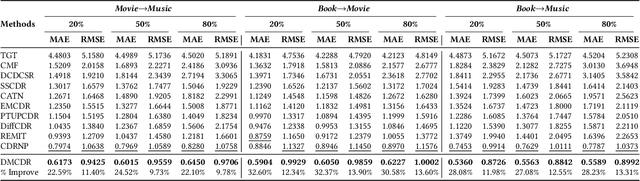
Cross-domain recommendation (CDR) has been proven as a promising way to alleviate the cold-start issue, in which the most critical problem is how to draw an informative user representation in the target domain via the transfer of user preference existing in the source domain. Prior efforts mostly follow the embedding-and-mapping paradigm, which first integrate the preference into user representation in the source domain, and then perform a mapping function on this representation to the target domain. However, they focus on mapping features across domains, neglecting to explicitly model the preference integration process, which may lead to learning coarse user representation. Diffusion models (DMs), which contribute to more accurate user/item representations due to their explicit information injection capability, have achieved promising performance in recommendation systems. Nevertheless, these DMs-based methods cannot directly account for valuable user preference in other domains, leading to challenges in adapting to the transfer of preference for cold-start users. Consequently, the feasibility of DMs for CDR remains underexplored. To this end, we explore to utilize the explicit information injection capability of DMs for user preference integration and propose a Preference-Guided Diffusion Model for CDR to cold-start users, termed as DMCDR. Specifically, we leverage a preference encoder to establish the preference guidance signal with the user's interaction history in the source domain. Then, we explicitly inject the preference guidance signal into the user representation step by step to guide the reverse process, and ultimately generate the personalized user representation in the target domain, thus achieving the transfer of user preference across domains. Furthermore, we comprehensively explore the impact of six DMs-based variants on CDR.
Text-Video Retrieval via Variational Multi-Modal Hypergraph Networks
Jan 06, 2024Text-video retrieval is a challenging task that aims to identify relevant videos given textual queries. Compared to conventional textual retrieval, the main obstacle for text-video retrieval is the semantic gap between the textual nature of queries and the visual richness of video content. Previous works primarily focus on aligning the query and the video by finely aggregating word-frame matching signals. Inspired by the human cognitive process of modularly judging the relevance between text and video, the judgment needs high-order matching signal due to the consecutive and complex nature of video contents. In this paper, we propose chunk-level text-video matching, where the query chunks are extracted to describe a specific retrieval unit, and the video chunks are segmented into distinct clips from videos. We formulate the chunk-level matching as n-ary correlations modeling between words of the query and frames of the video and introduce a multi-modal hypergraph for n-ary correlation modeling. By representing textual units and video frames as nodes and using hyperedges to depict their relationships, a multi-modal hypergraph is constructed. In this way, the query and the video can be aligned in a high-order semantic space. In addition, to enhance the model's generalization ability, the extracted features are fed into a variational inference component for computation, obtaining the variational representation under the Gaussian distribution. The incorporation of hypergraphs and variational inference allows our model to capture complex, n-ary interactions among textual and visual contents. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on the text-video retrieval task.
Deep Structural Point Process for Learning Temporal Interaction Networks
Jul 08, 2021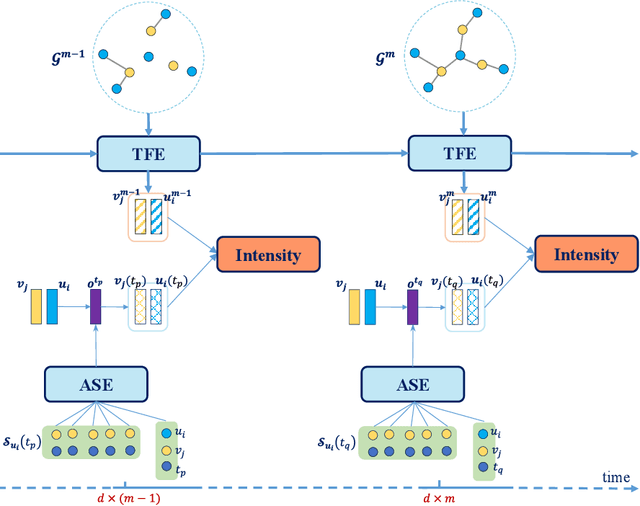

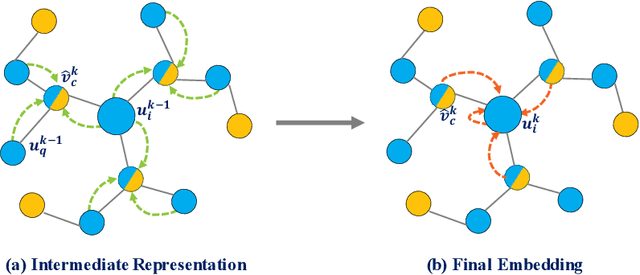
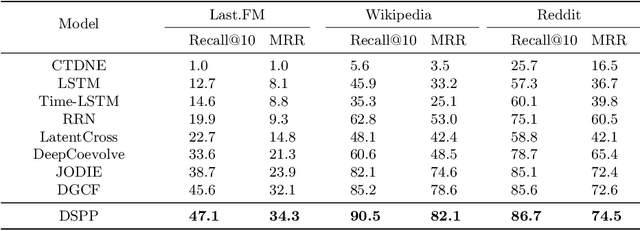
This work investigates the problem of learning temporal interaction networks. A temporal interaction network consists of a series of chronological interactions between users and items. Previous methods tackle this problem by using different variants of recurrent neural networks to model sequential interactions, which fail to consider the structural information of temporal interaction networks and inevitably lead to sub-optimal results. To this end, we propose a novel Deep Structural Point Process termed as DSPP for learning temporal interaction networks. DSPP simultaneously incorporates the topological structure and long-range dependency structure into our intensity function to enhance model expressiveness. To be specific, by using the topological structure as a strong prior, we first design a topological fusion encoder to obtain node embeddings. An attentive shift encoder is then developed to learn the long-range dependency structure between users and items in continuous time. The proposed two modules enable our model to capture the user-item correlation and dynamic influence in temporal interaction networks. DSPP is evaluated on three real-world datasets for both tasks of item prediction and time prediction. Extensive experiments demonstrate that our model achieves consistent and significant improvements over state-of-the-art baselines.
Inductive Unsupervised Domain Adaptation for Few-Shot Classification via Clustering
Jun 23, 2020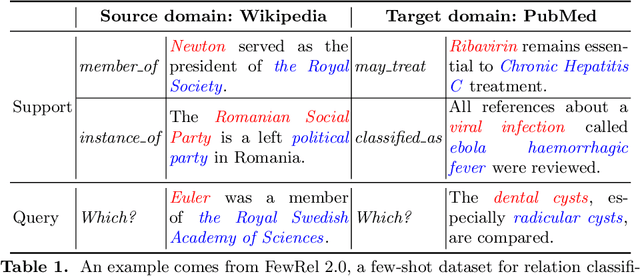
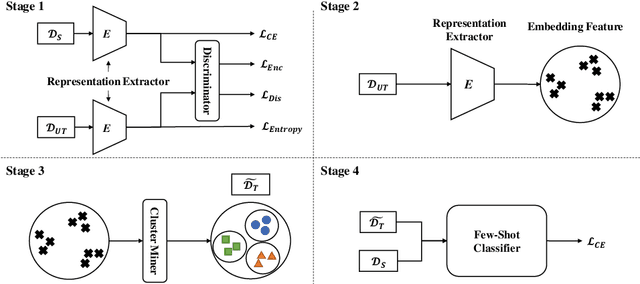
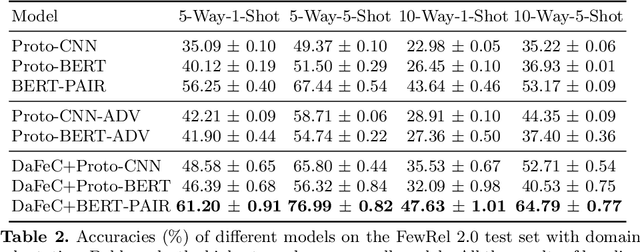
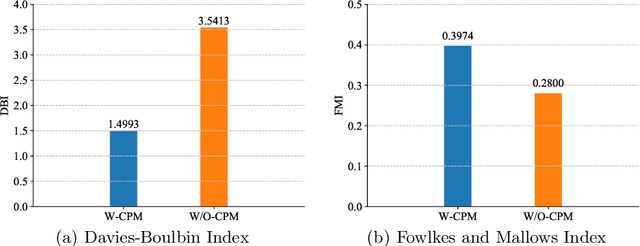
Few-shot classification tends to struggle when it needs to adapt to diverse domains. Due to the non-overlapping label space between domains, the performance of conventional domain adaptation is limited. Previous work tackles the problem in a transductive manner, by assuming access to the full set of test data, which is too restrictive for many real-world applications. In this paper, we set out to tackle this issue by introducing a inductive framework, DaFeC, to improve Domain adaptation performance for Few-shot classification via Clustering. We first build a representation extractor to derive features for unlabeled data from the target domain (no test data is necessary) and then group them with a cluster miner. The generated pseudo-labeled data and the labeled source-domain data are used as supervision to update the parameters of the few-shot classifier. In order to derive high-quality pseudo labels, we propose a Clustering Promotion Mechanism, to learn better features for the target domain via Similarity Entropy Minimization and Adversarial Distribution Alignment, which are combined with a Cosine Annealing Strategy. Experiments are performed on the FewRel 2.0 dataset. Our approach outperforms previous work with absolute gains (in classification accuracy) of 4.95%, 9.55%, 3.99% and 11.62%, respectively, under four few-shot settings.
HIN: Hierarchical Inference Network for Document-Level Relation Extraction
Mar 28, 2020
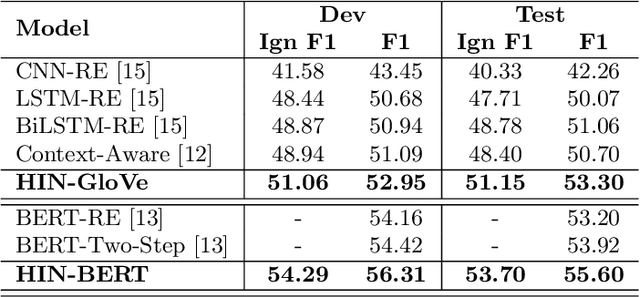
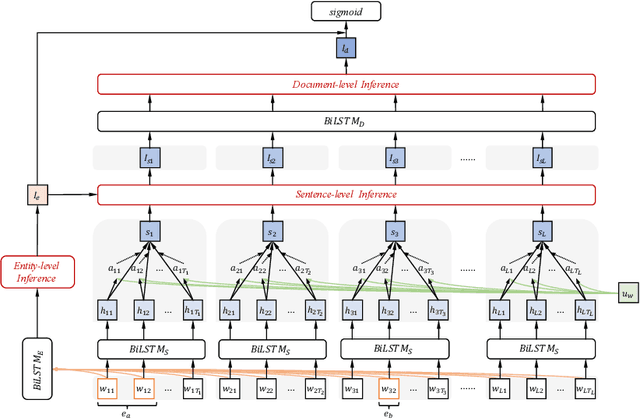
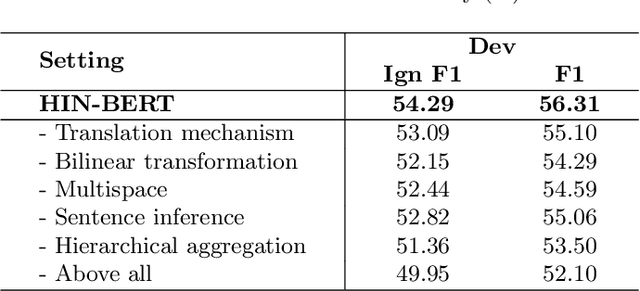
Document-level RE requires reading, inferring and aggregating over multiple sentences. From our point of view, it is necessary for document-level RE to take advantage of multi-granularity inference information: entity level, sentence level and document level. Thus, how to obtain and aggregate the inference information with different granularity is challenging for document-level RE, which has not been considered by previous work. In this paper, we propose a Hierarchical Inference Network (HIN) to make full use of the abundant information from entity level, sentence level and document level. Translation constraint and bilinear transformation are applied to target entity pair in multiple subspaces to get entity-level inference information. Next, we model the inference between entity-level information and sentence representation to achieve sentence-level inference information. Finally, a hierarchical aggregation approach is adopted to obtain the document-level inference information. In this way, our model can effectively aggregate inference information from these three different granularities. Experimental results show that our method achieves state-of-the-art performance on the large-scale DocRED dataset. We also demonstrate that using BERT representations can further substantially boost the performance.