 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldCup Sampling for Multi-bit LLM Watermarking
Feb 02, 2026As large language models (LLMs) generate increasingly human-like text, watermarking offers a promising solution for reliable attribution beyond mere detection. While multi-bit watermarking enables richer provenance encoding, existing methods largely extend zero-bit schemes through seed-driven steering, leading to indirect information flow, limited effective capacity, and suboptimal decoding. In this paper, we propose WorldCup, a multi-bit watermarking framework for LLMs that treats sampling as a natural communication channel and embeds message bits directly into token selection via a hierarchical competition mechanism guided by complementary signals. Moreover, WorldCup further adopts entropy-aware modulation to preserve generation quality and supports robust message recovery through confidence-aware decoding. Comprehensive experiments show that WorldCup achieves a strong balance across capacity, detectability, robustness, text quality, and decoding efficiency, consistently outperforming prior baselines and laying a solid foundation for future LLM watermarking studies.
MuVaC: AVariational Causal Framework for Multimodal Sarcasm Understanding in Dialogues
Jan 28, 2026The prevalence of sarcasm in multimodal dialogues on the social platforms presents a crucial yet challenging task for understanding the true intent behind online content. Comprehensive sarcasm analysis requires two key aspects: Multimodal Sarcasm Detection (MSD) and Multimodal Sarcasm Explanation (MuSE). Intuitively, the act of detection is the result of the reasoning process that explains the sarcasm. Current research predominantly focuses on addressing either MSD or MuSE as a single task. Even though some recent work has attempted to integrate these tasks, their inherent causal dependency is often overlooked. To bridge this gap, we propose MuVaC, a variational causal inference framework that mimics human cognitive mechanisms for understanding sarcasm, enabling robust multimodal feature learning to jointly optimize MSD and MuSE. Specifically, we first model MSD and MuSE from the perspective of structural causal models, establishing variational causal pathways to define the objectives for joint optimization. Next, we design an alignment-then-fusion approach to integrate multimodal features, providing robust fusion representations for sarcasm detection and explanation generation. Finally, we enhance the reasoning trustworthiness by ensuring consistency between detection results and explanations. Experimental results demonstrate the superiority of MuVaC in public datasets, offering a new perspective for understanding multimodal sarcasm.
Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
DualGuard: Dual-stream Large Language Model Watermarking Defense against Paraphrase and Spoofing Attack
Dec 18, 2025With the rapid development of cloud-based services, large language models (LLMs) have become increasingly accessible through various web platforms. However, this accessibility has also led to growing risks of model abuse. LLM watermarking has emerged as an effective approach to mitigate such misuse and protect intellectual property. Existing watermarking algorithms, however, primarily focus on defending against paraphrase attacks while overlooking piggyback spoofing attacks, which can inject harmful content, compromise watermark reliability, and undermine trust in attribution. To address this limitation, we propose DualGuard, the first watermarking algorithm capable of defending against both paraphrase and spoofing attacks. DualGuard employs the adaptive dual-stream watermarking mechanism, in which two complementary watermark signals are dynamically injected based on the semantic content. This design enables DualGuard not only to detect but also to trace spoofing attacks, thereby ensuring reliable and trustworthy watermark detection. Extensive experiments conducted across multiple datasets and language models demonstrate that DualGuard achieves excellent detectability, robustness, traceability, and text quality, effectively advancing the state of LLM watermarking for real-world applications.
From Essence to Defense: Adaptive Semantic-aware Watermarking for Embedding-as-a-Service Copyright Protection
Dec 18, 2025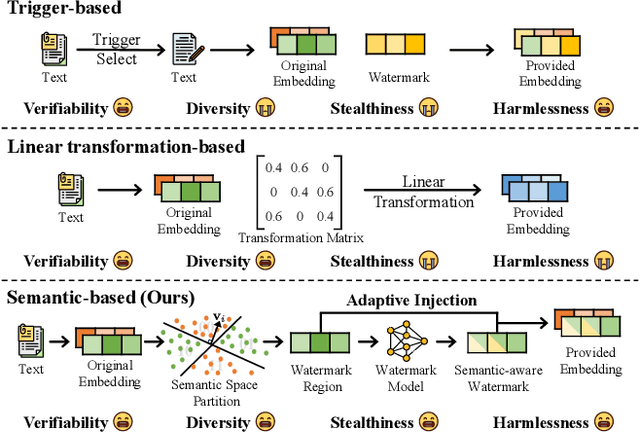



Benefiting from the superior capabilities of large language models in natural language understanding and generation, Embeddings-as-a-Service (EaaS) has emerged as a successful commercial paradigm on the web platform. However, prior studies have revealed that EaaS is vulnerable to imitation attacks. Existing methods protect the intellectual property of EaaS through watermarking techniques, but they all ignore the most important properties of embedding: semantics, resulting in limited harmlessness and stealthiness. To this end, we propose SemMark, a novel semantic-based watermarking paradigm for EaaS copyright protection. SemMark employs locality-sensitive hashing to partition the semantic space and inject semantic-aware watermarks into specific regions, ensuring that the watermark signals remain imperceptible and diverse. In addition, we introduce the adaptive watermark weight mechanism based on the local outlier factor to preserve the original embedding distribution. Furthermore, we propose Detect-Sampling and Dimensionality-Reduction attacks and construct four scenarios to evaluate the watermarking method. Extensive experiments are conducted on four popular NLP datasets, and SemMark achieves superior verifiability, diversity, stealthiness, and harmlessness.
PathMind: A Retrieve-Prioritize-Reason Framework for Knowledge Graph Reasoning with Large Language Models
Nov 18, 2025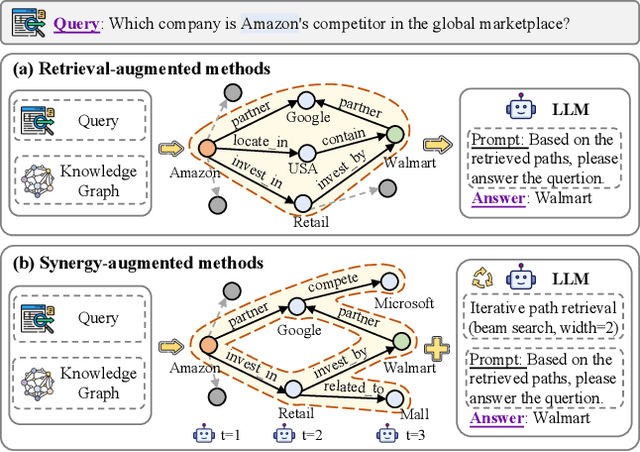
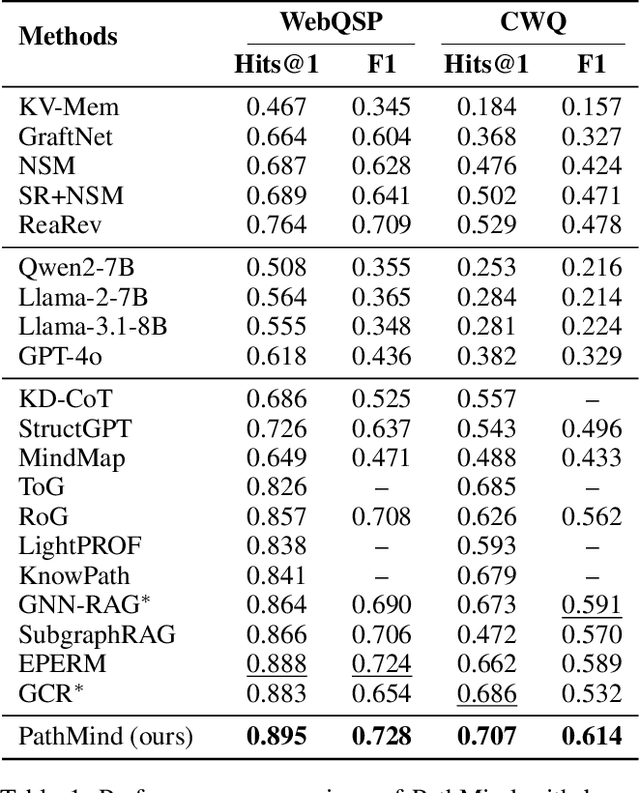
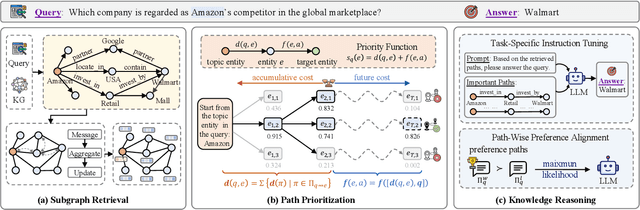
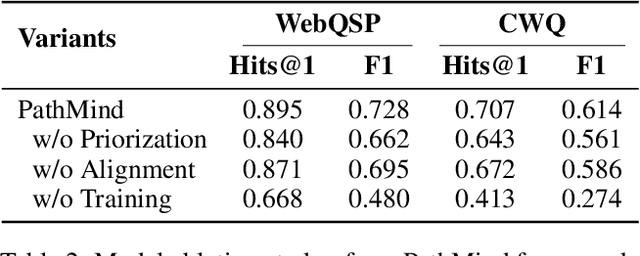
Knowledge graph reasoning (KGR) is the task of inferring new knowledge by performing logical deductions on knowledge graphs. Recently, large language models (LLMs) have demonstrated remarkable performance in complex reasoning tasks. Despite promising success, current LLM-based KGR methods still face two critical limitations. First, existing methods often extract reasoning paths indiscriminately, without assessing their different importance, which may introduce irrelevant noise that misleads LLMs. Second, while many methods leverage LLMs to dynamically explore potential reasoning paths, they require high retrieval demands and frequent LLM calls. To address these limitations, we propose PathMind, a novel framework designed to enhance faithful and interpretable reasoning by selectively guiding LLMs with important reasoning paths. Specifically, PathMind follows a "Retrieve-Prioritize-Reason" paradigm. First, it retrieves a query subgraph from KG through the retrieval module. Next, it introduces a path prioritization mechanism that identifies important reasoning paths using a semantic-aware path priority function, which simultaneously considers the accumulative cost and the estimated future cost for reaching the target. Finally, PathMind generates accurate and logically consistent responses via a dual-phase training strategy, including task-specific instruction tuning and path-wise preference alignment. Extensive experiments on benchmark datasets demonstrate that PathMind consistently outperforms competitive baselines, particularly on complex reasoning tasks with fewer input tokens, by identifying essential reasoning paths.
MetaGDPO: Alleviating Catastrophic Forgetting with Metacognitive Knowledge through Group Direct Preference Optimization
Nov 15, 2025Large Language Models demonstrate strong reasoning capabilities, which can be effectively compressed into smaller models. However, existing datasets and fine-tuning approaches still face challenges that lead to catastrophic forgetting, particularly for models smaller than 8B. First, most datasets typically ignore the relationship between training data knowledge and the model's inherent abilities, making it difficult to preserve prior knowledge. Second, conventional training objectives often fail to constrain inherent knowledge preservation, which can result in forgetting of previously learned skills. To address these issues, we propose a comprehensive solution that alleviates catastrophic forgetting from both the data and fine-tuning approach perspectives. On the data side, we construct a dataset of 5K instances that covers multiple reasoning tasks and incorporates metacognitive knowledge, making it more tolerant and effective for distillation into smaller models. We annotate the metacognitive knowledge required to solve each question and filter the data based on task knowledge and the model's inherent skills. On the training side, we introduce GDPO (Group Direction Preference Optimization), which is better suited for resource-limited scenarios and can efficiently approximate the performance of GRPO. Guided by the large model and by implicitly constraining the optimization path through a reference model, GDPO enables more effective knowledge transfer from the large model and constrains excessive parameter drift. Extensive experiments demonstrate that our approach significantly alleviates catastrophic forgetting and improves reasoning performance on smaller models.
MAD-Fact: A Multi-Agent Debate Framework for Long-Form Factuality Evaluation in LLMs
Oct 27, 2025The widespread adoption of Large Language Models (LLMs) raises critical concerns about the factual accuracy of their outputs, especially in high-risk domains such as biomedicine, law, and education. Existing evaluation methods for short texts often fail on long-form content due to complex reasoning chains, intertwined perspectives, and cumulative information. To address this, we propose a systematic approach integrating large-scale long-form datasets, multi-agent verification mechanisms, and weighted evaluation metrics. We construct LongHalluQA, a Chinese long-form factuality dataset; and develop MAD-Fact, a debate-based multi-agent verification system. We introduce a fact importance hierarchy to capture the varying significance of claims in long-form texts. Experiments on two benchmarks show that larger LLMs generally maintain higher factual consistency, while domestic models excel on Chinese content. Our work provides a structured framework for evaluating and enhancing factual reliability in long-form LLM outputs, guiding their safe deployment in sensitive domains.
DNA-DetectLLM: Unveiling AI-Generated Text via a DNA-Inspired Mutation-Repair Paradigm
Sep 19, 2025The rapid advancement of large language models (LLMs) has blurred the line between AI-generated and human-written text. This progress brings societal risks such as misinformation, authorship ambiguity, and intellectual property concerns, highlighting the urgent need for reliable AI-generated text detection methods. However, recent advances in generative language modeling have resulted in significant overlap between the feature distributions of human-written and AI-generated text, blurring classification boundaries and making accurate detection increasingly challenging. To address the above challenges, we propose a DNA-inspired perspective, leveraging a repair-based process to directly and interpretably capture the intrinsic differences between human-written and AI-generated text. Building on this perspective, we introduce DNA-DetectLLM, a zero-shot detection method for distinguishing AI-generated and human-written text. The method constructs an ideal AI-generated sequence for each input, iteratively repairs non-optimal tokens, and quantifies the cumulative repair effort as an interpretable detection signal. Empirical evaluations demonstrate that our method achieves state-of-the-art detection performance and exhibits strong robustness against various adversarial attacks and input lengths. Specifically, DNA-DetectLLM achieves relative improvements of 5.55% in AUROC and 2.08% in F1 score across multiple public benchmark datasets.
RANA: Robust Active Learning for Noisy Network Alignment
Jul 30, 2025Network alignment has attracted widespread attention in various fields. However, most existing works mainly focus on the problem of label sparsity, while overlooking the issue of noise in network alignment, which can substantially undermine model performance. Such noise mainly includes structural noise from noisy edges and labeling noise caused by human-induced and process-driven errors. To address these problems, we propose RANA, a Robust Active learning framework for noisy Network Alignment. RANA effectively tackles both structure noise and label noise while addressing the sparsity of anchor link annotations, which can improve the robustness of network alignment models. Specifically, RANA introduces the proposed Noise-aware Selection Module and the Label Denoising Module to address structural noise and labeling noise, respectively. In the first module, we design a noise-aware maximization objective to select node pairs, incorporating a cleanliness score to address structural noise. In the second module, we propose a novel multi-source fusion denoising strategy that leverages model and twin node pairs labeling to provide more accurate labels for node pairs. Empirical results on three real-world datasets demonstrate that RANA outperforms state-of-the-art active learning-based methods in alignment accuracy. Our code is available at https://github.com/YXNan0110/RANA.